 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideo In Sentences Out
Aug 09, 2014
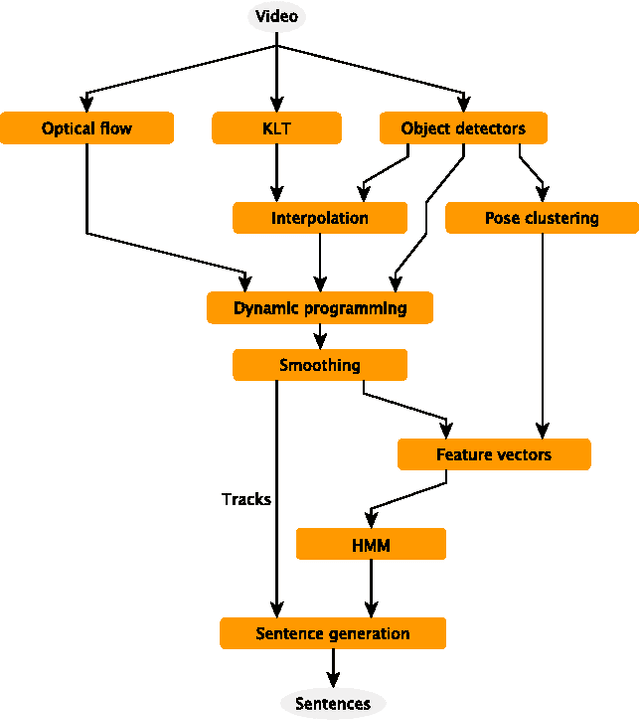


We present a system that produces sentential descriptions of video: who did what to whom, and where and how they did it. Action class is rendered as a verb, participant objects as noun phrases, properties of those objects as adjectival modifiers in those noun phrases, spatial relations between those participants as prepositional phrases, and characteristics of the event as prepositional-phrase adjuncts and adverbial modifiers. Extracting the information needed to render these linguistic entities requires an approach to event recognition that recovers object tracks, the trackto-role assignments, and changing body posture.
Simultaneous Object Detection, Tracking, and Event Recognition
Apr 12, 2012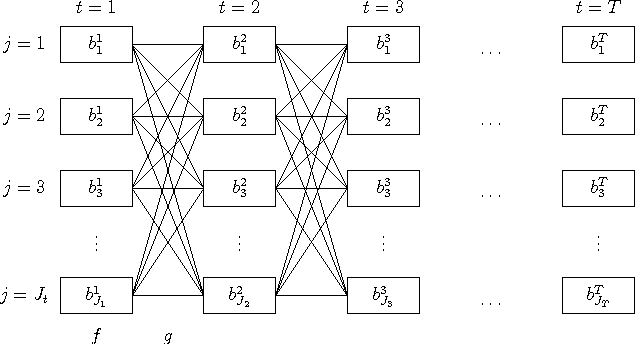



The common internal structure and algorithmic organization of object detection, detection-based tracking, and event recognition facilitates a general approach to integrating these three components. This supports multidirectional information flow between these components allowing object detection to influence tracking and event recognition and event recognition to influence tracking and object detection. The performance of the combination can exceed the performance of the components in isolation. This can be done with linear asymptotic complexity.