 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeiNeMo: Incremental Neural Mesh Models for Robust Class-Incremental Learning
Jul 12, 2024Different from human nature, it is still common practice today for vision tasks to train deep learning models only initially and on fixed datasets. A variety of approaches have recently addressed handling continual data streams. However, extending these methods to manage out-of-distribution (OOD) scenarios has not effectively been investigated. On the other hand, it has recently been shown that non-continual neural mesh models exhibit strong performance in generalizing to such OOD scenarios. To leverage this decisive property in a continual learning setting, we propose incremental neural mesh models that can be extended with new meshes over time. In addition, we present a latent space initialization strategy that enables us to allocate feature space for future unseen classes in advance and a positional regularization term that forces the features of the different classes to consistently stay in respective latent space regions. We demonstrate the effectiveness of our method through extensive experiments on the Pascal3D and ObjectNet3D datasets and show that our approach outperforms the baselines for classification by $2-6\%$ in the in-domain and by $6-50\%$ in the OOD setting. Our work also presents the first incremental learning approach for pose estimation. Our code and model can be found at https://github.com/Fischer-Tom/iNeMo.
Neuroexplicit Diffusion Models for Inpainting of Optical Flow Fields
May 23, 2024Deep learning has revolutionized the field of computer vision by introducing large scale neural networks with millions of parameters. Training these networks requires massive datasets and leads to intransparent models that can fail to generalize. At the other extreme, models designed from partial differential equations (PDEs) embed specialized domain knowledge into mathematical equations and usually rely on few manually chosen hyperparameters. This makes them transparent by construction and if designed and calibrated carefully, they can generalize well to unseen scenarios. In this paper, we show how to bring model- and data-driven approaches together by combining the explicit PDE-based approaches with convolutional neural networks to obtain the best of both worlds. We illustrate a joint architecture for the task of inpainting optical flow fields and show that the combination of model- and data-driven modeling leads to an effective architecture. Our model outperforms both fully explicit and fully data-driven baselines in terms of reconstruction quality, robustness and amount of required training data. Averaging the endpoint error across different mask densities, our method outperforms the explicit baselines by 11-27%, the GAN baseline by 47% and the Probabilisitic Diffusion baseline by 42%. With that, our method sets a new state of the art for inpainting of optical flow fields from random masks.
Object Detection and Classification in Occupancy Grid Maps using Deep Convolutional Networks
Dec 05, 2018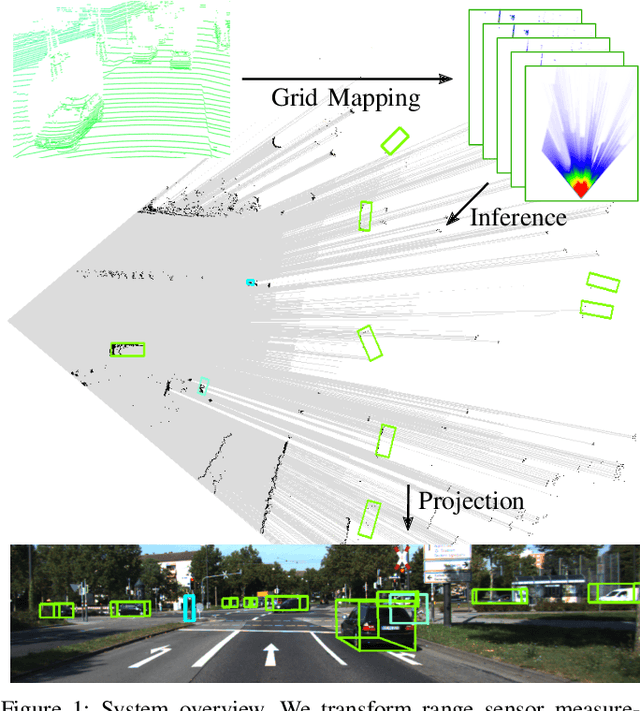
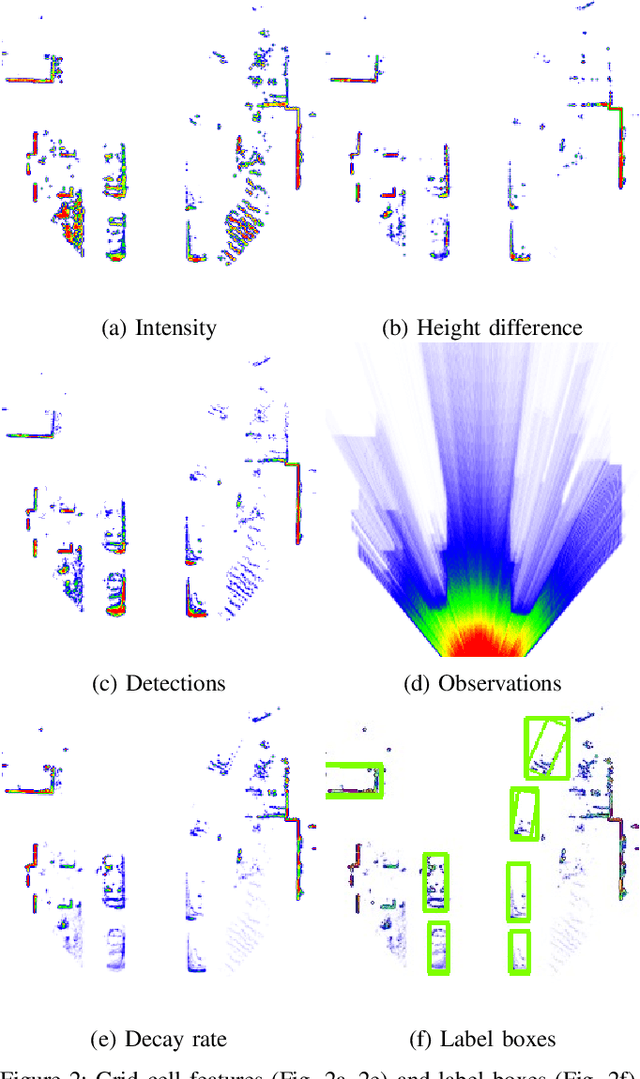


A detailed environment perception is a crucial component of automated vehicles. However, to deal with the amount of perceived information, we also require segmentation strategies. Based on a grid map environment representation, well-suited for sensor fusion, free-space estimation and machine learning, we detect and classify objects using deep convolutional neural networks. As input for our networks we use a multi-layer grid map efficiently encoding 3D range sensor information. The inference output consists of a list of rotated bounding boxes with associated semantic classes. We conduct extensive ablation studies, highlight important design considerations when using grid maps and evaluate our models on the KITTI Bird's Eye View benchmark. Qualitative and quantitative benchmark results show that we achieve robust detection and state of the art accuracy solely using top-view grid maps from range sensor data.
* 6 pages, 4 tables, 4 figures