 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSOMBRERO: Measuring and Steering Boundary Placement in End-to-End Hierarchical Sequence Models
Jan 30, 2026Hierarchical sequence models replace fixed tokenization with learned segmentations that compress long byte sequences for efficient autoregressive modeling. While recent end-to-end methods can learn meaningful boundaries from the language-modeling objective alone, it remains difficult to quantitatively assess and systematically steer where compute is spent. We introduce a router-agnostic metric of boundary quality, boundary enrichment B, which measures how strongly chunk starts concentrate on positions with high next-byte surprisal. Guided by this metric, we propose Sombrero, which steers boundary placement toward predictive difficulty via a confidence-alignment boundary loss and stabilizes boundary learning by applying confidence-weighted smoothing at the input level rather than on realized chunks. On 1B scale, across UTF-8 corpora covering English and German text as well as code and mathematical content, Sombrero improves the accuracy-efficiency trade-off and yields boundaries that more consistently align compute with hard-to-predict positions.
Accurate Training Data for Occupancy Map Prediction in Automated Driving Using Evidence Theory
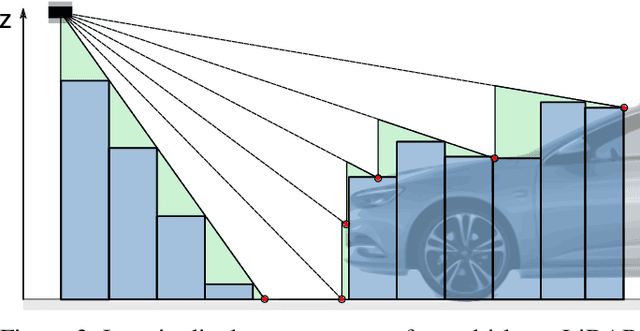
May 17, 2024Automated driving fundamentally requires knowledge about the surrounding geometry of the scene. Modern approaches use only captured images to predict occupancy maps that represent the geometry. Training these approaches requires accurate data that may be acquired with the help of LiDAR scanners. We show that the techniques used for current benchmarks and training datasets to convert LiDAR scans into occupancy grid maps yield very low quality, and subsequently present a novel approach using evidence theory that yields more accurate reconstructions. We demonstrate that these are superior by a large margin, both qualitatively and quantitatively, and that we additionally obtain meaningful uncertainty estimates. When converting the occupancy maps back to depth estimates and comparing them with the raw LiDAR measurements, our method yields a MAE improvement of 30% to 52% on nuScenes and 53% on Waymo over other occupancy ground-truth data. Finally, we use the improved occupancy maps to train a state-of-the-art occupancy prediction method and demonstrate that it improves the MAE by 25% on nuScenes.
Mapping LiDAR and Camera Measurements in a Dual Top-View Grid Representation Tailored for Automated Vehicles
Apr 21, 2022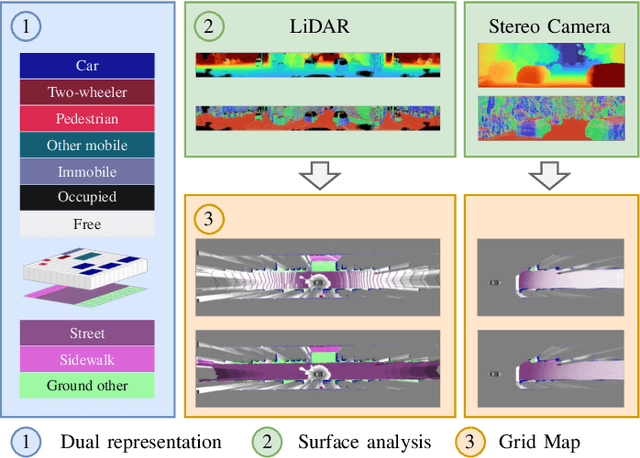

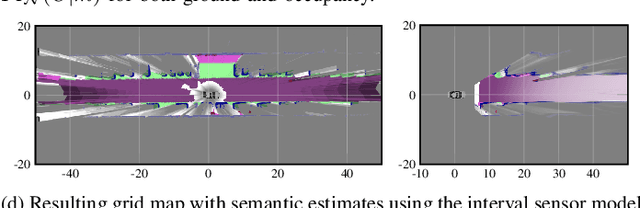

We present a generic evidential grid mapping pipeline designed for imaging sensors such as LiDARs and cameras. Our grid-based evidential model contains semantic estimates for cell occupancy and ground separately. We specify the estimation steps for input data represented by point sets, but mainly focus on input data represented by images such as disparity maps or LiDAR range images. Instead of relying on an external ground segmentation only, we deduce occupancy evidence by analyzing the surface orientation around measurements. We conduct experiments and evaluate the presented method using LiDAR and stereo camera data recorded in real traffic scenarios. Our method estimates cell occupancy robustly and with a high level of detail while maximizing efficiency and minimizing the dependency to external processing modules.
Sensor Data Fusion in Top-View Grid Maps using Evidential Reasoning with Advanced Conflict Resolution
Apr 19, 2022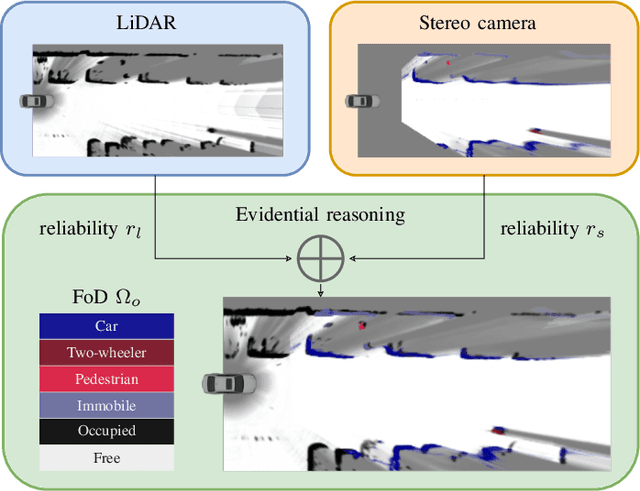
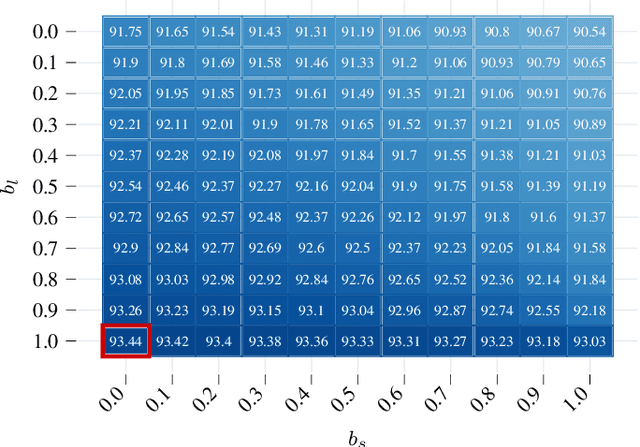

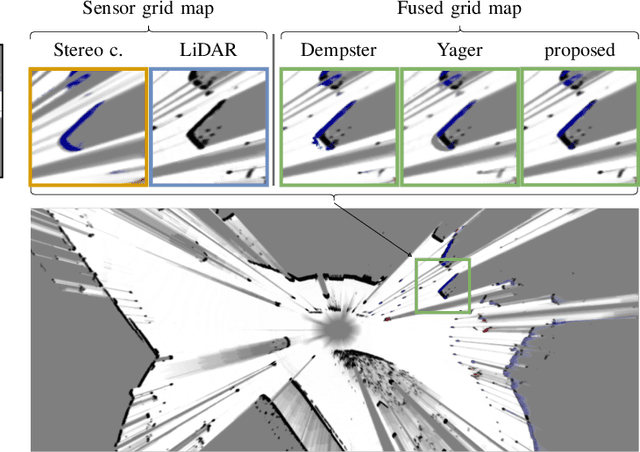
We present a new method to combine evidential top-view grid maps estimated based on heterogeneous sensor sources. Dempster's combination rule that is usually applied in this context provides undesired results with highly conflicting inputs. Therefore, we use more advanced evidential reasoning techniques and improve the conflict resolution by modeling the reliability of the evidence sources. We propose a data-driven reliability estimation to optimize the fusion quality using the Kitti-360 dataset. We apply the proposed method to the fusion of LiDAR and stereo camera data and evaluate the results qualitatively and quantitatively. The results demonstrate that our proposed method robustly combines measurements from heterogeneous sensors and successfully resolves sensor conflicts.
Fast and Robust Ground Surface Estimation from LIDAR Measurements using Uniform B-Splines
Mar 02, 2022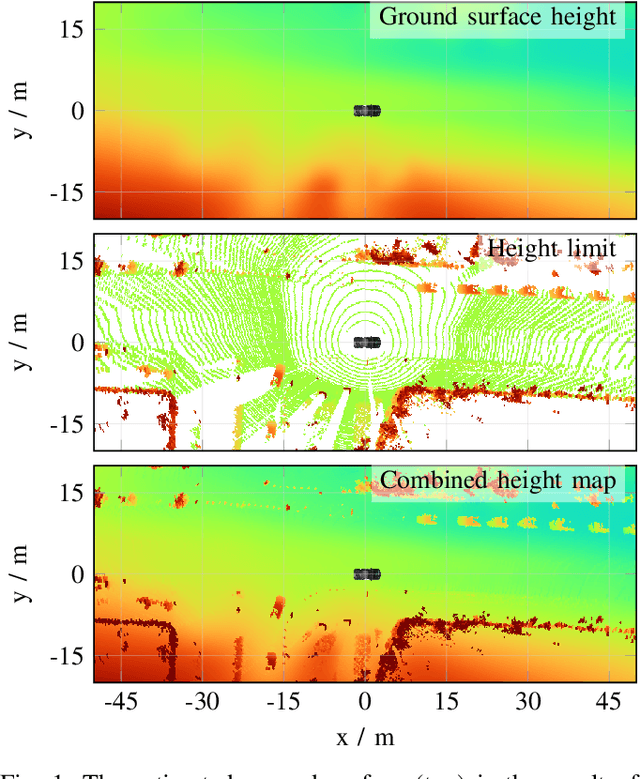

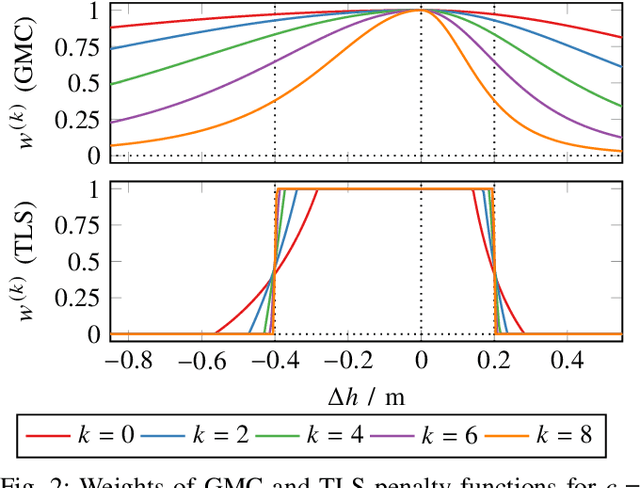
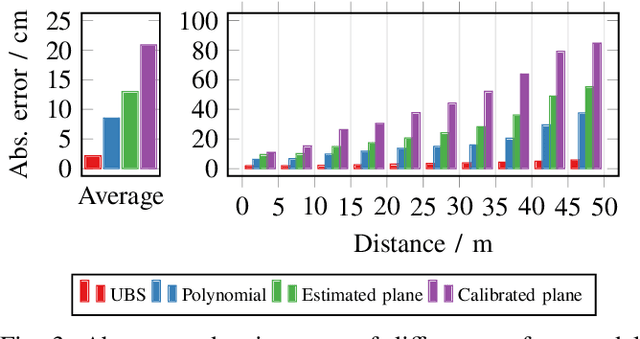
We propose a fast and robust method to estimate the ground surface from LIDAR measurements on an automated vehicle. The ground surface is modeled as a UBS which is robust towards varying measurement densities and with a single parameter controlling the smoothness prior. We model the estimation process as a robust LS optimization problem which can be reformulated as a linear problem and thus solved efficiently. Using the SemanticKITTI data set, we conduct a quantitative evaluation by classifying the point-wise semantic annotations into ground and non-ground points. Finally, we validate the approach on our research vehicle in real-world scenarios.
SemanticVoxels: Sequential Fusion for 3D Pedestrian Detection using LiDAR Point Cloud and Semantic Segmentation
Sep 25, 2020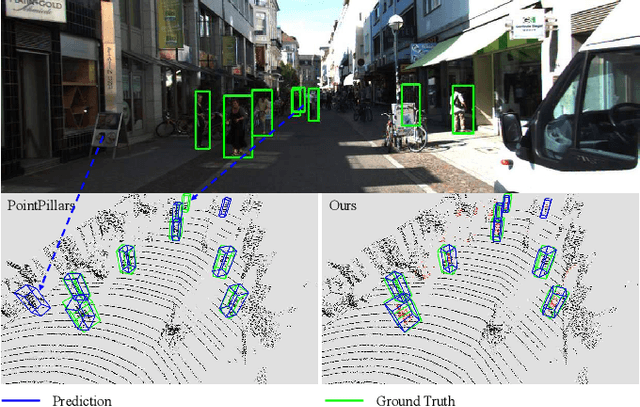
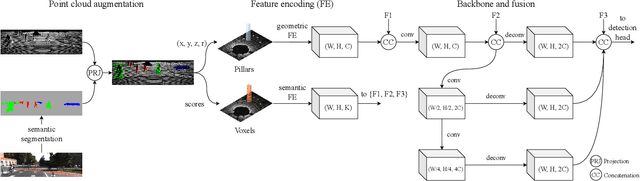

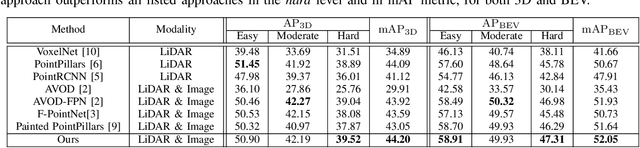
3D pedestrian detection is a challenging task in automated driving because pedestrians are relatively small, frequently occluded and easily confused with narrow vertical objects. LiDAR and camera are two commonly used sensor modalities for this task, which should provide complementary information. Unexpectedly, LiDAR-only detection methods tend to outperform multisensor fusion methods in public benchmarks. Recently, PointPainting has been presented to eliminate this performance drop by effectively fusing the output of a semantic segmentation network instead of the raw image information. In this paper, we propose a generalization of PointPainting to be able to apply fusion at different levels. After the semantic augmentation of the point cloud, we encode raw point data in pillars to get geometric features and semantic point data in voxels to get semantic features and fuse them in an effective way. Experimental results on the KITTI test set show that SemanticVoxels achieves state-of-the-art performance in both 3D and bird's eye view pedestrian detection benchmarks. In particular, our approach demonstrates its strength in detecting challenging pedestrian cases and outperforms current state-of-the-art approaches.
Exploiting Multi-Layer Grid Maps for Surround-View Semantic Segmentation of Sparse LiDAR Data
May 13, 2020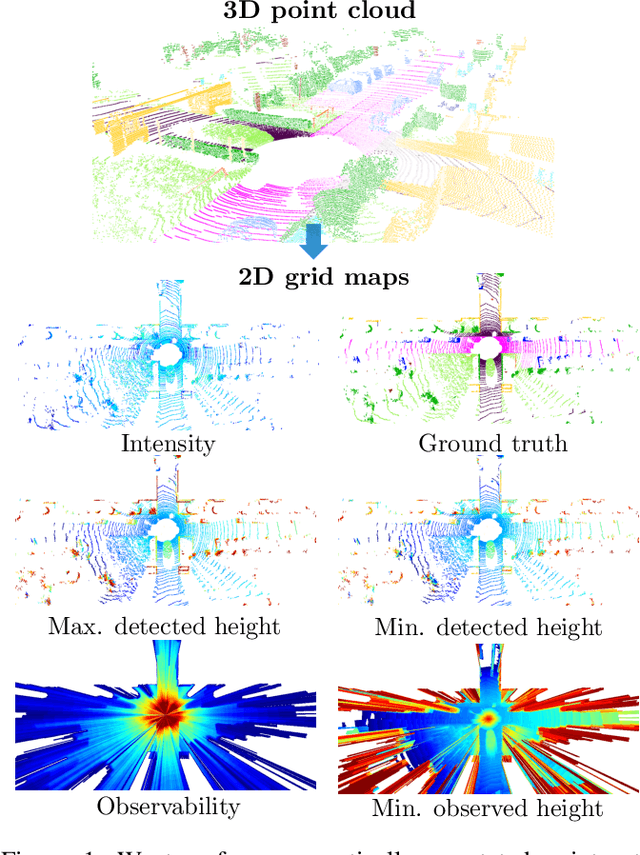
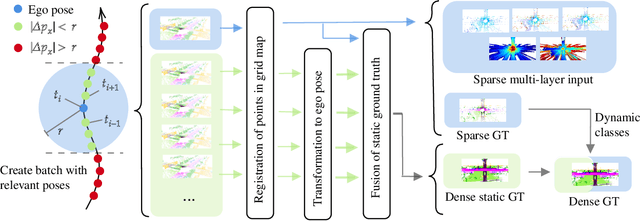
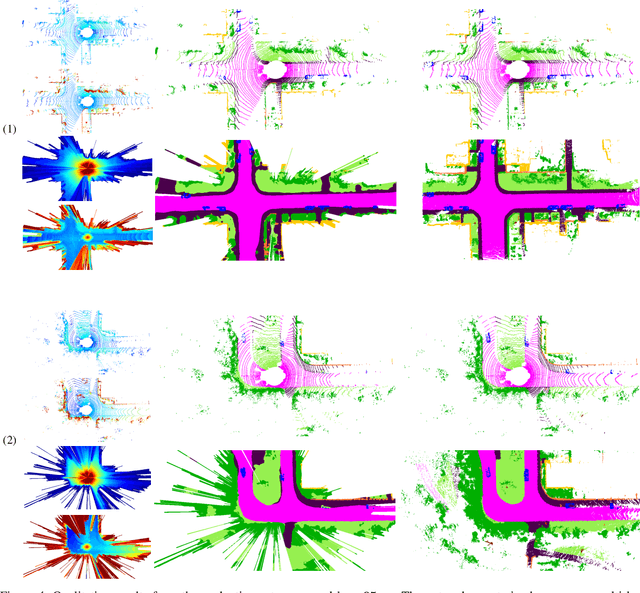
In this paper, we consider the transformation of laser range measurements into a top-view grid map representation to approach the task of LiDAR-only semantic segmentation. Since the recent publication of the SemanticKITTI data set, researchers are now able to study semantic segmentation of urban LiDAR sequences based on a reasonable amount of data. While other approaches propose to directly learn on the 3D point clouds, we are exploiting a grid map framework to extract relevant information and represent them by using multi-layer grid maps. This representation allows us to use well-studied deep learning architectures from the image domain to predict a dense semantic grid map using only the sparse input data of a single LiDAR scan. We compare single-layer and multi-layer approaches and demonstrate the benefit of a multi-layer grid map input. Since the grid map representation allows us to predict a dense, 360{\deg} semantic environment representation, we further develop a method to combine the semantic information from multiple scans and create dense ground truth grids. This method allows us to evaluate and compare the performance of our models not only based on grid cells with a detection, but on the full visible measurement range.
Learned Enrichment of Top-View Grid Maps Improves Object Detection
Mar 09, 2020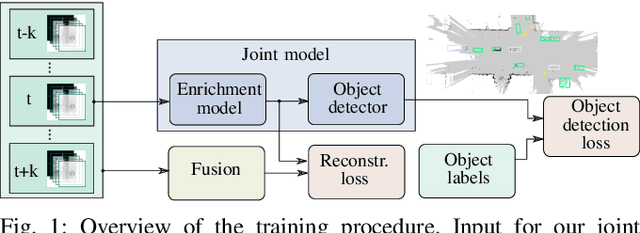

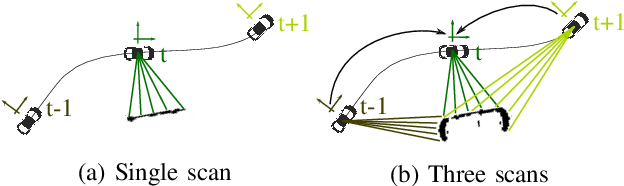

We propose an object detector for top-view grid maps which is additionally trained to generate an enriched version of its input. Our goal in the joint model is to improve generalization by regularizing towards structural knowledge in form of a map fused from multiple adjacent range sensor measurements. This training data can be generated in an automatic fashion, thus does not require manual annotations. We present an evidential framework to generate training data, investigate different model architectures and show that predicting enriched inputs as an additional task can improve object detection performance.
Single-Stage Object Detection from Top-View Grid Maps on Custom Sensor Setups
Feb 03, 2020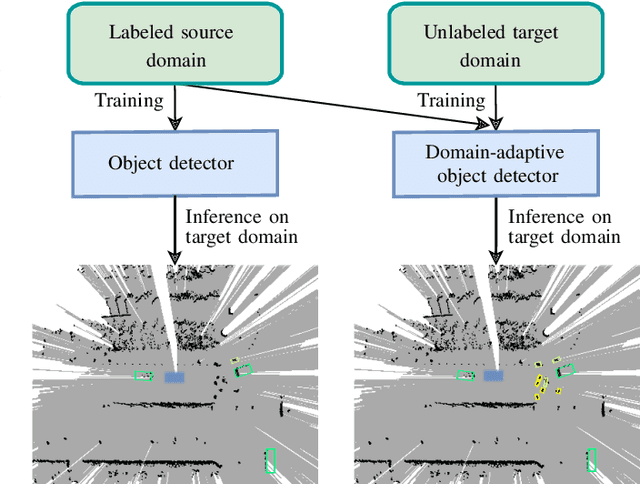



We present our approach to unsupervised domain adaptation for single-stage object detectors on top-view grid maps in automated driving scenarios. Our goal is to train a robust object detector on grid maps generated from custom sensor data and setups. We first introduce a single-stage object detector for grid maps based on RetinaNet. We then extend our model by image- and instance-level domain classifiers at different feature pyramid levels which are trained in an adversarial manner. This allows us to train robust object detectors for unlabeled domains. We evaluate our approach quantitatively on the nuScenes and KITTI benchmarks and present qualitative domain adaptation results for unlabeled measurements recorded by our experimental vehicle. Our results demonstrate that object detection accuracy for unlabeled domains can be improved by applying our domain adaptation strategy.
Localization in Aerial Imagery with Grid Maps using LocGAN
Jun 04, 2019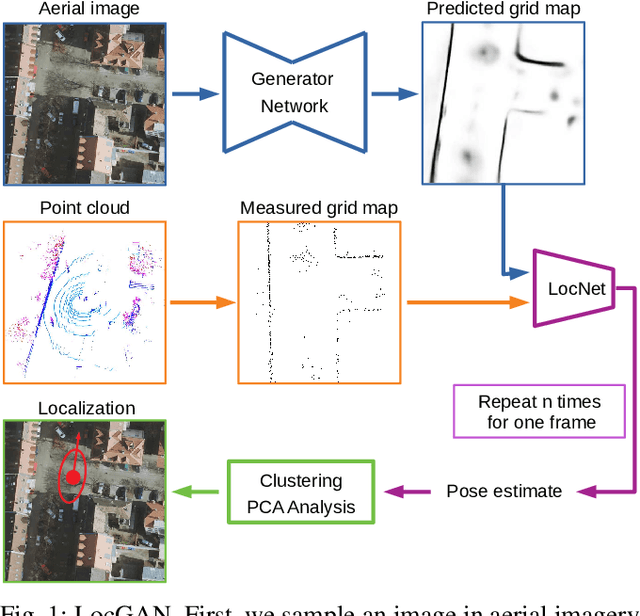
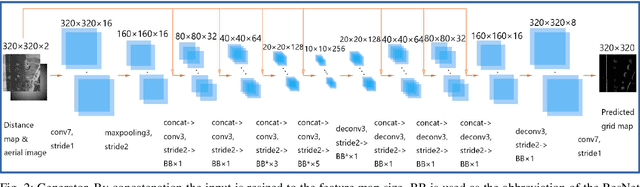
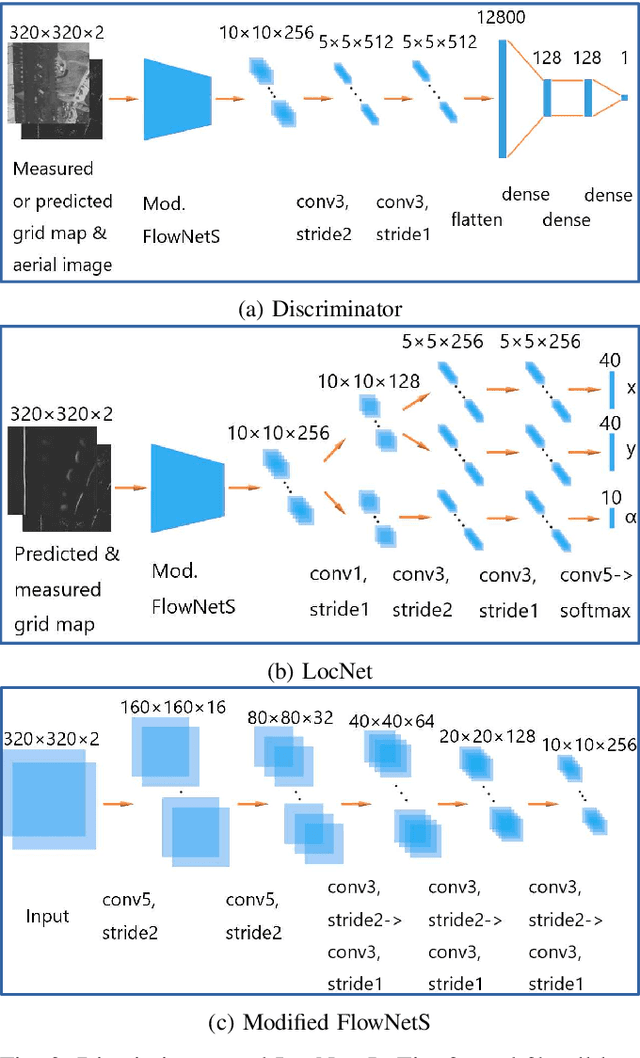
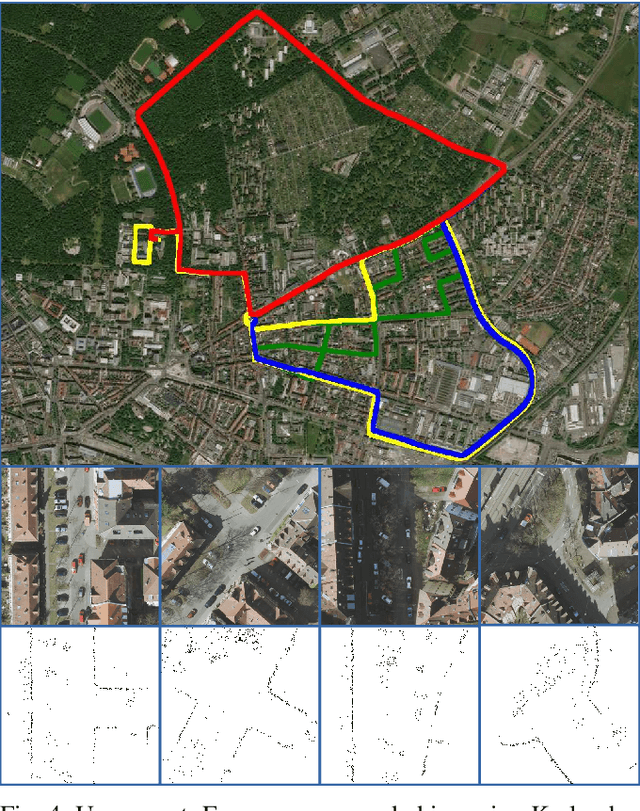
In this work, we present LocGAN, our localization approach based on a geo-referenced aerial imagery and LiDAR grid maps. Currently, most self-localization approaches relate the current sensor observations to a map generated from previously acquired data. Unfortunately, this data is not always available and the generated maps are usually sensor setup specific. Global Navigation Satellite Systems (GNSS) can overcome this problem. However, they are not always reliable especially in urban areas due to multi-path and shadowing effects. Since aerial imagery is usually available, we can use it as prior information. To match aerial images with grid maps, we use conditional Generative Adversarial Networks (cGANs) which transform aerial images to the grid map domain. The transformation between the predicted and measured grid map is estimated using a localization network (LocNet). Given the geo-referenced aerial image transformation the vehicle pose can be estimated. Evaluations performed on the data recorded in region Karlsruhe, Germany show that our LocGAN approach provides reliable global localization results.