 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-Dataset Experimental Study of Radar-Camera Fusion in Bird's-Eye View
Sep 27, 2023



By exploiting complementary sensor information, radar and camera fusion systems have the potential to provide a highly robust and reliable perception system for advanced driver assistance systems and automated driving functions. Recent advances in camera-based object detection offer new radar-camera fusion possibilities with bird's eye view feature maps. In this work, we propose a novel and flexible fusion network and evaluate its performance on two datasets: nuScenes and View-of-Delft. Our experiments reveal that while the camera branch needs large and diverse training data, the radar branch benefits more from a high-performance radar. Using transfer learning, we improve the camera's performance on the smaller dataset. Our results further demonstrate that the radar-camera fusion approach significantly outperforms the camera-only and radar-only baselines.
RC-BEVFusion: A Plug-In Module for Radar-Camera Bird's Eye View Feature Fusion
May 25, 2023



Radars and cameras belong to the most frequently used sensors for advanced driver assistance systems and automated driving research. However, there has been surprisingly little research on radar-camera fusion with neural networks. One of the reasons is a lack of large-scale automotive datasets with radar and unmasked camera data, with the exception of the nuScenes dataset. Another reason is the difficulty of effectively fusing the sparse radar point cloud on the bird's eye view (BEV) plane with the dense images on the perspective plane. The recent trend of camera-based 3D object detection using BEV features has enabled a new type of fusion, which is better suited for radars. In this work, we present RC-BEVFusion, a modular radar-camera fusion network on the BEV plane. We propose BEVFeatureNet, a novel radar encoder branch, and show that it can be incorporated into several state-of-the-art camera-based architectures. We show significant performance gains of up to 28% increase in the nuScenes detection score, which is an important step in radar-camera fusion research. Without tuning our model for the nuScenes benchmark, we achieve the best result among all published methods in the radar-camera fusion category.
Deployment of Deep Neural Networks for Object Detection on Edge AI Devices with Runtime Optimization
Aug 18, 2021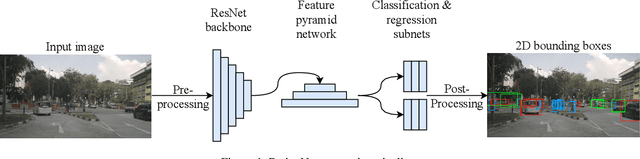

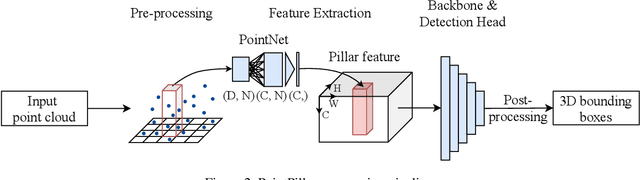
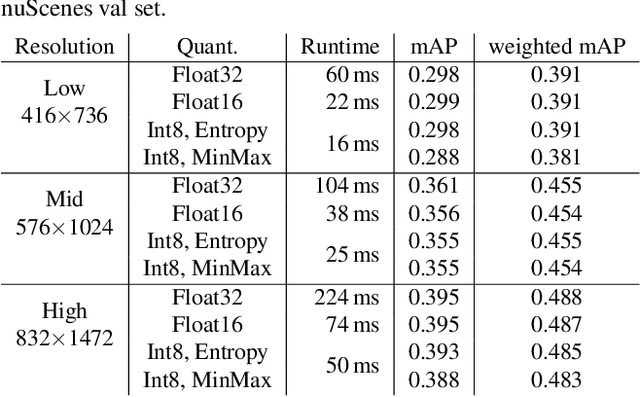
Deep neural networks have proven increasingly important for automotive scene understanding with new algorithms offering constant improvements of the detection performance. However, there is little emphasis on experiences and needs for deployment in embedded environments. We therefore perform a case study of the deployment of two representative object detection networks on an edge AI platform. In particular, we consider RetinaNet for image-based 2D object detection and PointPillars for LiDAR-based 3D object detection. We describe the modifications necessary to convert the algorithms from a PyTorch training environment to the deployment environment taking into account the available tools. We evaluate the runtime of the deployed DNN using two different libraries, TensorRT and TorchScript. In our experiments, we observe slight advantages of TensorRT for convolutional layers and TorchScript for fully connected layers. We also study the trade-off between runtime and performance, when selecting an optimized setup for deployment, and observe that quantization significantly reduces the runtime while having only little impact on the detection performance.
MASS: Multi-Attentional Semantic Segmentation of LiDAR Data for Dense Top-View Understanding
Jul 01, 2021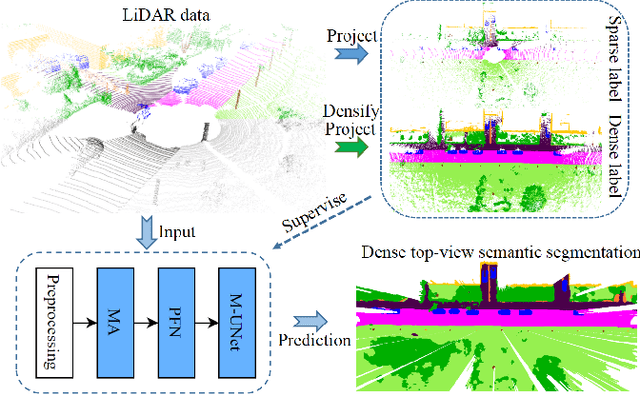
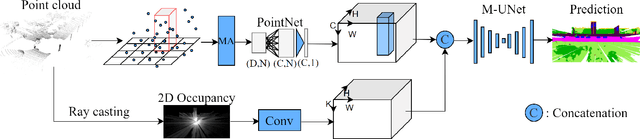
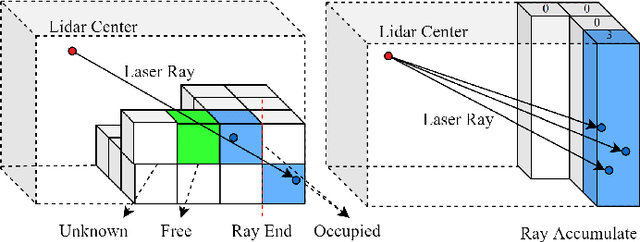
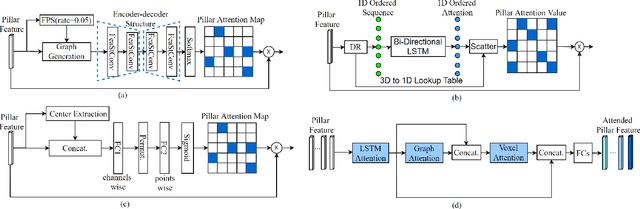
At the heart of all automated driving systems is the ability to sense the surroundings, e.g., through semantic segmentation of LiDAR sequences, which experienced a remarkable progress due to the release of large datasets such as SemanticKITTI and nuScenes-LidarSeg. While most previous works focus on sparse segmentation of the LiDAR input, dense output masks provide self-driving cars with almost complete environment information. In this paper, we introduce MASS - a Multi-Attentional Semantic Segmentation model specifically built for dense top-view understanding of the driving scenes. Our framework operates on pillar- and occupancy features and comprises three attention-based building blocks: (1) a keypoint-driven graph attention, (2) an LSTM-based attention computed from a vector embedding of the spatial input, and (3) a pillar-based attention, resulting in a dense 360-degree segmentation mask. With extensive experiments on both, SemanticKITTI and nuScenes-LidarSeg, we quantitatively demonstrate the effectiveness of our model, outperforming the state of the art by 19.0% on SemanticKITTI and reaching 32.7% in mIoU on nuScenes-LidarSeg, where MASS is the first work addressing the dense segmentation task. Furthermore, our multi-attention model is shown to be very effective for 3D object detection validated on the KITTI-3D dataset, showcasing its high generalizability to other tasks related to 3D vision.
PillarSegNet: Pillar-based Semantic Grid Map Estimation using Sparse LiDAR Data
May 10, 2021
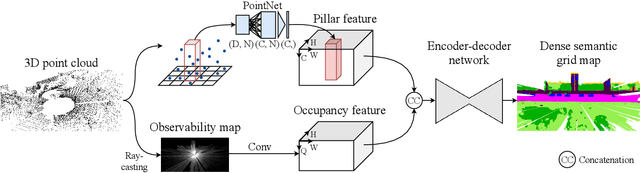
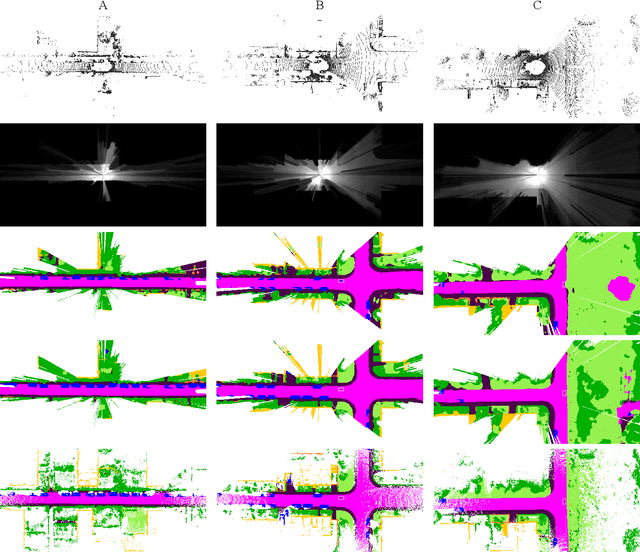
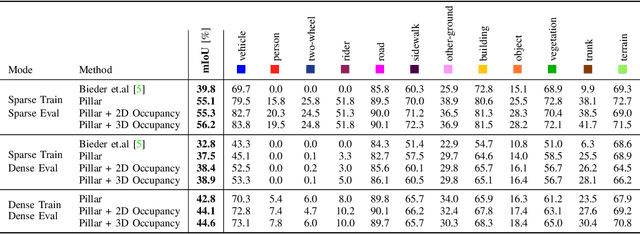
Semantic understanding of the surrounding environment is essential for automated vehicles. The recent publication of the SemanticKITTI dataset stimulates the research on semantic segmentation of LiDAR point clouds in urban scenarios. While most existing approaches predict sparse pointwise semantic classes for the sparse input LiDAR scan, we propose PillarSegNet to be able to output a dense semantic grid map. In contrast to a previously proposed grid map method, PillarSegNet uses PointNet to learn features directly from the 3D point cloud and then conducts 2D semantic segmentation in the top view. To train and evaluate our approach, we use both sparse and dense ground truth, where the dense ground truth is obtained from multiple superimposed scans. Experimental results on the SemanticKITTI dataset show that PillarSegNet achieves a performance gain of about 10% mIoU over the state-of-the-art grid map method.
SemanticVoxels: Sequential Fusion for 3D Pedestrian Detection using LiDAR Point Cloud and Semantic Segmentation
Sep 25, 2020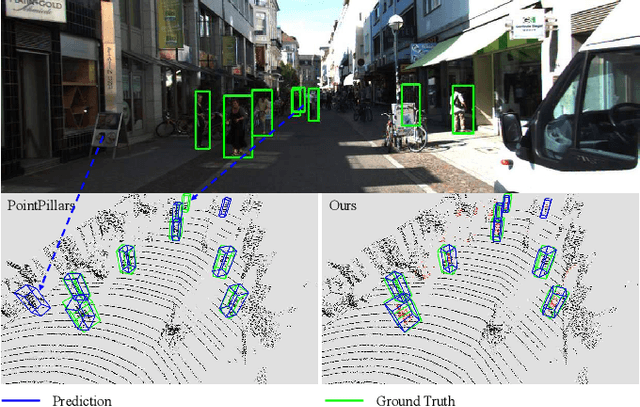
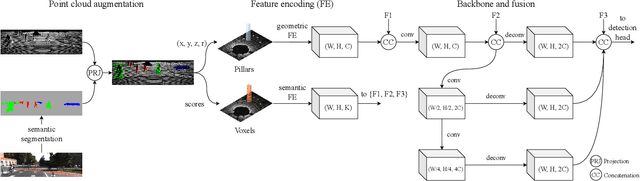

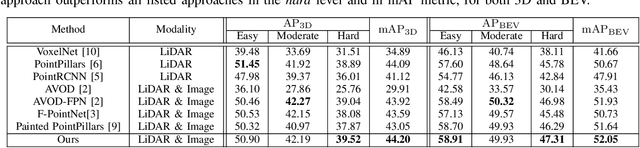
3D pedestrian detection is a challenging task in automated driving because pedestrians are relatively small, frequently occluded and easily confused with narrow vertical objects. LiDAR and camera are two commonly used sensor modalities for this task, which should provide complementary information. Unexpectedly, LiDAR-only detection methods tend to outperform multisensor fusion methods in public benchmarks. Recently, PointPainting has been presented to eliminate this performance drop by effectively fusing the output of a semantic segmentation network instead of the raw image information. In this paper, we propose a generalization of PointPainting to be able to apply fusion at different levels. After the semantic augmentation of the point cloud, we encode raw point data in pillars to get geometric features and semantic point data in voxels to get semantic features and fuse them in an effective way. Experimental results on the KITTI test set show that SemanticVoxels achieves state-of-the-art performance in both 3D and bird's eye view pedestrian detection benchmarks. In particular, our approach demonstrates its strength in detecting challenging pedestrian cases and outperforms current state-of-the-art approaches.