 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStep-by-Step Causality: Transparent Causal Discovery with Multi-Agent Tree-Query and Adversarial Confidence Estimation
Jan 15, 2026Causal discovery aims to recover ``what causes what'', but classical constraint-based methods (e.g., PC, FCI) suffer from error propagation, and recent LLM-based causal oracles often behave as opaque, confidence-free black boxes. This paper introduces Tree-Query, a tree-structured, multi-expert LLM framework that reduces pairwise causal discovery to a short sequence of queries about backdoor paths, (in)dependence, latent confounding, and causal direction, yielding interpretable judgments with robustness-aware confidence scores. Theoretical guarantees are provided for asymptotic identifiability of four pairwise relations. On data-free benchmarks derived from Mooij et al. and UCI causal graphs, Tree-Query improves structural metrics over direct LLM baselines, and a diet--weight case study illustrates confounder screening and stable, high-confidence causal conclusions. Tree-Query thus offers a principled way to obtain data-free causal priors from LLMs that can complement downstream data-driven causal discovery. Code is available at https://anonymous.4open.science/r/Repo-9B3E-4F96.
Generalist versus Specialist Vision Foundation Models for Ocular Disease and Oculomics
Sep 03, 2025Medical foundation models, pre-trained with large-scale clinical data, demonstrate strong performance in diverse clinically relevant applications. RETFound, trained on nearly one million retinal images, exemplifies this approach in applications with retinal images. However, the emergence of increasingly powerful and multifold larger generalist foundation models such as DINOv2 and DINOv3 raises the question of whether domain-specific pre-training remains essential, and if so, what gap persists. To investigate this, we systematically evaluated the adaptability of DINOv2 and DINOv3 in retinal image applications, compared to two specialist RETFound models, RETFound-MAE and RETFound-DINOv2. We assessed performance on ocular disease detection and systemic disease prediction using two adaptation strategies: fine-tuning and linear probing. Data efficiency and adaptation efficiency were further analysed to characterise trade-offs between predictive performance and computational cost. Our results show that although scaling generalist models yields strong adaptability across diverse tasks, RETFound-DINOv2 consistently outperforms these generalist foundation models in ocular-disease detection and oculomics tasks, demonstrating stronger generalisability and data efficiency. These findings suggest that specialist retinal foundation models remain the most effective choice for clinical applications, while the narrowing gap with generalist foundation models suggests that continued data and model scaling can deliver domain-relevant gains and position them as strong foundations for future medical foundation models.
Learning Coordination Policies over Heterogeneous Graphs for Human-Robot Teams via Recurrent Neural Schedule Propagation
Jan 30, 2023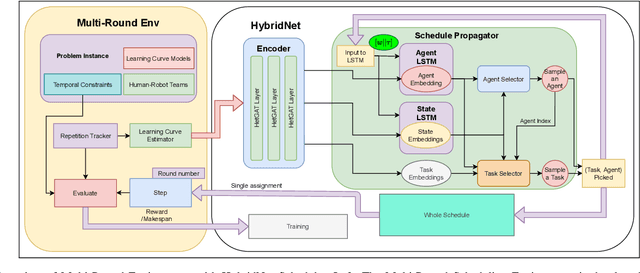
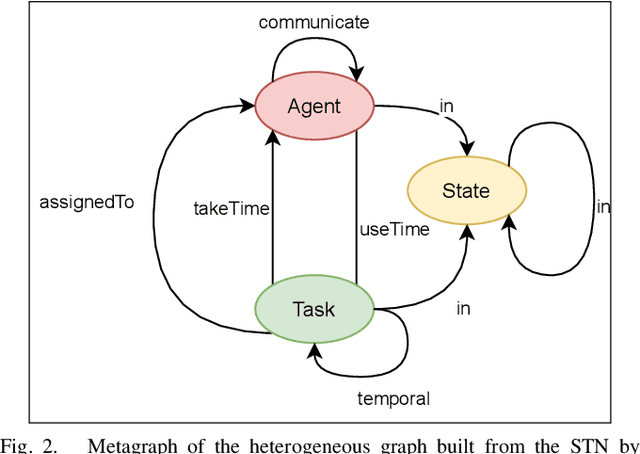
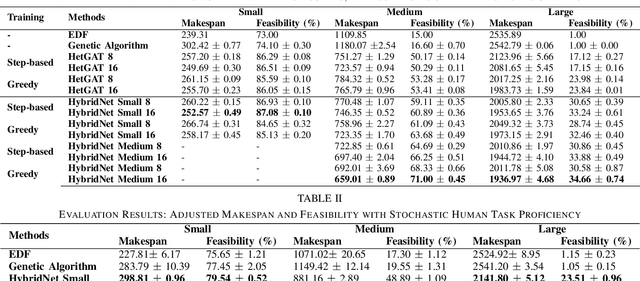
As human-robot collaboration increases in the workforce, it becomes essential for human-robot teams to coordinate efficiently and intuitively. Traditional approaches for human-robot scheduling either utilize exact methods that are intractable for large-scale problems and struggle to account for stochastic, time varying human task performance, or application-specific heuristics that require expert domain knowledge to develop. We propose a deep learning-based framework, called HybridNet, combining a heterogeneous graph-based encoder with a recurrent schedule propagator for scheduling stochastic human-robot teams under upper- and lower-bound temporal constraints. The HybridNet's encoder leverages Heterogeneous Graph Attention Networks to model the initial environment and team dynamics while accounting for the constraints. By formulating task scheduling as a sequential decision-making process, the HybridNet's recurrent neural schedule propagator leverages Long Short-Term Memory (LSTM) models to propagate forward consequences of actions to carry out fast schedule generation, removing the need to interact with the environment between every task-agent pair selection. The resulting scheduling policy network provides a computationally lightweight yet highly expressive model that is end-to-end trainable via Reinforcement Learning algorithms. We develop a virtual task scheduling environment for mixed human-robot teams in a multi-round setting, capable of modeling the stochastic learning behaviors of human workers. Experimental results showed that HybridNet outperformed other human-robot scheduling solutions across problem sizes for both deterministic and stochastic human performance, with faster runtime compared to pure-GNN-based schedulers.
* 8 pages, 2 figures, 3 Tables
NTIRE 2022 Challenge on Efficient Super-Resolution: Methods and Results
May 11, 2022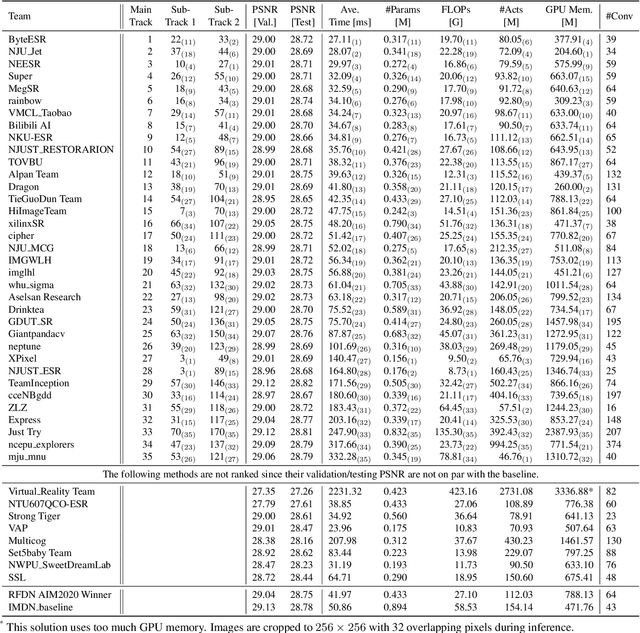
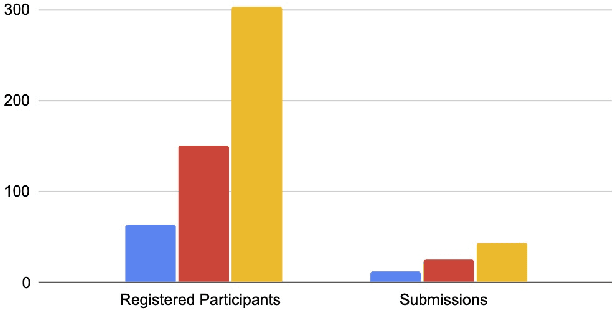
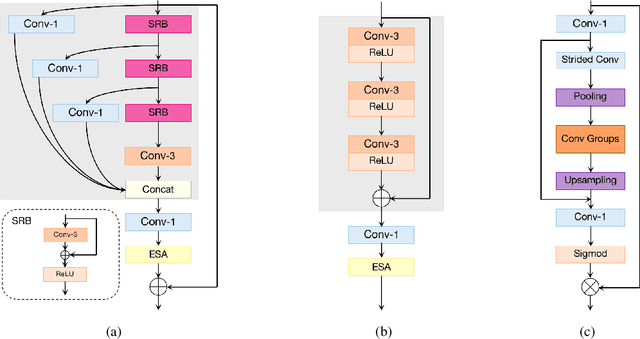
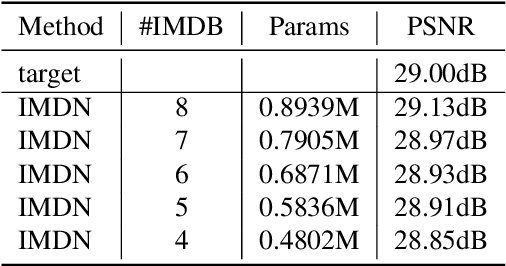
This paper reviews the NTIRE 2022 challenge on efficient single image super-resolution with focus on the proposed solutions and results. The task of the challenge was to super-resolve an input image with a magnification factor of $\times$4 based on pairs of low and corresponding high resolution images. The aim was to design a network for single image super-resolution that achieved improvement of efficiency measured according to several metrics including runtime, parameters, FLOPs, activations, and memory consumption while at least maintaining the PSNR of 29.00dB on DIV2K validation set. IMDN is set as the baseline for efficiency measurement. The challenge had 3 tracks including the main track (runtime), sub-track one (model complexity), and sub-track two (overall performance). In the main track, the practical runtime performance of the submissions was evaluated. The rank of the teams were determined directly by the absolute value of the average runtime on the validation set and test set. In sub-track one, the number of parameters and FLOPs were considered. And the individual rankings of the two metrics were summed up to determine a final ranking in this track. In sub-track two, all of the five metrics mentioned in the description of the challenge including runtime, parameter count, FLOPs, activations, and memory consumption were considered. Similar to sub-track one, the rankings of five metrics were summed up to determine a final ranking. The challenge had 303 registered participants, and 43 teams made valid submissions. They gauge the state-of-the-art in efficient single image super-resolution.
Exploiting Multi-Layer Grid Maps for Surround-View Semantic Segmentation of Sparse LiDAR Data
May 13, 2020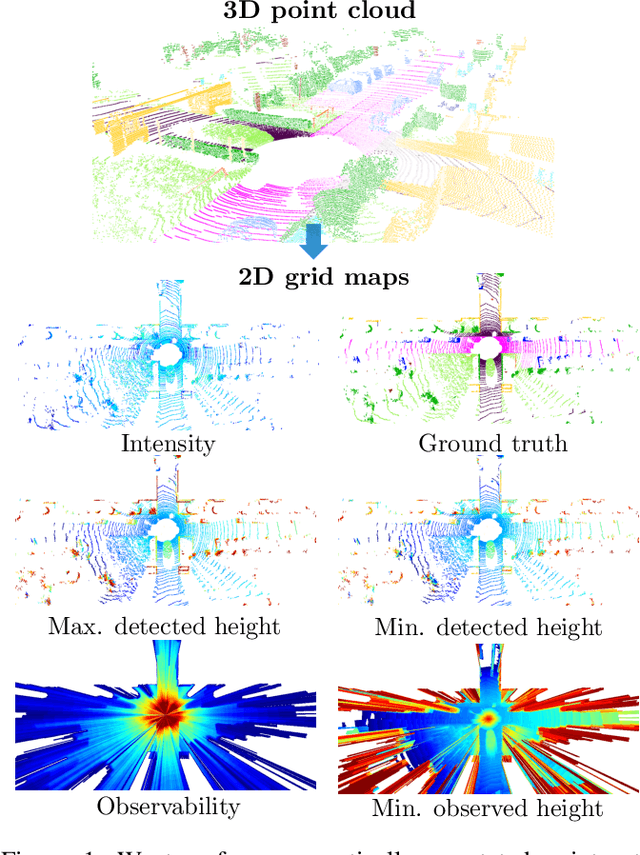
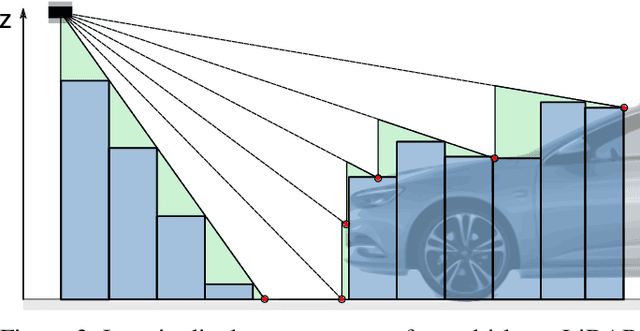
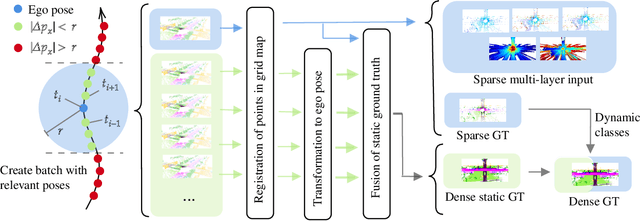
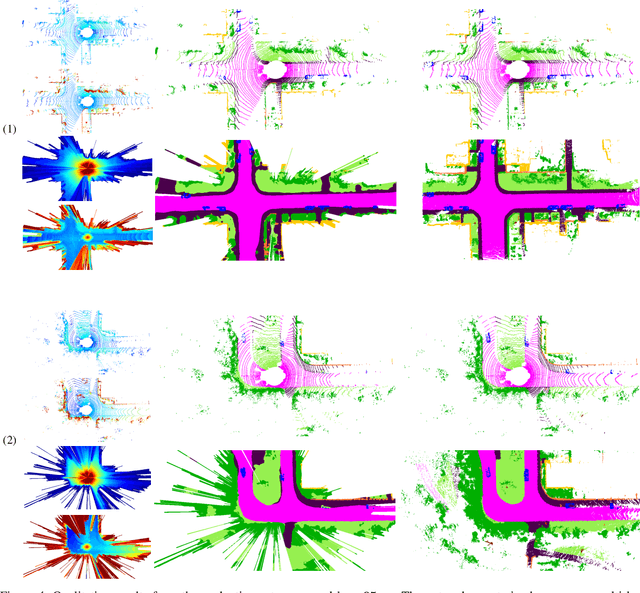
In this paper, we consider the transformation of laser range measurements into a top-view grid map representation to approach the task of LiDAR-only semantic segmentation. Since the recent publication of the SemanticKITTI data set, researchers are now able to study semantic segmentation of urban LiDAR sequences based on a reasonable amount of data. While other approaches propose to directly learn on the 3D point clouds, we are exploiting a grid map framework to extract relevant information and represent them by using multi-layer grid maps. This representation allows us to use well-studied deep learning architectures from the image domain to predict a dense semantic grid map using only the sparse input data of a single LiDAR scan. We compare single-layer and multi-layer approaches and demonstrate the benefit of a multi-layer grid map input. Since the grid map representation allows us to predict a dense, 360{\deg} semantic environment representation, we further develop a method to combine the semantic information from multiple scans and create dense ground truth grids. This method allows us to evaluate and compare the performance of our models not only based on grid cells with a detection, but on the full visible measurement range.
Learning to Dynamically Coordinate Multi-Robot Teams in Graph Attention Networks
Dec 04, 2019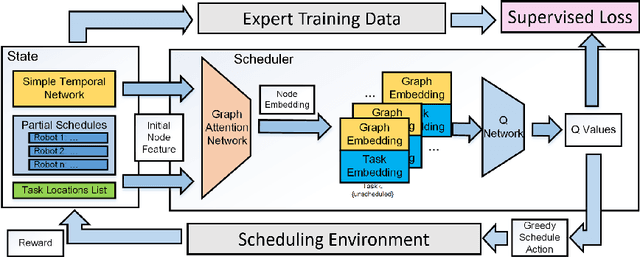
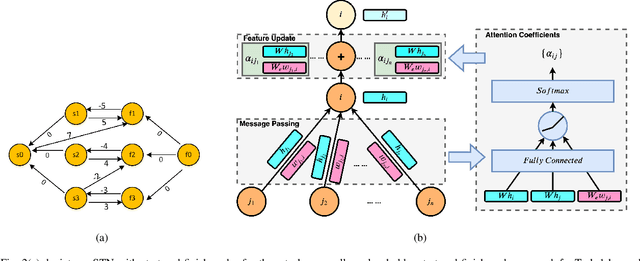
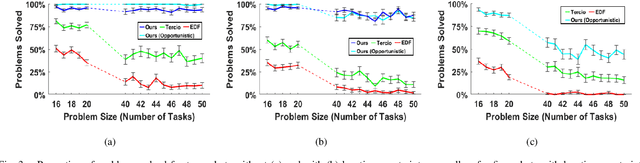
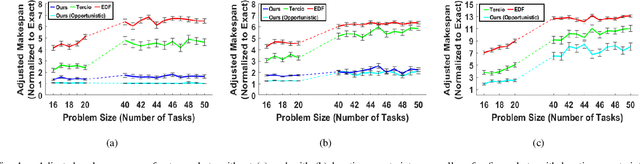
Increasing interest in integrating advanced robotics within manufacturing has spurred a renewed concentration in developing real-time scheduling solutions to coordinate human-robot collaboration in this environment. Traditionally, the problem of scheduling agents to complete tasks with temporal and spatial constraints has been approached either with exact algorithms, which are computationally intractable for large-scale, dynamic coordination, or approximate methods that require domain experts to craft heuristics for each application. We seek to overcome the limitations of these conventional methods by developing a novel graph attention network formulation to automatically learn features of scheduling problems to allow their deployment. To learn effective policies for combinatorial optimization problems via machine learning, we combine imitation learning on smaller problems with deep Q-learning on larger problems, in a non-parametric framework, to allow for fast, near-optimal scheduling of robot teams. We show that our network-based policy finds at least twice as many solutions over prior state-of-the-art methods in all testing scenarios.