 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMapping LiDAR and Camera Measurements in a Dual Top-View Grid Representation Tailored for Automated Vehicles
Apr 21, 2022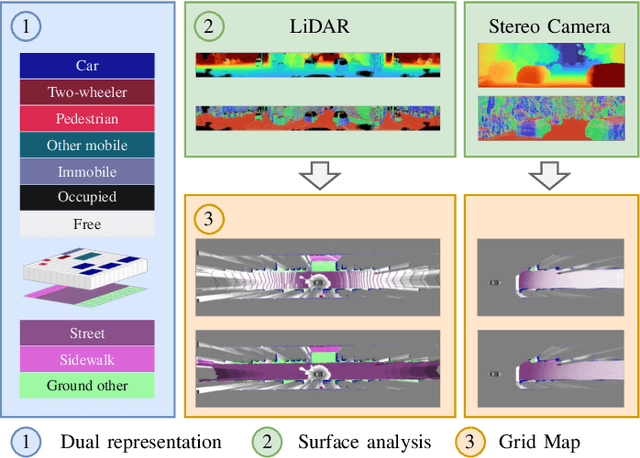

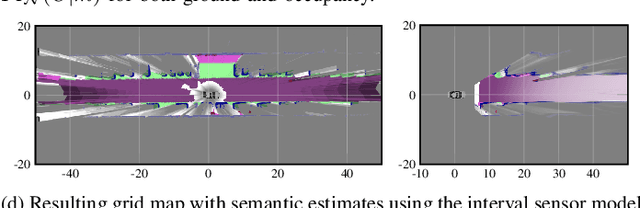

We present a generic evidential grid mapping pipeline designed for imaging sensors such as LiDARs and cameras. Our grid-based evidential model contains semantic estimates for cell occupancy and ground separately. We specify the estimation steps for input data represented by point sets, but mainly focus on input data represented by images such as disparity maps or LiDAR range images. Instead of relying on an external ground segmentation only, we deduce occupancy evidence by analyzing the surface orientation around measurements. We conduct experiments and evaluate the presented method using LiDAR and stereo camera data recorded in real traffic scenarios. Our method estimates cell occupancy robustly and with a high level of detail while maximizing efficiency and minimizing the dependency to external processing modules.
Sensor Data Fusion in Top-View Grid Maps using Evidential Reasoning with Advanced Conflict Resolution
Apr 19, 2022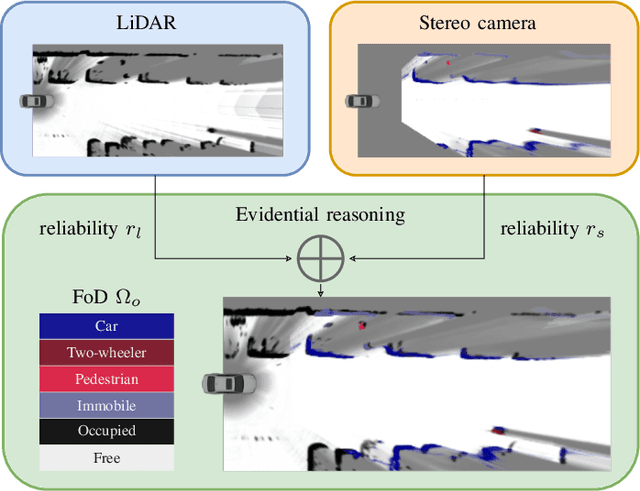
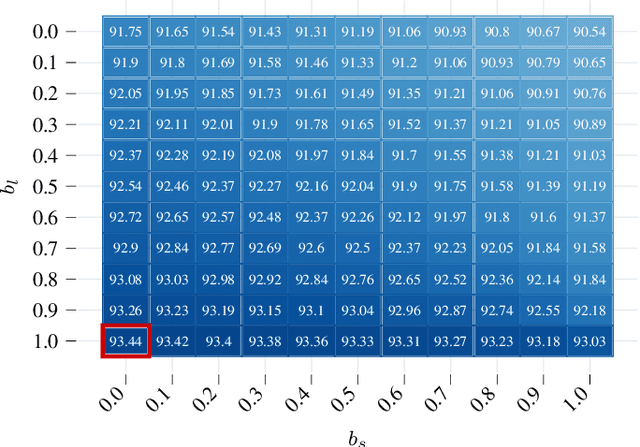

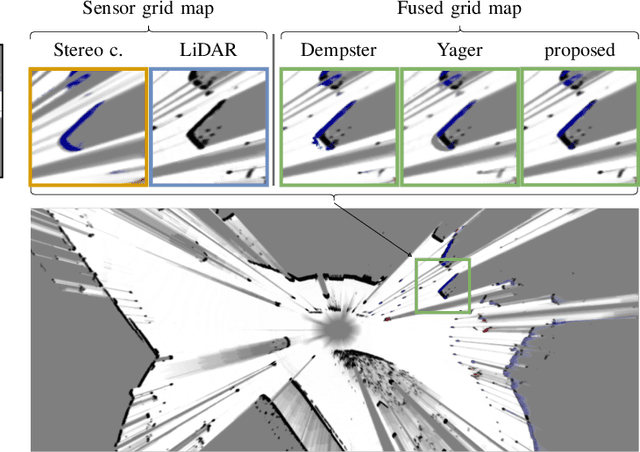
We present a new method to combine evidential top-view grid maps estimated based on heterogeneous sensor sources. Dempster's combination rule that is usually applied in this context provides undesired results with highly conflicting inputs. Therefore, we use more advanced evidential reasoning techniques and improve the conflict resolution by modeling the reliability of the evidence sources. We propose a data-driven reliability estimation to optimize the fusion quality using the Kitti-360 dataset. We apply the proposed method to the fusion of LiDAR and stereo camera data and evaluate the results qualitatively and quantitatively. The results demonstrate that our proposed method robustly combines measurements from heterogeneous sensors and successfully resolves sensor conflicts.
Exploiting Multi-Layer Grid Maps for Surround-View Semantic Segmentation of Sparse LiDAR Data
May 13, 2020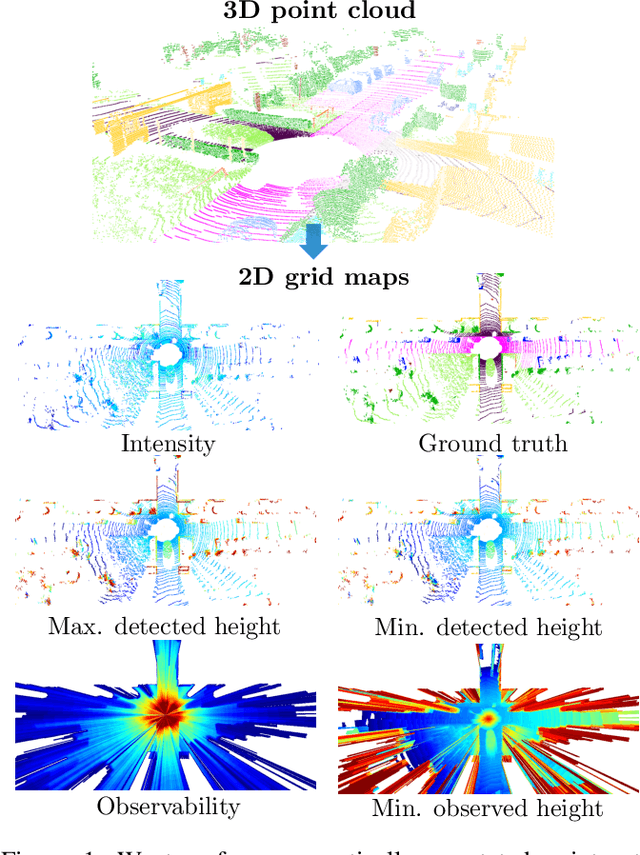
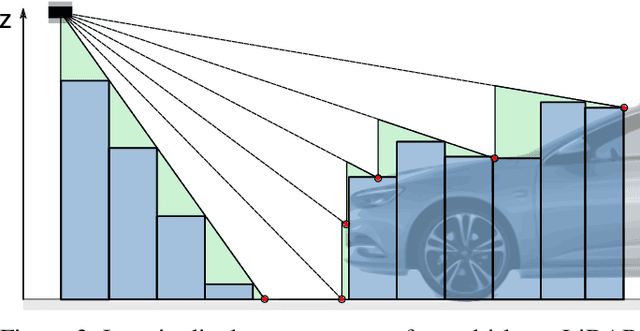
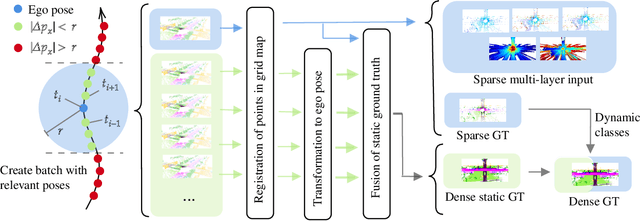
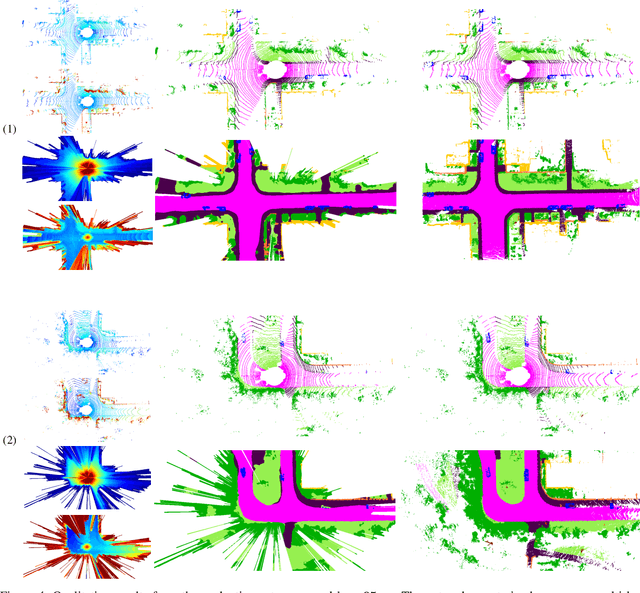
In this paper, we consider the transformation of laser range measurements into a top-view grid map representation to approach the task of LiDAR-only semantic segmentation. Since the recent publication of the SemanticKITTI data set, researchers are now able to study semantic segmentation of urban LiDAR sequences based on a reasonable amount of data. While other approaches propose to directly learn on the 3D point clouds, we are exploiting a grid map framework to extract relevant information and represent them by using multi-layer grid maps. This representation allows us to use well-studied deep learning architectures from the image domain to predict a dense semantic grid map using only the sparse input data of a single LiDAR scan. We compare single-layer and multi-layer approaches and demonstrate the benefit of a multi-layer grid map input. Since the grid map representation allows us to predict a dense, 360{\deg} semantic environment representation, we further develop a method to combine the semantic information from multiple scans and create dense ground truth grids. This method allows us to evaluate and compare the performance of our models not only based on grid cells with a detection, but on the full visible measurement range.
Learned Enrichment of Top-View Grid Maps Improves Object Detection
Mar 09, 2020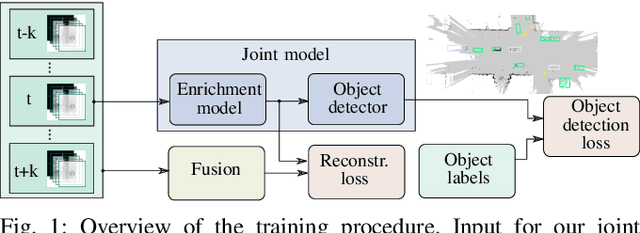

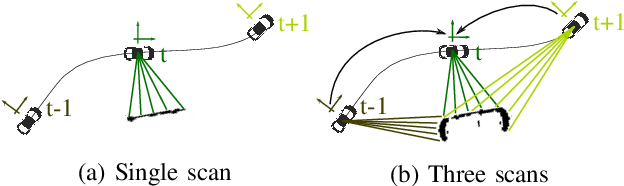

We propose an object detector for top-view grid maps which is additionally trained to generate an enriched version of its input. Our goal in the joint model is to improve generalization by regularizing towards structural knowledge in form of a map fused from multiple adjacent range sensor measurements. This training data can be generated in an automatic fashion, thus does not require manual annotations. We present an evidential framework to generate training data, investigate different model architectures and show that predicting enriched inputs as an additional task can improve object detection performance.