 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZero-shot Load Forecasting for Integrated Energy Systems: A Large Language Model-based Framework with Multi-task Learning
Feb 24, 2025The growing penetration of renewable energy sources in power systems has increased the complexity and uncertainty of load forecasting, especially for integrated energy systems with multiple energy carriers. Traditional forecasting methods heavily rely on historical data and exhibit limited transferability across different scenarios, posing significant challenges for emerging applications in smart grids and energy internet. This paper proposes the TSLLM-Load Forecasting Mechanism, a novel zero-shot load forecasting framework based on large language models (LLMs) to address these challenges. The framework consists of three key components: a data preprocessing module that handles multi-source energy load data, a time series prompt generation module that bridges the semantic gap between energy data and LLMs through multi-task learning and similarity alignment, and a prediction module that leverages pre-trained LLMs for accurate forecasting. The framework's effectiveness was validated on a real-world dataset comprising load profiles from 20 Australian solar-powered households, demonstrating superior performance in both conventional and zero-shot scenarios. In conventional testing, our method achieved a Mean Squared Error (MSE) of 0.4163 and a Mean Absolute Error (MAE) of 0.3760, outperforming existing approaches by at least 8\%. In zero-shot prediction experiments across 19 households, the framework maintained consistent accuracy with a total MSE of 11.2712 and MAE of 7.6709, showing at least 12\% improvement over current methods. The results validate the framework's potential for accurate and transferable load forecasting in integrated energy systems, particularly beneficial for renewable energy integration and smart grid applications.
An Evolutionary Algorithm for Task Scheduling in Crowdsourced Software Development
Jul 05, 2021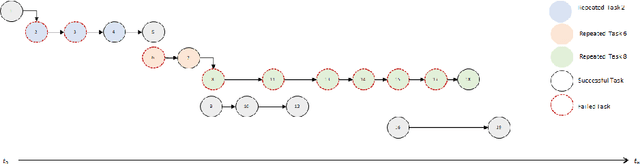

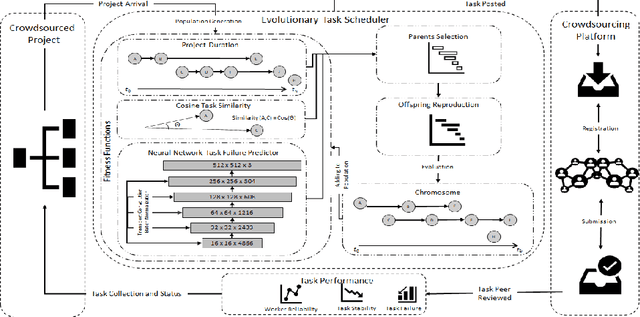
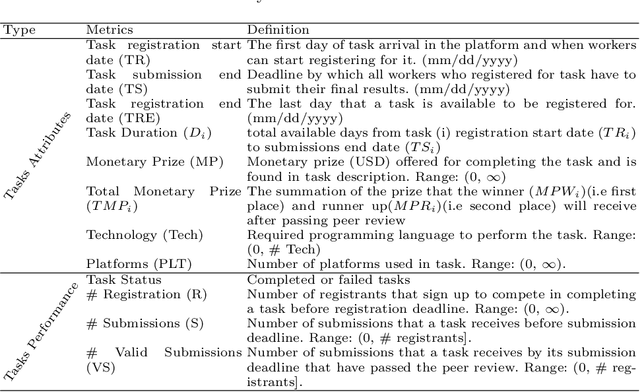
The complexity of software tasks and the uncertainty of crowd developer behaviors make it challenging to plan crowdsourced software development (CSD) projects. In a competitive crowdsourcing marketplace, competition for shared worker resources from multiple simultaneously open tasks adds another layer of uncertainty to the potential outcomes of software crowdsourcing. These factors lead to the need for supporting CSD managers with automated scheduling to improve the visibility and predictability of crowdsourcing processes and outcomes. To that end, this paper proposes an evolutionary algorithm-based task scheduling method for crowdsourced software development. The proposed evolutionary scheduling method uses a multiobjective genetic algorithm to recommend an optimal task start date. The method uses three fitness functions, based on project duration, task similarity, and task failure prediction, respectively. The task failure fitness function uses a neural network to predict the probability of task failure with respect to a specific task start date. The proposed method then recommends the best tasks start dates for the project as a whole and each individual task so as to achieve the lowest project failure ratio. Experimental results on 4 projects demonstrate that the proposed method has the potential to reduce project duration by a factor of 33-78%.
Study on Patterns and Effect of Task Diversity in Software Crowdsourcing
May 29, 2020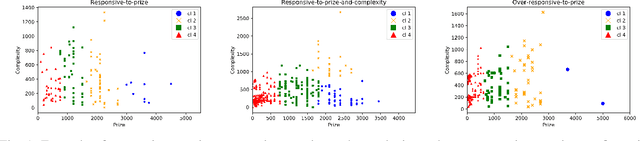
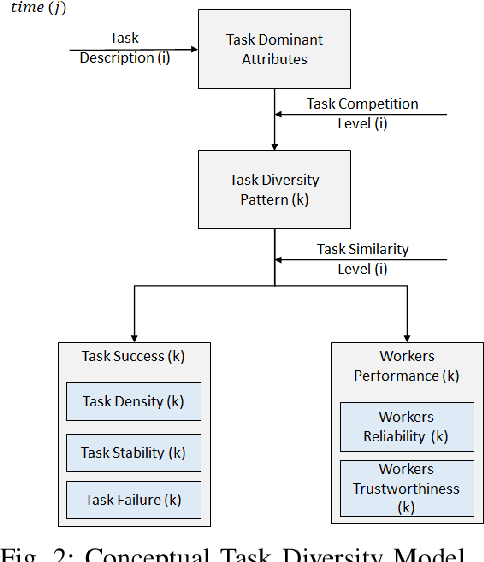
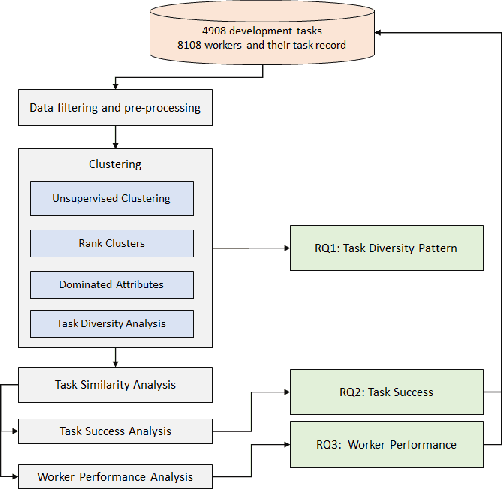
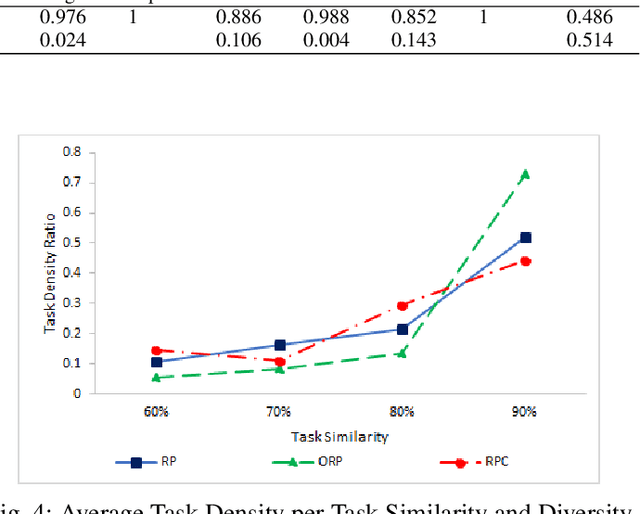
Context: The success of software crowdsourcing depends on steady tasks supply and active worker pool. Existing analysis reveals an average task failure ratio of 15.7% in software crowdsourcing market. Goal: The objective of this study is to empirically investigate patterns and effect of task diversity in software crowdsourcing platform in order to improve the success and efficiency of software crowdsourcing. Method: We propose a conceptual task diversity model, and develop an approach to measuring and analyzing task diversity.More specifically, this includes grouping similar tasks, ranking them based on their competition level and identifying the dominant attributes that distinguish among these levels, and then studying the impact of task diversity on task success and worker performance in crowdsourcing platform. The empirical study is conducted on more than one year's real-world data from TopCoder, the leading software crowdsourcing platform. Results: We identified that monetary prize and task complexity are the dominant attributes that differentiate among different competition levels. Based on these dominant attributes, we found three task diversity patterns (configurations) from workers behavior perspective: responsive to prize, responsive to prize and complexity and over responsive to prize. This study supports that1) responsive to prize configuration provides highest level of task density and workers' reliability in a platform; 2) responsive to prize and complexity configuration leads to attracting high level of trustworthy workers; 3) over responsive to prize configuration results in highest task stability and the lowest failure ratio in the platform for not high similar tasks.
Learned Enrichment of Top-View Grid Maps Improves Object Detection
Mar 09, 2020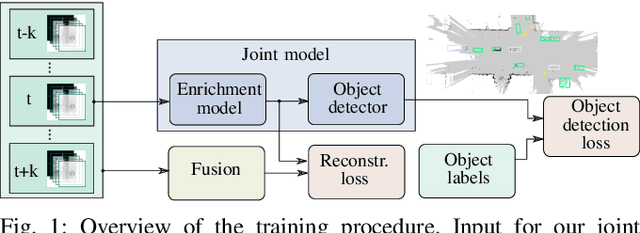

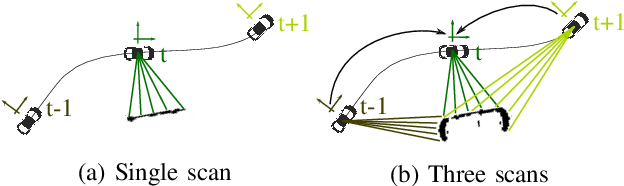

We propose an object detector for top-view grid maps which is additionally trained to generate an enriched version of its input. Our goal in the joint model is to improve generalization by regularizing towards structural knowledge in form of a map fused from multiple adjacent range sensor measurements. This training data can be generated in an automatic fashion, thus does not require manual annotations. We present an evidential framework to generate training data, investigate different model architectures and show that predicting enriched inputs as an additional task can improve object detection performance.
Towards Evidence-Based Ontology for Supporting Systematic Literature Review
Sep 22, 2016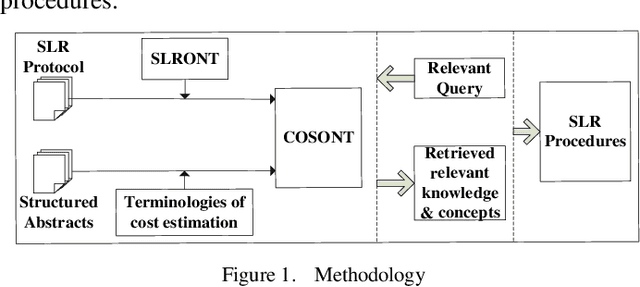

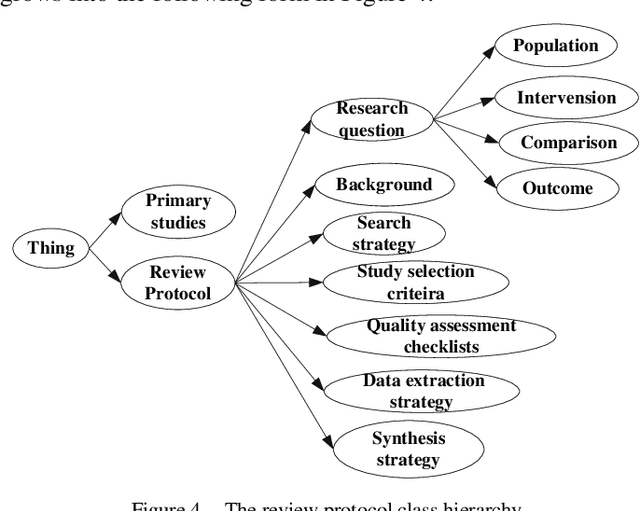

[Background]: Systematic Literature Review (SLR) has become an important software engineering research method but costs tremendous efforts. [Aim]: This paper proposes an approach to leverage on empirically evolved ontology to support automating key SLR activities. [Method]: First, we propose an ontology, SLRONT, built on SLR experiences and best practices as a groundwork to capture common terminologies and their relationships during SLR processes; second, we present an extended version of SLRONT, the COSONT and instantiate it with the knowledge and concepts extracted from structured abstracts. Case studies illustrate the details of applying it for supporting SLR steps. [Results]: Results show that through using COSONT, we acquire the same conclusion compared with sheer manual works, but the efforts involved is significantly reduced. [Conclusions]: The approach of using ontology could effectively and efficiently support the conducting of systematic literature review.