 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Automated Semantic Interpretability in Reinforcement Learning via Vision-Language Models
Mar 20, 2025Semantic Interpretability in Reinforcement Learning (RL) enables transparency, accountability, and safer deployment by making the agent's decisions understandable and verifiable. Achieving this, however, requires a feature space composed of human-understandable concepts, which traditionally rely on human specification and fail to generalize to unseen environments. In this work, we introduce Semantically Interpretable Reinforcement Learning with Vision-Language Models Empowered Automation (SILVA), an automated framework that leverages pre-trained vision-language models (VLM) for semantic feature extraction and interpretable tree-based models for policy optimization. SILVA first queries a VLM to identify relevant semantic features for an unseen environment, then extracts these features from the environment. Finally, it trains an Interpretable Control Tree via RL, mapping the extracted features to actions in a transparent and interpretable manner. To address the computational inefficiency of extracting features directly with VLMs, we develop a feature extraction pipeline that generates a dataset for training a lightweight convolutional network, which is subsequently used during RL. By leveraging VLMs to automate tree-based RL, SILVA removes the reliance on human annotation previously required by interpretable models while also overcoming the inability of VLMs alone to generate valid robot policies, enabling semantically interpretable reinforcement learning without human-in-the-loop.
Towards Learning Scalable Agile Dynamic Motion Planning for Robosoccer Teams with Policy Optimization
Feb 08, 2025In fast-paced, ever-changing environments, dynamic Motion Planning for Multi-Agent Systems in the presence of obstacles is a universal and unsolved problem. Be it from path planning around obstacles to the movement of robotic arms, or in planning navigation of robot teams in settings such as Robosoccer, dynamic motion planning is needed to avoid collisions while reaching the targeted destination when multiple agents occupy the same area. In continuous domains where the world changes quickly, existing classical Motion Planning algorithms such as RRT* and A* become computationally expensive to rerun at every time step. Many variations of classical and well-formulated non-learning path-planning methods have been proposed to solve this universal problem but fall short due to their limitations of speed, smoothness, optimally, etc. Deep Learning models overcome their challenges due to their ability to adapt to varying environments based on past experience. However, current learning motion planning models use discretized environments, do not account for heterogeneous agents or replanning, and build up to improve the classical motion planners' efficiency, leading to issues with scalability. To prevent collisions between heterogenous team members and collision to obstacles while trying to reach the target location, we present a learning-based dynamic navigation model and show our model working on a simple environment in the concept of a simple Robosoccer Game.
Learning Coordination Policies over Heterogeneous Graphs for Human-Robot Teams via Recurrent Neural Schedule Propagation
Jan 30, 2023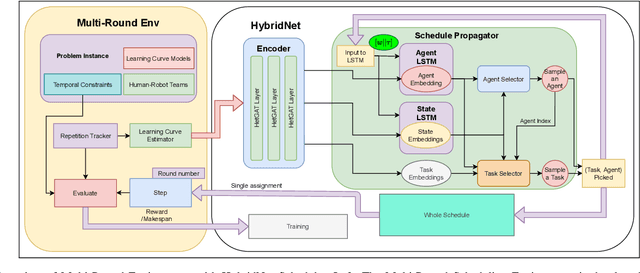
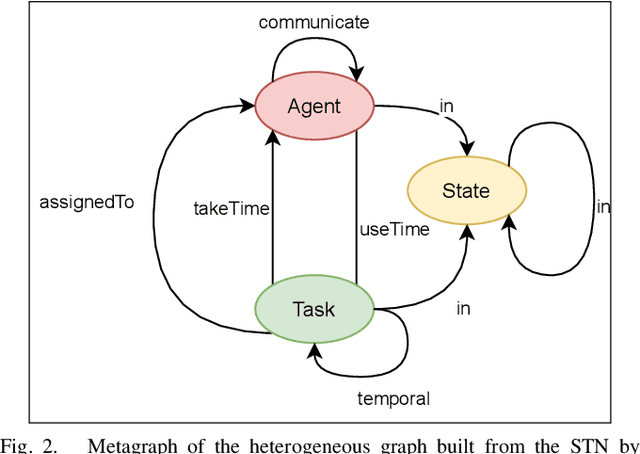
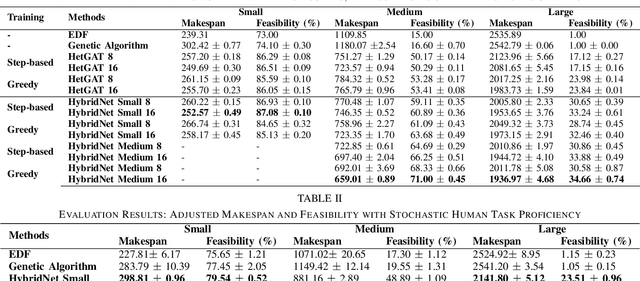
As human-robot collaboration increases in the workforce, it becomes essential for human-robot teams to coordinate efficiently and intuitively. Traditional approaches for human-robot scheduling either utilize exact methods that are intractable for large-scale problems and struggle to account for stochastic, time varying human task performance, or application-specific heuristics that require expert domain knowledge to develop. We propose a deep learning-based framework, called HybridNet, combining a heterogeneous graph-based encoder with a recurrent schedule propagator for scheduling stochastic human-robot teams under upper- and lower-bound temporal constraints. The HybridNet's encoder leverages Heterogeneous Graph Attention Networks to model the initial environment and team dynamics while accounting for the constraints. By formulating task scheduling as a sequential decision-making process, the HybridNet's recurrent neural schedule propagator leverages Long Short-Term Memory (LSTM) models to propagate forward consequences of actions to carry out fast schedule generation, removing the need to interact with the environment between every task-agent pair selection. The resulting scheduling policy network provides a computationally lightweight yet highly expressive model that is end-to-end trainable via Reinforcement Learning algorithms. We develop a virtual task scheduling environment for mixed human-robot teams in a multi-round setting, capable of modeling the stochastic learning behaviors of human workers. Experimental results showed that HybridNet outperformed other human-robot scheduling solutions across problem sizes for both deterministic and stochastic human performance, with faster runtime compared to pure-GNN-based schedulers.
* 8 pages, 2 figures, 3 Tables