 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeakly-Supervised Amodal Instance Segmentation with Compositional Priors
Paper and Code
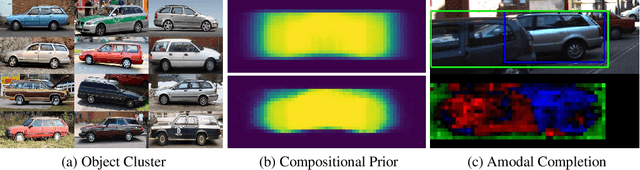


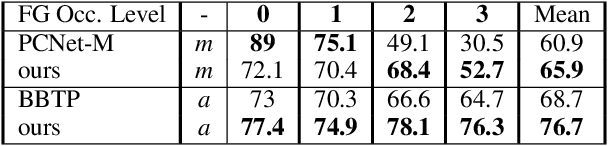
Amodal segmentation in biological vision refers to the perception of the entire object when only a fraction is visible. This ability of seeing through occluders and reasoning about occlusion is innate to biological vision but not adequately modeled in current machine vision approaches. A key challenge is that ground-truth supervisions of amodal object segmentation are inherently difficult to obtain. In this paper, we present a neural network architecture that is capable of amodal perception, when weakly supervised with standard (inmodal) bounding box annotations. Our model extends compositional convolutional neural networks (CompositionalNets), which have been shown to be robust to partial occlusion by explicitly representing objects as composition of parts. In particular, we extend CompositionalNets by: 1) Expanding the innate part-voting mechanism in the CompositionalNets to perform instance segmentation; 2) and by exploiting the internal representations of CompositionalNets to enable amodal completion for both bounding box and segmentation mask. Our extensive experiments show that our proposed model can segment amodal masks robustly, with much improved mask prediction qualities compared to state-of-the-art amodal segmentation approaches.