 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReal-time prediction of breast cancer sites using deformation-aware graph neural network
Nov 17, 2025Early diagnosis of breast cancer is crucial, enabling the establishment of appropriate treatment plans and markedly enhancing patient prognosis. While direct magnetic resonance imaging-guided biopsy demonstrates promising performance in detecting cancer lesions, its practical application is limited by prolonged procedure times and high costs. To overcome these issues, an indirect MRI-guided biopsy that allows the procedure to be performed outside of the MRI room has been proposed, but it still faces challenges in creating an accurate real-time deformable breast model. In our study, we tackled this issue by developing a graph neural network (GNN)-based model capable of accurately predicting deformed breast cancer sites in real time during biopsy procedures. An individual-specific finite element (FE) model was developed by incorporating magnetic resonance (MR) image-derived structural information of the breast and tumor to simulate deformation behaviors. A GNN model was then employed, designed to process surface displacement and distance-based graph data, enabling accurate prediction of overall tissue displacement, including the deformation of the tumor region. The model was validated using phantom and real patient datasets, achieving an accuracy within 0.2 millimeters (mm) for cancer node displacement (RMSE) and a dice similarity coefficient (DSC) of 0.977 for spatial overlap with actual cancerous regions. Additionally, the model enabled real-time inference and achieved a speed-up of over 4,000 times in computational cost compared to conventional FE simulations. The proposed deformation-aware GNN model offers a promising solution for real-time tumor displacement prediction in breast biopsy, with high accuracy and real-time capability. Its integration with clinical procedures could significantly enhance the precision and efficiency of breast cancer diagnosis.
Artificial Intelligence for Pediatric Height Prediction Using Large-Scale Longitudinal Body Composition Data
Apr 09, 2025This study developed an accurate artificial intelligence model for predicting future height in children and adolescents using anthropometric and body composition data from the GP Cohort Study (588,546 measurements from 96,485 children aged 7-18). The model incorporated anthropometric measures, body composition, standard deviation scores, and growth velocity parameters, with performance evaluated using RMSE, MAE, and MAPE. Results showed high accuracy with males achieving average RMSE, MAE, and MAPE of 2.51 cm, 1.74 cm, and 1.14%, and females showing 2.28 cm, 1.68 cm, and 1.13%, respectively. Explainable AI approaches identified height SDS, height velocity, and soft lean mass velocity as crucial predictors. The model generated personalized growth curves by estimating individual-specific height trajectories, offering a robust tool for clinical decision support, early identification of growth disorders, and optimization of growth outcomes.
TALoS: Enhancing Semantic Scene Completion via Test-time Adaptation on the Line of Sight
Oct 21, 2024Semantic Scene Completion (SSC) aims to perform geometric completion and semantic segmentation simultaneously. Despite the promising results achieved by existing studies, the inherently ill-posed nature of the task presents significant challenges in diverse driving scenarios. This paper introduces TALoS, a novel test-time adaptation approach for SSC that excavates the information available in driving environments. Specifically, we focus on that observations made at a certain moment can serve as Ground Truth (GT) for scene completion at another moment. Given the characteristics of the LiDAR sensor, an observation of an object at a certain location confirms both 1) the occupation of that location and 2) the absence of obstacles along the line of sight from the LiDAR to that point. TALoS utilizes these observations to obtain self-supervision about occupancy and emptiness, guiding the model to adapt to the scene in test time. In a similar manner, we aggregate reliable SSC predictions among multiple moments and leverage them as semantic pseudo-GT for adaptation. Further, to leverage future observations that are not accessible at the current time, we present a dual optimization scheme using the model in which the update is delayed until the future observation is available. Evaluations on the SemanticKITTI validation and test sets demonstrate that TALoS significantly improves the performance of the pre-trained SSC model. Our code is available at https://github.com/blue-531/TALoS.
Long-Tailed Recognition on Binary Networks by Calibrating A Pre-trained Model
Mar 30, 2024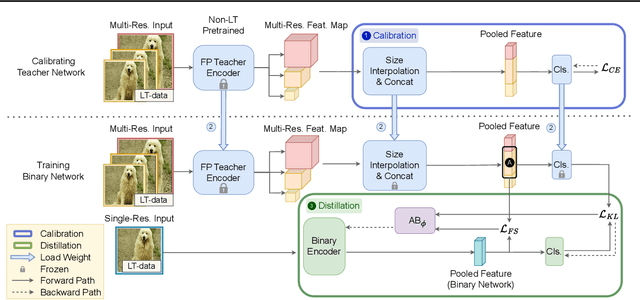
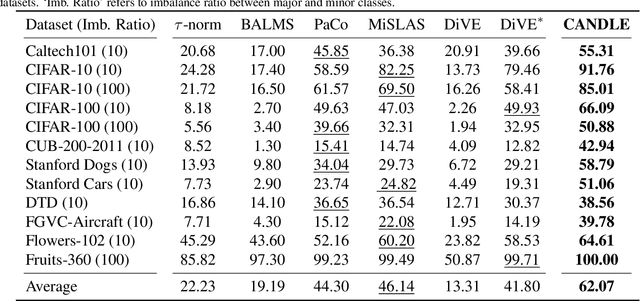
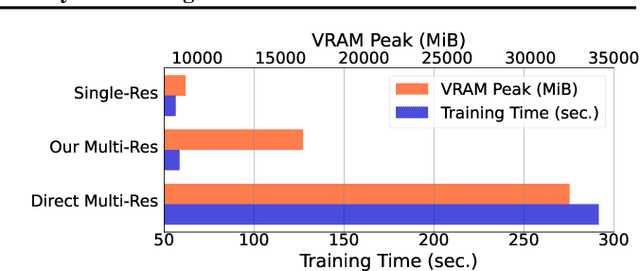

Deploying deep models in real-world scenarios entails a number of challenges, including computational efficiency and real-world (e.g., long-tailed) data distributions. We address the combined challenge of learning long-tailed distributions using highly resource-efficient binary neural networks as backbones. Specifically, we propose a calibrate-and-distill framework that uses off-the-shelf pretrained full-precision models trained on balanced datasets to use as teachers for distillation when learning binary networks on long-tailed datasets. To better generalize to various datasets, we further propose a novel adversarial balancing among the terms in the objective function and an efficient multiresolution learning scheme. We conducted the largest empirical study in the literature using 15 datasets, including newly derived long-tailed datasets from existing balanced datasets, and show that our proposed method outperforms prior art by large margins (>14.33% on average).
Efficient Model Agnostic Approach for Implicit Neural Representation Based Arbitrary-Scale Image Super-Resolution
Nov 20, 2023Single image super-resolution (SISR) has experienced significant advancements, primarily driven by deep convolutional networks. Traditional networks, however, are limited to upscaling images to a fixed scale, leading to the utilization of implicit neural functions for generating arbitrarily scaled images. Nevertheless, these methodologies have imposed substantial computational demands as they involve querying every target pixel to a single resource-intensive decoder. In this paper, we introduce a novel and efficient framework, the Mixture of Experts Implicit Super-Resolution (MoEISR), which enables super-resolution at arbitrary scales with significantly increased computational efficiency without sacrificing reconstruction quality. MoEISR dynamically allocates the most suitable decoding expert to each pixel using a lightweight mapper module, allowing experts with varying capacities to reconstruct pixels across regions with diverse complexities. Our experiments demonstrate that MoEISR successfully reduces up to 73% in floating point operations (FLOPs) while delivering comparable or superior peak signal-to-noise ratio (PSNR).
Deep Learning-based Synthetic High-Resolution In-Depth Imaging Using an Attachable Dual-element Endoscopic Ultrasound Probe
Sep 13, 2023



Endoscopic ultrasound (EUS) imaging has a trade-off between resolution and penetration depth. By considering the in-vivo characteristics of human organs, it is necessary to provide clinicians with appropriate hardware specifications for precise diagnosis. Recently, super-resolution (SR) ultrasound imaging studies, including the SR task in deep learning fields, have been reported for enhancing ultrasound images. However, most of those studies did not consider ultrasound imaging natures, but rather they were conventional SR techniques based on downsampling of ultrasound images. In this study, we propose a novel deep learning-based high-resolution in-depth imaging probe capable of offering low- and high-frequency ultrasound image pairs. We developed an attachable dual-element EUS probe with customized low- and high-frequency ultrasound transducers under small hardware constraints. We also designed a special geared structure to enable the same image plane. The proposed system was evaluated with a wire phantom and a tissue-mimicking phantom. After the evaluation, 442 ultrasound image pairs from the tissue-mimicking phantom were acquired. We then applied several deep learning models to obtain synthetic high-resolution in-depth images, thus demonstrating the feasibility of our approach for clinical unmet needs. Furthermore, we quantitatively and qualitatively analyzed the results to find a suitable deep-learning model for our task. The obtained results demonstrate that our proposed dual-element EUS probe with an image-to-image translation network has the potential to provide synthetic high-frequency ultrasound images deep inside tissues.
Towards a real-time continuous ultrafast ultrasound beamformer with programmable logic
Aug 06, 2022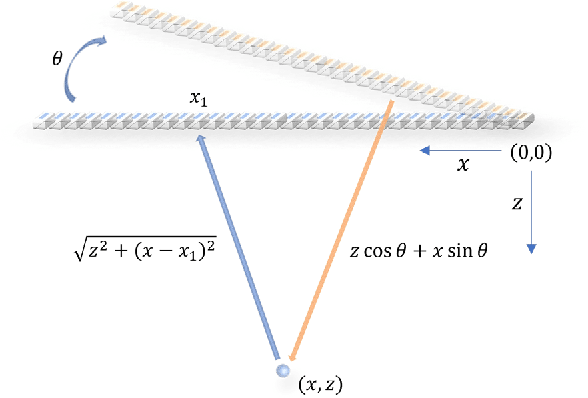
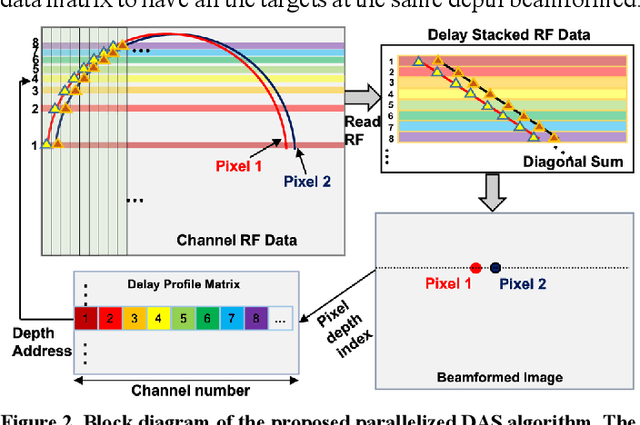
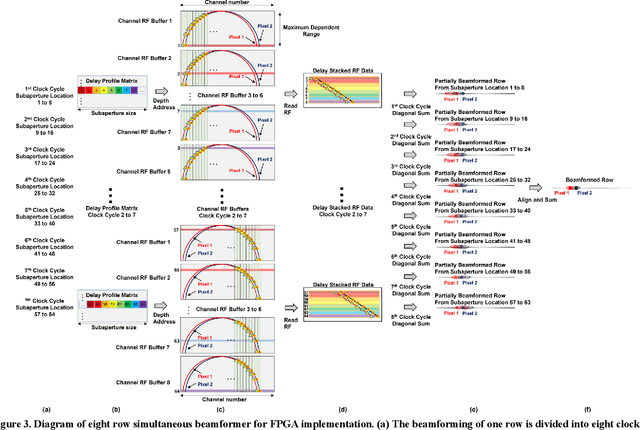
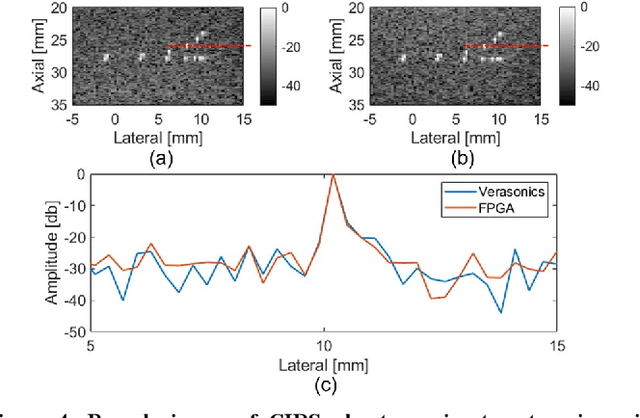
Ultrafast ultrasound imaging is essential for advanced ultrasound imaging techniques such as ultrasound localization microscopy (ULM) and functional ultrasound (fUS). Current ultrafast ultrasound imaging is challenged by the ultrahigh data bandwidth associated with the radio frequency (RF) signal, and by the latency of the computationally expensive beamforming process. As such, continuous ultrafast data acquisition and beamforming remain elusive with existing software beamformers based on CPUs or GPUs. To address these challenges, the proposed work introduces a hybrid solution composed of an improved delay and sum (DAS) algorithm with high hardware efficiency and an ultrafast beamformer based on the field programmable gate array (FPGA). Our proposed method presents two unique advantages over conventional FPGA-based beamformers: 1) high scalability that allows fast adaptation to different FPGA platforms; 2) high adaptability to different imaging probes and applications thanks to the absence of hard-coded imaging parameters. With the proposed method, we measured an ultrafast beamforming frame rate of over 3.38 GPixels/second. The performance of the proposed beamformer was compared with the software beamformer on the Verasonics Vantage system for both phantom imaging and in vivo imaging of a mouse brain. Multiple imaging schemes including B-mode, power Doppler and ULM were evaluated with the proposed solution.
6MapNet: Representing soccer players from tracking data by a triplet network
Sep 10, 2021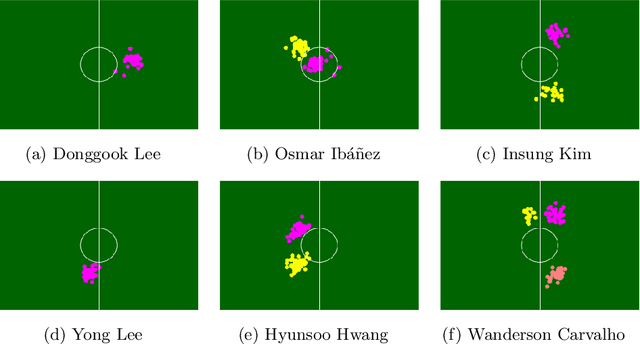
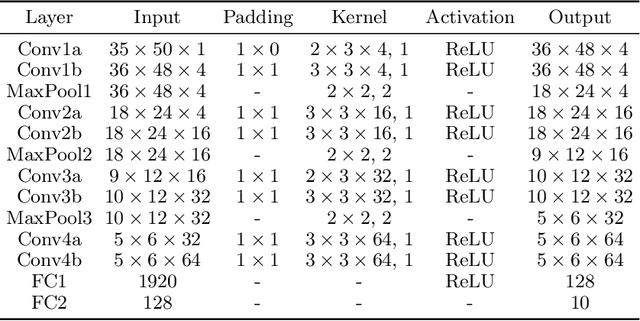
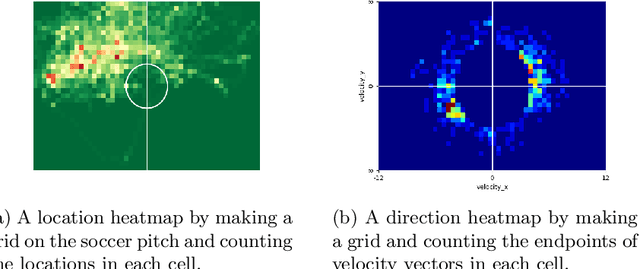
Although the values of individual soccer players have become astronomical, subjective judgments still play a big part in the player analysis. Recently, there have been new attempts to quantitatively grasp players' styles using video-based event stream data. However, they have some limitations in scalability due to high annotation costs and sparsity of event stream data. In this paper, we build a triplet network named 6MapNet that can effectively capture the movement styles of players using in-game GPS data. Without any annotation of soccer-specific actions, we use players' locations and velocities to generate two types of heatmaps. Our subnetworks then map these heatmap pairs into feature vectors whose similarity corresponds to the actual similarity of playing styles. The experimental results show that players can be accurately identified with only a small number of matches by our method.
Two-Stage Generative Adversarial Networks for Document Image Binarization with Color Noise and Background Removal
Oct 20, 2020
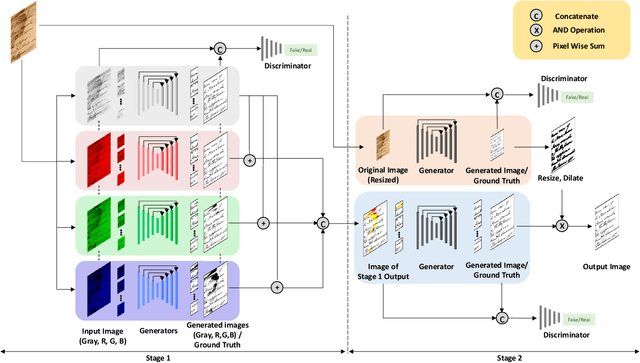
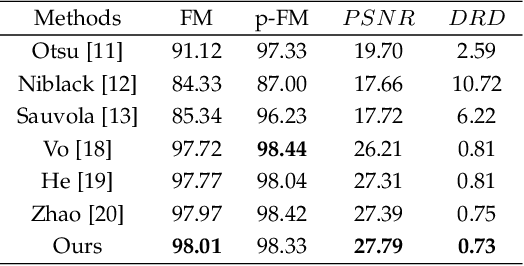

Document image enhancement and binarization methods are often used to improve the accuracy and efficiency of document image analysis tasks such as text recognition. Traditional non-machine-learning methods are constructed on low-level features in an unsupervised manner but have difficulty with binarization on documents with severely degraded backgrounds. Convolutional neural network-based methods focus only on grayscale images and on local textual features. In this paper, we propose a two-stage color document image enhancement and binarization method using generative adversarial neural networks. In the first stage, four color-independent adversarial networks are trained to extract color foreground information from an input image for document image enhancement. In the second stage, two independent adversarial networks with global and local features are trained for image binarization of documents of variable size. For the adversarial neural networks, we formulate loss functions between a discriminator and generators having an encoder-decoder structure. Experimental results show that the proposed method achieves better performance than many classical and state-of-the-art algorithms over the Document Image Binarization Contest (DIBCO) datasets, the LRDE Document Binarization Dataset (LRDE DBD), and our shipping label image dataset.