 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding LoRA as Knowledge Memory: An Empirical Analysis
Mar 01, 2026Continuous knowledge updating for pre-trained large language models (LLMs) is increasingly necessary yet remains challenging. Although inference-time methods like In-Context Learning (ICL) and Retrieval-Augmented Generation (RAG) are popular, they face constraints in context budgets, costs, and retrieval fragmentation. Departing from these context-dependent paradigms, this work investigates a parametric approach using Low-Rank Adaptation (LoRA) as a modular knowledge memory. Although few recent works examine this concept, the fundamental mechanics governing its capacity and composability remain largely unexplored. We bridge this gap through the first systematic empirical study mapping the design space of LoRA-based memory, ranging from characterizing storage capacity and optimizing internalization to scaling multi-module systems and evaluating long-context reasoning. Rather than proposing a single architecture, we provide practical guidance on the operational boundaries of LoRA memory. Overall, our findings position LoRA as the complementary axis of memory alongside RAG and ICL, offering distinct advantages.
NavFormer: IGRF Forecasting in Moving Coordinate Frames
Jan 14, 2026Triad magnetometer components change with sensor attitude even when the IGRF total intensity target stays invariant. NavFormer forecasts this invariant target with rotation invariant scalar features and a Canonical SPD module that stabilizes the spectrum of window level second moments of the triads without sign discontinuities. The module builds a canonical frame from a Gram matrix per window and applies state dependent spectral scaling in the original coordinates. Experiments across five flights show lower error than strong baselines in standard training, few shot training, and zero shot transfer. The code is available at: https://anonymous.4open.science/r/NavFormer-Robust-IGRF-Forecasting-for-Autonomous-Navigators-0765
Bayesian Neural Scaling Laws Extrapolation with Prior-Fitted Networks
May 29, 2025



Scaling has been a major driver of recent advancements in deep learning. Numerous empirical studies have found that scaling laws often follow the power-law and proposed several variants of power-law functions to predict the scaling behavior at larger scales. However, existing methods mostly rely on point estimation and do not quantify uncertainty, which is crucial for real-world applications involving decision-making problems such as determining the expected performance improvements achievable by investing additional computational resources. In this work, we explore a Bayesian framework based on Prior-data Fitted Networks (PFNs) for neural scaling law extrapolation. Specifically, we design a prior distribution that enables the sampling of infinitely many synthetic functions resembling real-world neural scaling laws, allowing our PFN to meta-learn the extrapolation. We validate the effectiveness of our approach on real-world neural scaling laws, comparing it against both the existing point estimation methods and Bayesian approaches. Our method demonstrates superior performance, particularly in data-limited scenarios such as Bayesian active learning, underscoring its potential for reliable, uncertainty-aware extrapolation in practical applications.
Adaptive Cyclic Diffusion for Inference Scaling
May 20, 2025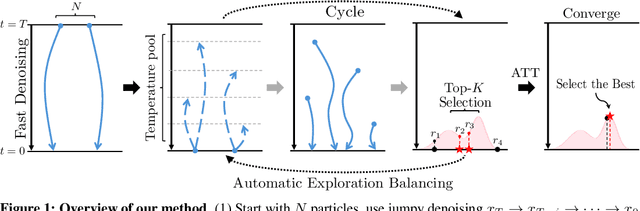

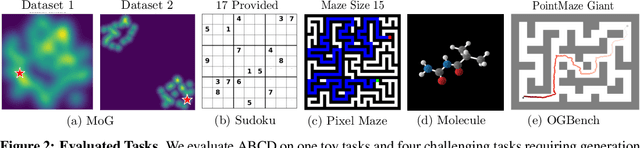
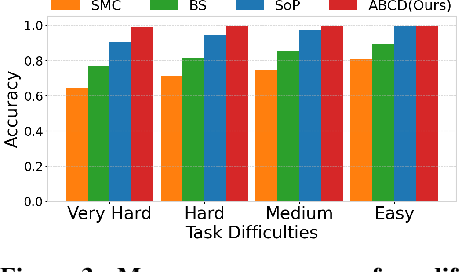
Diffusion models have demonstrated strong generative capabilities across domains ranging from image synthesis to complex reasoning tasks. However, most inference-time scaling methods rely on fixed denoising schedules, limiting their ability to allocate computation based on instance difficulty or task-specific demands adaptively. We introduce the challenge of adaptive inference-time scaling-dynamically adjusting computational effort during inference-and propose Adaptive Bi-directional Cyclic Diffusion (ABCD), a flexible, search-based inference framework. ABCD refines outputs through bi-directional diffusion cycles while adaptively controlling exploration depth and termination. It comprises three components: Cyclic Diffusion Search, Automatic Exploration-Exploitation Balancing, and Adaptive Thinking Time. Experiments show that ABCD improves performance across diverse tasks while maintaining computational efficiency.
CytoFM: The first cytology foundation model
Apr 18, 2025Cytology is essential for cancer diagnostics and screening due to its minimally invasive nature. However, the development of robust deep learning models for digital cytology is challenging due to the heterogeneity in staining and preparation methods of samples, differences across organs, and the limited availability of large, diverse, annotated datasets. Developing a task-specific model for every cytology application is impractical and non-cytology-specific foundation models struggle to generalize to tasks in this domain where the emphasis is on cell morphology. To address these challenges, we introduce CytoFM, the first cytology self-supervised foundation model. Using iBOT, a self-supervised Vision Transformer (ViT) training framework incorporating masked image modeling and self-distillation, we pretrain CytoFM on a diverse collection of cytology datasets to learn robust, transferable representations. We evaluate CytoFM on multiple downstream cytology tasks, including breast cancer classification and cell type identification, using an attention-based multiple instance learning framework. Our results demonstrate that CytoFM performs better on two out of three downstream tasks than existing foundation models pretrained on histopathology (UNI) or natural images (iBOT-Imagenet). Visualizations of learned representations demonstrate our model is able to attend to cytologically relevant features. Despite a small pre-training dataset, CytoFM's promising results highlight the ability of task-agnostic pre-training approaches to learn robust and generalizable features from cytology data.
GS-Blur: A 3D Scene-Based Dataset for Realistic Image Deblurring
Oct 31, 2024
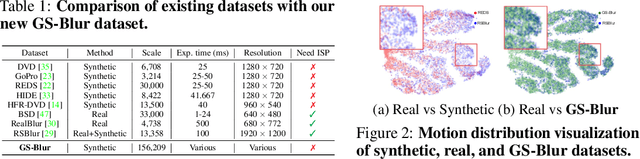

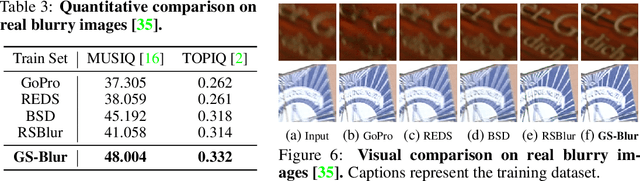
To train a deblurring network, an appropriate dataset with paired blurry and sharp images is essential. Existing datasets collect blurry images either synthetically by aggregating consecutive sharp frames or using sophisticated camera systems to capture real blur. However, these methods offer limited diversity in blur types (blur trajectories) or require extensive human effort to reconstruct large-scale datasets, failing to fully reflect real-world blur scenarios. To address this, we propose GS-Blur, a dataset of synthesized realistic blurry images created using a novel approach. To this end, we first reconstruct 3D scenes from multi-view images using 3D Gaussian Splatting (3DGS), then render blurry images by moving the camera view along the randomly generated motion trajectories. By adopting various camera trajectories in reconstructing our GS-Blur, our dataset contains realistic and diverse types of blur, offering a large-scale dataset that generalizes well to real-world blur. Using GS-Blur with various deblurring methods, we demonstrate its ability to generalize effectively compared to previous synthetic or real blur datasets, showing significant improvements in deblurring performance.
DeblurGS: Gaussian Splatting for Camera Motion Blur
Apr 18, 2024Although significant progress has been made in reconstructing sharp 3D scenes from motion-blurred images, a transition to real-world applications remains challenging. The primary obstacle stems from the severe blur which leads to inaccuracies in the acquisition of initial camera poses through Structure-from-Motion, a critical aspect often overlooked by previous approaches. To address this challenge, we propose DeblurGS, a method to optimize sharp 3D Gaussian Splatting from motion-blurred images, even with the noisy camera pose initialization. We restore a fine-grained sharp scene by leveraging the remarkable reconstruction capability of 3D Gaussian Splatting. Our approach estimates the 6-Degree-of-Freedom camera motion for each blurry observation and synthesizes corresponding blurry renderings for the optimization process. Furthermore, we propose Gaussian Densification Annealing strategy to prevent the generation of inaccurate Gaussians at erroneous locations during the early training stages when camera motion is still imprecise. Comprehensive experiments demonstrate that our DeblurGS achieves state-of-the-art performance in deblurring and novel view synthesis for real-world and synthetic benchmark datasets, as well as field-captured blurry smartphone videos.
ExBluRF: Efficient Radiance Fields for Extreme Motion Blurred Images
Sep 21, 2023



We present ExBluRF, a novel view synthesis method for extreme motion blurred images based on efficient radiance fields optimization. Our approach consists of two main components: 6-DOF camera trajectory-based motion blur formulation and voxel-based radiance fields. From extremely blurred images, we optimize the sharp radiance fields by jointly estimating the camera trajectories that generate the blurry images. In training, multiple rays along the camera trajectory are accumulated to reconstruct single blurry color, which is equivalent to the physical motion blur operation. We minimize the photo-consistency loss on blurred image space and obtain the sharp radiance fields with camera trajectories that explain the blur of all images. The joint optimization on the blurred image space demands painfully increasing computation and resources proportional to the blur size. Our method solves this problem by replacing the MLP-based framework to low-dimensional 6-DOF camera poses and voxel-based radiance fields. Compared with the existing works, our approach restores much sharper 3D scenes from challenging motion blurred views with the order of 10 times less training time and GPU memory consumption.
DATa: Domain Adaptation-Aided Deep Table Detection Using Visual-Lexical Representations
Nov 12, 2022



Considerable research attention has been paid to table detection by developing not only rule-based approaches reliant on hand-crafted heuristics but also deep learning approaches. Although recent studies successfully perform table detection with enhanced results, they often experience performance degradation when they are used for transferred domains whose table layout features might differ from the source domain in which the underlying model has been trained. To overcome this problem, we present DATa, a novel Domain Adaptation-aided deep Table detection method that guarantees satisfactory performance in a specific target domain where few trusted labels are available. To this end, we newly design lexical features and an augmented model used for re-training. More specifically, after pre-training one of state-of-the-art vision-based models as our backbone network, we re-train our augmented model, consisting of the vision-based model and the multilayer perceptron (MLP) architecture. Using new confidence scores acquired based on the trained MLP architecture as well as an initial prediction of bounding boxes and their confidence scores, we calculate each confidence score more accurately. To validate the superiority of DATa, we perform experimental evaluations by adopting a real-world benchmark dataset in a source domain and another dataset in our target domain consisting of materials science articles. Experimental results demonstrate that the proposed DATa method substantially outperforms competing methods that only utilize visual representations in the target domain. Such gains are possible owing to the capability of eliminating high false positives or false negatives according to the setting of a confidence score threshold.
Joint Blind Motion Deblurring and Depth Estimation of Light Field
Jun 14, 2018
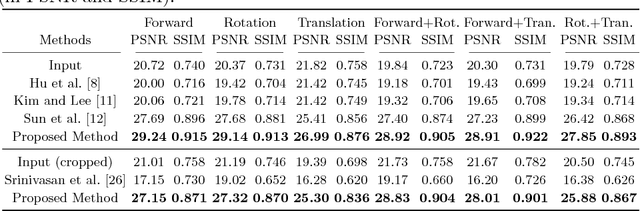
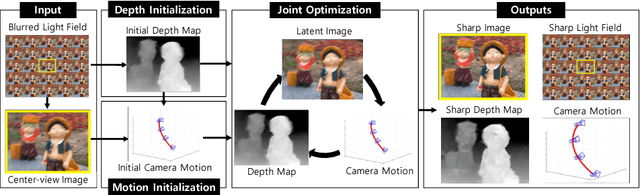
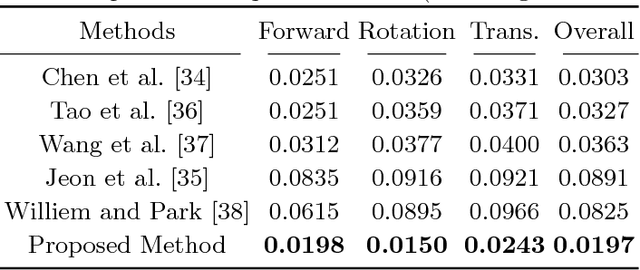
Removing camera motion blur from a single light field is a challenging task since it is highly ill-posed inverse problem. The problem becomes even worse when blur kernel varies spatially due to scene depth variation and high-order camera motion. In this paper, we propose a novel algorithm to estimate all blur model variables jointly, including latent sub-aperture image, camera motion, and scene depth from the blurred 4D light field. Exploiting multi-view nature of a light field relieves the inverse property of the optimization by utilizing strong depth cues and multi-view blur observation. The proposed joint estimation achieves high quality light field deblurring and depth estimation simultaneously under arbitrary 6-DOF camera motion and unconstrained scene depth. Intensive experiment on real and synthetic blurred light field confirms that the proposed algorithm outperforms the state-of-the-art light field deblurring and depth estimation methods.