 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge$α$-PFN: Fast Entropy Search via In-Context Learning
Jun 05, 2026Information-theoretic acquisition functions such as Entropy Search (ES) offer a principled exploration-exploitation framework for Bayesian optimization (BO). However, their practical implementation relies on complicated and slow approximations, i.e., a Monte Carlo estimation of the information gain. This complexity can introduce numerical errors and requires specialized, hand-crafted implementations. We propose a two-stage amortization strategy that learns to approximate entropy search-based acquisition functions using Prior-data Fitted Networks (PFNs) in a single forward pass. A first PFN is trained to be conditioned on information about the optima; second, the $α$-PFN is trained to predict the expected information gain by training on information gains measured with the first PFN. The $α$-PFN offers a flexible learned approximation, which replaces the complex heuristic approximations with a single forward pass per candidate, enabling rapid and extensible acquisition evaluation. Empirically, our approach is competitive with state-of-the-art entropy search implementations on synthetic and real-world benchmarks, while accelerating the different entropy search variants across all our experiments, with speed ups over 50x. Source code: https://github.com/automl/AlphaPFN.
Tune My Adam, Please!
Aug 28, 2025The Adam optimizer remains one of the most widely used optimizers in deep learning, and effectively tuning its hyperparameters is key to optimizing performance. However, tuning can be tedious and costly. Freeze-thaw Bayesian Optimization (BO) is a recent promising approach for low-budget hyperparameter tuning, but is limited by generic surrogates without prior knowledge of how hyperparameters affect learning. We propose Adam-PFN, a new surrogate model for Freeze-thaw BO of Adam's hyperparameters, pre-trained on learning curves from TaskSet, together with a new learning curve augmentation method, CDF-augment, which artificially increases the number of available training examples. Our approach improves both learning curve extrapolation and accelerates hyperparameter optimization on TaskSet evaluation tasks, with strong performance on out-of-distribution (OOD) tasks.
Bayesian Neural Scaling Laws Extrapolation with Prior-Fitted Networks
May 29, 2025



Scaling has been a major driver of recent advancements in deep learning. Numerous empirical studies have found that scaling laws often follow the power-law and proposed several variants of power-law functions to predict the scaling behavior at larger scales. However, existing methods mostly rely on point estimation and do not quantify uncertainty, which is crucial for real-world applications involving decision-making problems such as determining the expected performance improvements achievable by investing additional computational resources. In this work, we explore a Bayesian framework based on Prior-data Fitted Networks (PFNs) for neural scaling law extrapolation. Specifically, we design a prior distribution that enables the sampling of infinitely many synthetic functions resembling real-world neural scaling laws, allowing our PFN to meta-learn the extrapolation. We validate the effectiveness of our approach on real-world neural scaling laws, comparing it against both the existing point estimation methods and Bayesian approaches. Our method demonstrates superior performance, particularly in data-limited scenarios such as Bayesian active learning, underscoring its potential for reliable, uncertainty-aware extrapolation in practical applications.
Gompertz Linear Units: Leveraging Asymmetry for Enhanced Learning Dynamics
Feb 05, 2025



Activation functions are fundamental elements of deep learning architectures as they significantly influence training dynamics. ReLU, while widely used, is prone to the dying neuron problem, which has been mitigated by variants such as LeakyReLU, PReLU, and ELU that better handle negative neuron outputs. Recently, self-gated activations like GELU and Swish have emerged as state-of-the-art alternatives, leveraging their smoothness to ensure stable gradient flow and prevent neuron inactivity. In this work, we introduce the Gompertz Linear Unit (GoLU), a novel self-gated activation function defined as $\mathrm{GoLU}(x) = x \, \mathrm{Gompertz}(x)$, where $\mathrm{Gompertz}(x) = e^{-e^{-x}}$. The GoLU activation leverages the asymmetry in the Gompertz function to reduce variance in the latent space more effectively compared to GELU and Swish, while preserving robust gradient flow. Extensive experiments across diverse tasks, including Image Classification, Language Modeling, Semantic Segmentation, Object Detection, Instance Segmentation, and Diffusion, highlight GoLU's superior performance relative to state-of-the-art activation functions, establishing GoLU as a robust alternative to existing activation functions.
In-Context Freeze-Thaw Bayesian Optimization for Hyperparameter Optimization
Apr 25, 2024



With the increasing computational costs associated with deep learning, automated hyperparameter optimization methods, strongly relying on black-box Bayesian optimization (BO), face limitations. Freeze-thaw BO offers a promising grey-box alternative, strategically allocating scarce resources incrementally to different configurations. However, the frequent surrogate model updates inherent to this approach pose challenges for existing methods, requiring retraining or fine-tuning their neural network surrogates online, introducing overhead, instability, and hyper-hyperparameters. In this work, we propose FT-PFN, a novel surrogate for Freeze-thaw style BO. FT-PFN is a prior-data fitted network (PFN) that leverages the transformers' in-context learning ability to efficiently and reliably do Bayesian learning curve extrapolation in a single forward pass. Our empirical analysis across three benchmark suites shows that the predictions made by FT-PFN are more accurate and 10-100 times faster than those of the deep Gaussian process and deep ensemble surrogates used in previous work. Furthermore, we show that, when combined with our novel acquisition mechanism (MFPI-random), the resulting in-context freeze-thaw BO method (ifBO), yields new state-of-the-art performance in the same three families of deep learning HPO benchmarks considered in prior work.
Efficient Bayesian Learning Curve Extrapolation using Prior-Data Fitted Networks
Oct 31, 2023Learning curve extrapolation aims to predict model performance in later epochs of training, based on the performance in earlier epochs. In this work, we argue that, while the inherent uncertainty in the extrapolation of learning curves warrants a Bayesian approach, existing methods are (i) overly restrictive, and/or (ii) computationally expensive. We describe the first application of prior-data fitted neural networks (PFNs) in this context. A PFN is a transformer, pre-trained on data generated from a prior, to perform approximate Bayesian inference in a single forward pass. We propose LC-PFN, a PFN trained to extrapolate 10 million artificial right-censored learning curves generated from a parametric prior proposed in prior art using MCMC. We demonstrate that LC-PFN can approximate the posterior predictive distribution more accurately than MCMC, while being over 10 000 times faster. We also show that the same LC-PFN achieves competitive performance extrapolating a total of 20 000 real learning curves from four learning curve benchmarks (LCBench, NAS-Bench-201, Taskset, and PD1) that stem from training a wide range of model architectures (MLPs, CNNs, RNNs, and Transformers) on 53 different datasets with varying input modalities (tabular, image, text, and protein data). Finally, we investigate its potential in the context of model selection and find that a simple LC-PFN based predictive early stopping criterion obtains 2 - 6x speed-ups on 45 of these datasets, at virtually no overhead.
Automated Dynamic Algorithm Configuration
May 27, 2022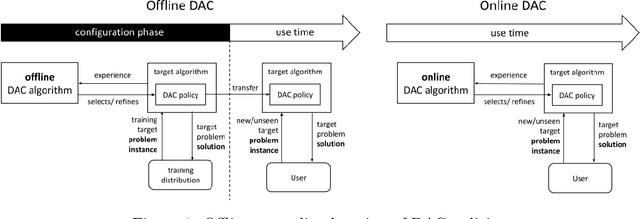

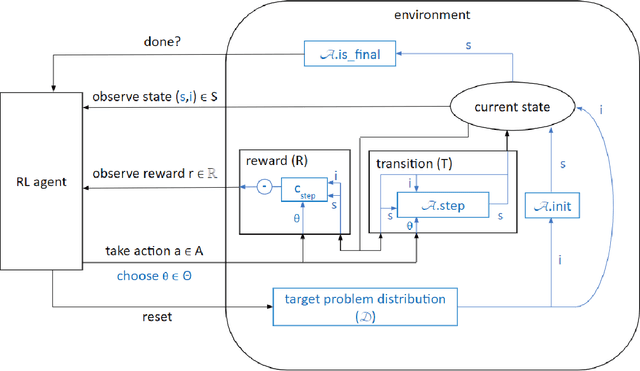
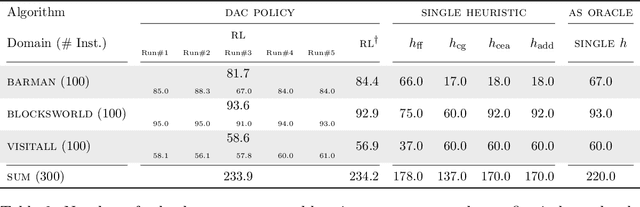
The performance of an algorithm often critically depends on its parameter configuration. While a variety of automated algorithm configuration methods have been proposed to relieve users from the tedious and error-prone task of manually tuning parameters, there is still a lot of untapped potential as the learned configuration is static, i.e., parameter settings remain fixed throughout the run. However, it has been shown that some algorithm parameters are best adjusted dynamically during execution, e.g., to adapt to the current part of the optimization landscape. Thus far, this is most commonly achieved through hand-crafted heuristics. A promising recent alternative is to automatically learn such dynamic parameter adaptation policies from data. In this article, we give the first comprehensive account of this new field of automated dynamic algorithm configuration (DAC), present a series of recent advances, and provide a solid foundation for future research in this field. Specifically, we (i) situate DAC in the broader historical context of AI research; (ii) formalize DAC as a computational problem; (iii) identify the methods used in prior-art to tackle this problem; (iv) conduct empirical case studies for using DAC in evolutionary optimization, AI planning, and machine learning.
DACBench: A Benchmark Library for Dynamic Algorithm Configuration
May 18, 2021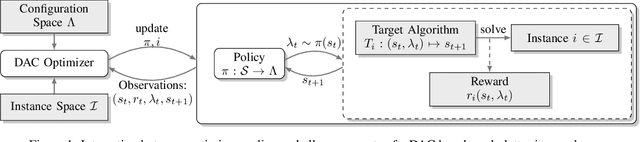
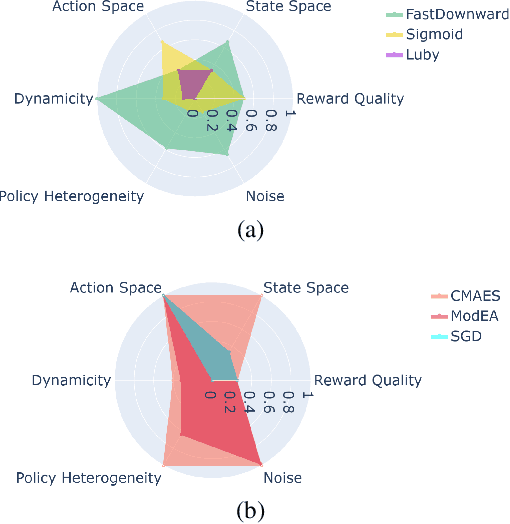
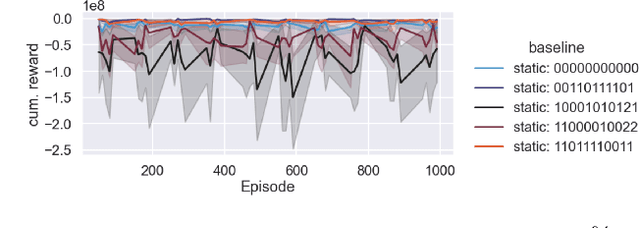
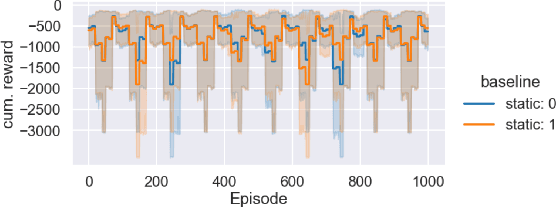
Dynamic Algorithm Configuration (DAC) aims to dynamically control a target algorithm's hyperparameters in order to improve its performance. Several theoretical and empirical results have demonstrated the benefits of dynamically controlling hyperparameters in domains like evolutionary computation, AI Planning or deep learning. Replicating these results, as well as studying new methods for DAC, however, is difficult since existing benchmarks are often specialized and incompatible with the same interfaces. To facilitate benchmarking and thus research on DAC, we propose DACBench, a benchmark library that seeks to collect and standardize existing DAC benchmarks from different AI domains, as well as provide a template for new ones. For the design of DACBench, we focused on important desiderata, such as (i) flexibility, (ii) reproducibility, (iii) extensibility and (iv) automatic documentation and visualization. To show the potential, broad applicability and challenges of DAC, we explore how a set of six initial benchmarks compare in several dimensions of difficulty.
Metaheuristics "In the Large"
Dec 18, 2020Following decades of sustained improvement, metaheuristics are one of the great success stories of optimization research. However, in order for research in metaheuristics to avoid fragmentation and a lack of reproducibility, there is a pressing need for stronger scientific and computational infrastructure to support the development, analysis and comparison of new approaches. We argue that, via principled choice of infrastructure support, the field can pursue a higher level of scientific enquiry. We describe our vision and report on progress, showing how the adoption of common protocols for all metaheuristics can help liberate the potential of the field, easing the exploration of the design space of metaheuristics.