 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluation Metrics for Automated Typographic Poster Generation
Feb 10, 2024Computational Design approaches facilitate the generation of typographic design, but evaluating these designs remains a challenging task. In this paper, we propose a set of heuristic metrics for typographic design evaluation, focusing on their legibility, which assesses the text visibility, aesthetics, which evaluates the visual quality of the design, and semantic features, which estimate how effectively the design conveys the content semantics. We experiment with a constrained evolutionary approach for generating typographic posters, incorporating the proposed evaluation metrics with varied setups, and treating the legibility metrics as constraints. We also integrate emotion recognition to identify text semantics automatically and analyse the performance of the approach and the visual characteristics outputs.
Metaheuristics "In the Large"
Dec 18, 2020Following decades of sustained improvement, metaheuristics are one of the great success stories of optimization research. However, in order for research in metaheuristics to avoid fragmentation and a lack of reproducibility, there is a pressing need for stronger scientific and computational infrastructure to support the development, analysis and comparison of new approaches. We argue that, via principled choice of infrastructure support, the field can pursue a higher level of scientific enquiry. We describe our vision and report on progress, showing how the adoption of common protocols for all metaheuristics can help liberate the potential of the field, easing the exploration of the design space of metaheuristics.
Emerging archetypes in massive artificial societies for literary purposes using genetic algorithms
Mar 12, 2014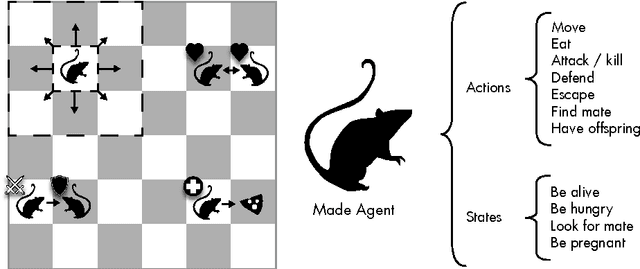

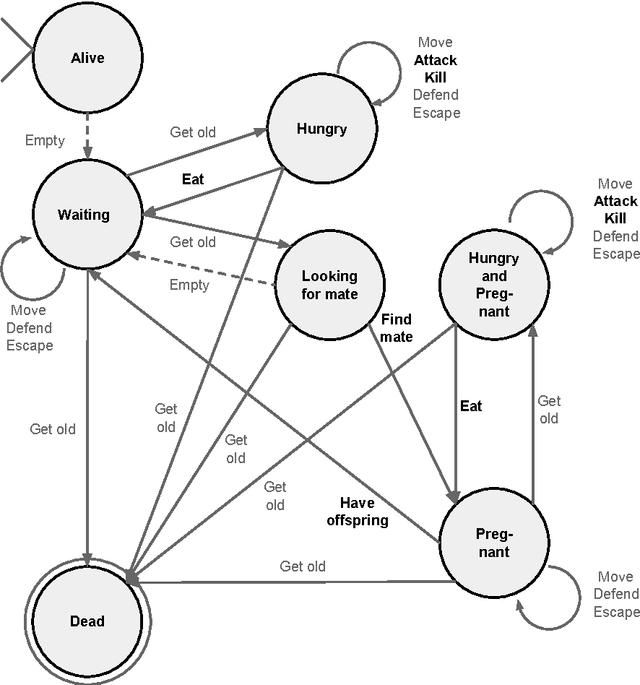

The creation of fictional stories is a very complex task that usually implies a creative process where the author has to combine characters, conflicts and plots to create an engaging narrative. This work presents a simulated environment with hundreds of characters that allows the study of coherent and interesting literary archetypes (or behaviours), plots and sub-plots. We will use this environment to perform a study about the number of profiles (parameters that define the personality of a character) needed to create two emergent scenes of archetypes: "natality control" and "revenge". A Genetic Algorithm (GA) will be used to find the fittest number of profiles and parameter configuration that enables the existence of the desired archetypes (played by the characters without their explicit knowledge). The results show that parametrizing this complex system is possible and that these kind of archetypes can emerge in the given environment.
An experimental study of exhaustive solutions for the Mastermind puzzle
Jul 05, 2012
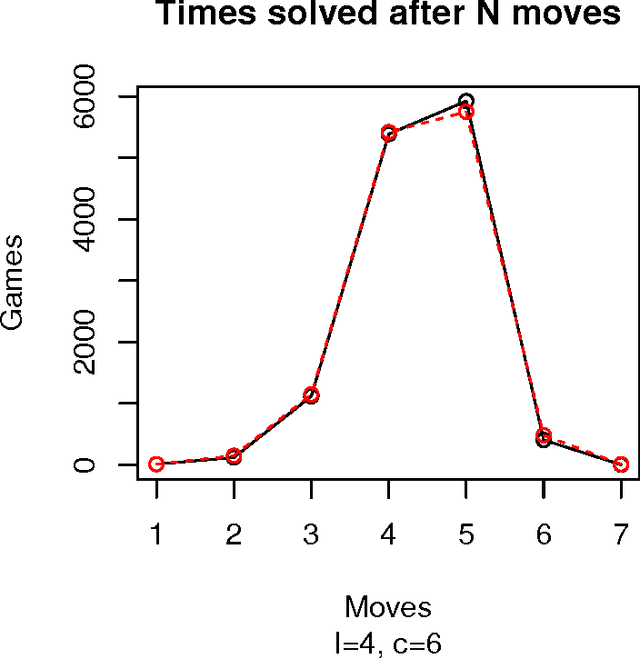
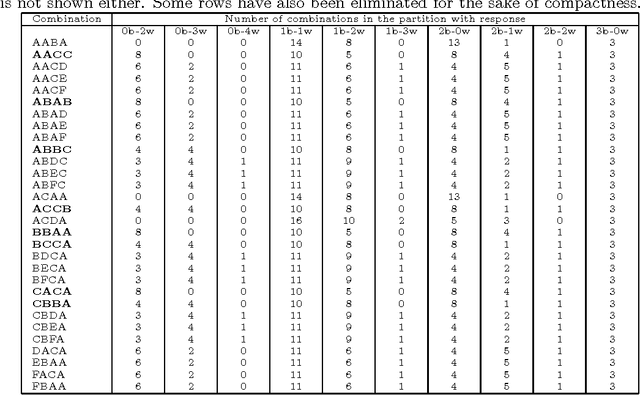
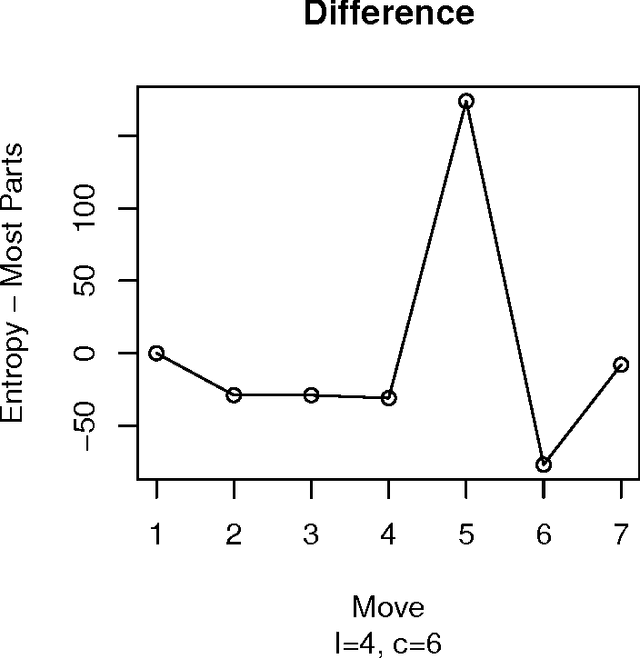
Mastermind is in essence a search problem in which a string of symbols that is kept secret must be found by sequentially playing strings that use the same alphabet, and using the responses that indicate how close are those other strings to the secret one as hints. Although it is commercialized as a game, it is a combinatorial problem of high complexity, with applications on fields that range from computer security to genomics. As such a kind of problem, there are no exact solutions; even exhaustive search methods rely on heuristics to choose, at every step, strings to get the best possible hint. These methods mostly try to play the move that offers the best reduction in search space size in the next step; this move is chosen according to an empirical score. However, in this paper we will examine several state of the art exhaustive search methods and show that another factor, the presence of the actual solution among the candidate moves, or, in other words, the fact that the actual solution has the highest score, plays also a very important role. Using that, we will propose new exhaustive search approaches that obtain results which are comparable to the classic ones, and besides, are better suited as a basis for non-exhaustive search strategies such as evolutionary algorithms, since their behavior in a series of key indicators is better than the classical algorithms.
SOAP vs REST: Comparing a master-slave GA implementation
May 25, 2011

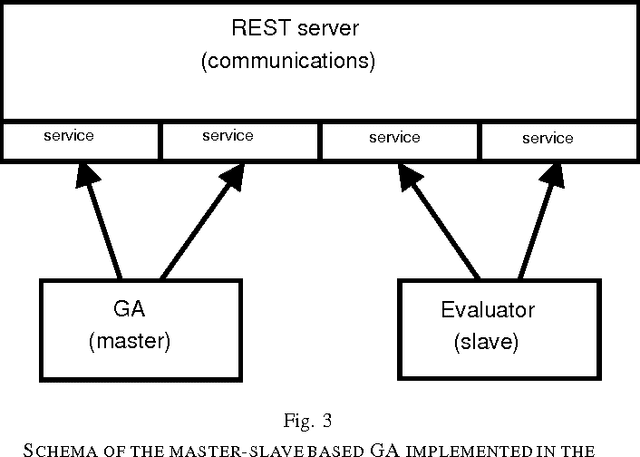
In this paper, a high-level comparison of both SOAP (Simple Object Access Protocol) and REST (Representational State Transfer) is made. These are the two main approaches for interfacing to the web with web services. Both approaches are different and present some advantages and disadvantages for interfacing to web services: SOAP is conceptually more difficult (has a steeper learning curve) and more "heavy-weight" than REST, although it lacks of standards support for security. In order to test their eficiency (in time), two experiments have been performed using both technologies: a client-server model implementation and a master-slave based genetic algorithm (GA). The results obtained show clear differences in time between SOAP and REST implementations. Although both techniques are suitable for developing parallel systems, SOAP is heavier than REST, mainly due to the verbosity of SOAP communications (XML increases the time taken to parse the messages).
Distributed Evolutionary Computation using REST
May 25, 2011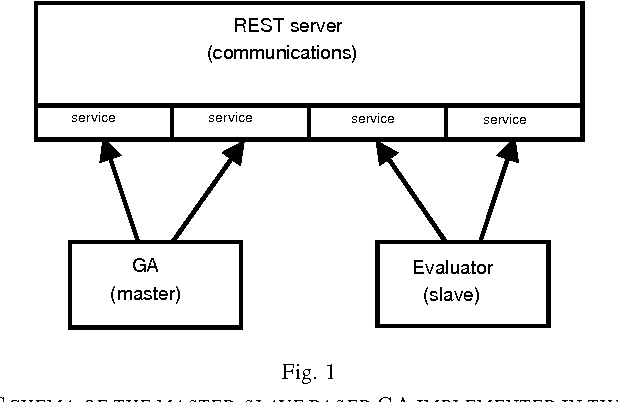

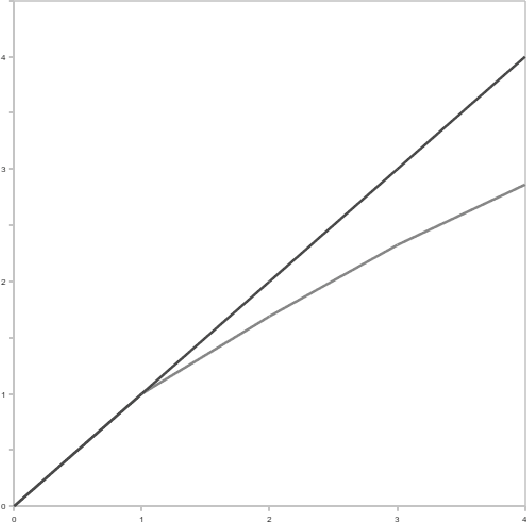
This paper analises distributed evolutionary computation based on the Representational State Transfer (REST) protocol, which overlays a farming model on evolutionary computation. An approach to evolutionary distributed optimisation of multilayer perceptrons (MLP) using REST and language Perl has been done. In these experiments, a master-slave based evolutionary algorithm (EA) has been implemented, where slave processes evaluate the costly fitness function (training a MLP to solve a classification problem). Obtained results show that the parallel version of the developed programs obtains similar or better results using much less time than the sequential version, obtaining a good speedup.
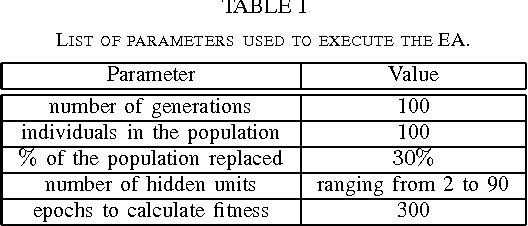
Comparing Single and Multiobjective Evolutionary Approaches to the Inventory and Transportation Problem
Sep 18, 2009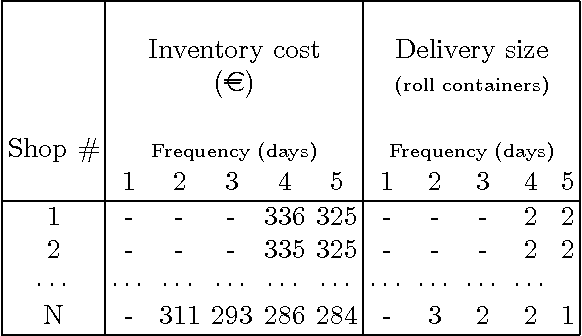
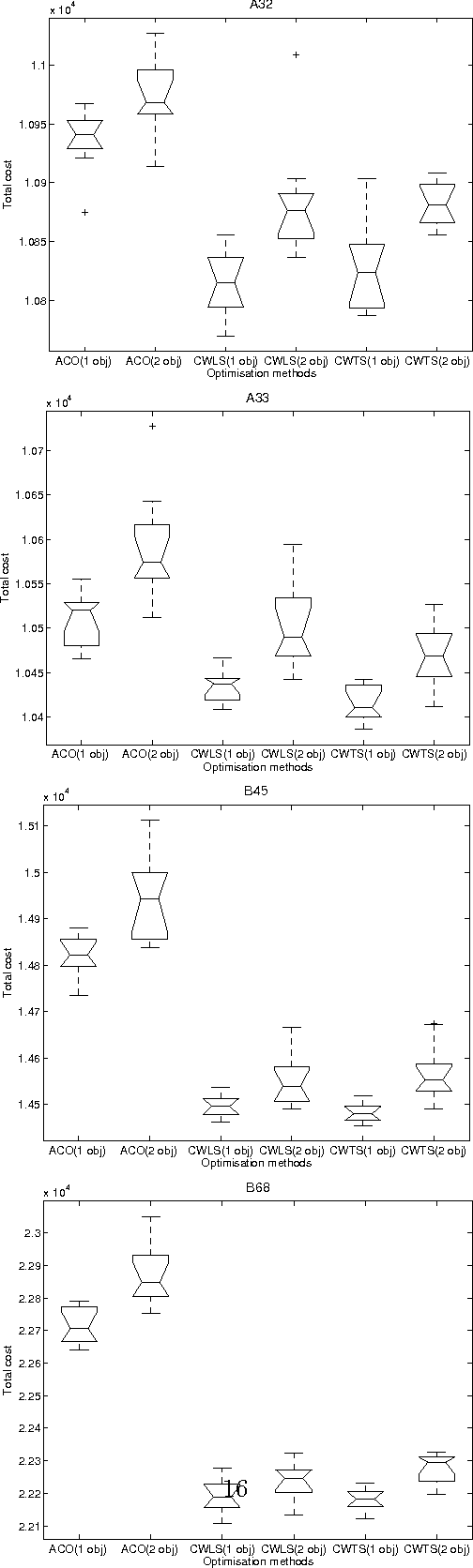
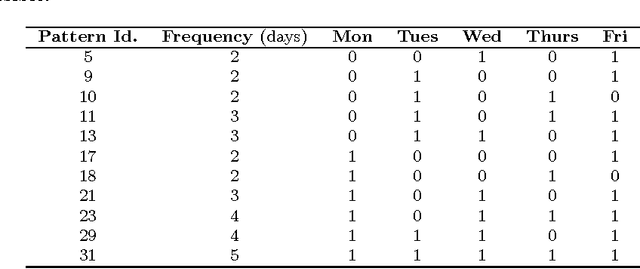
EVITA, standing for Evolutionary Inventory and Transportation Algorithm, is a two-level methodology designed to address the Inventory and Transportation Problem (ITP) in retail chains. The top level uses an evolutionary algorithm to obtain delivery patterns for each shop on a weekly basis so as to minimise the inventory costs, while the bottom level solves the Vehicle Routing Problem (VRP) for every day in order to obtain the minimum transport costs associated to a particular set of patterns. The aim of this paper is to investigate whether a multiobjective approach to this problem can yield any advantage over the previously used single objective approach. The analysis performed allows us to conclude that this is not the case and that the single objective approach is in gene- ral preferable for the ITP in the case studied. A further conclusion is that it is useful to employ a classical algorithm such as Clarke & Wright's as the seed for other metaheuristics like local search or tabu search in order to provide good results for the Vehicle Routing Problem.
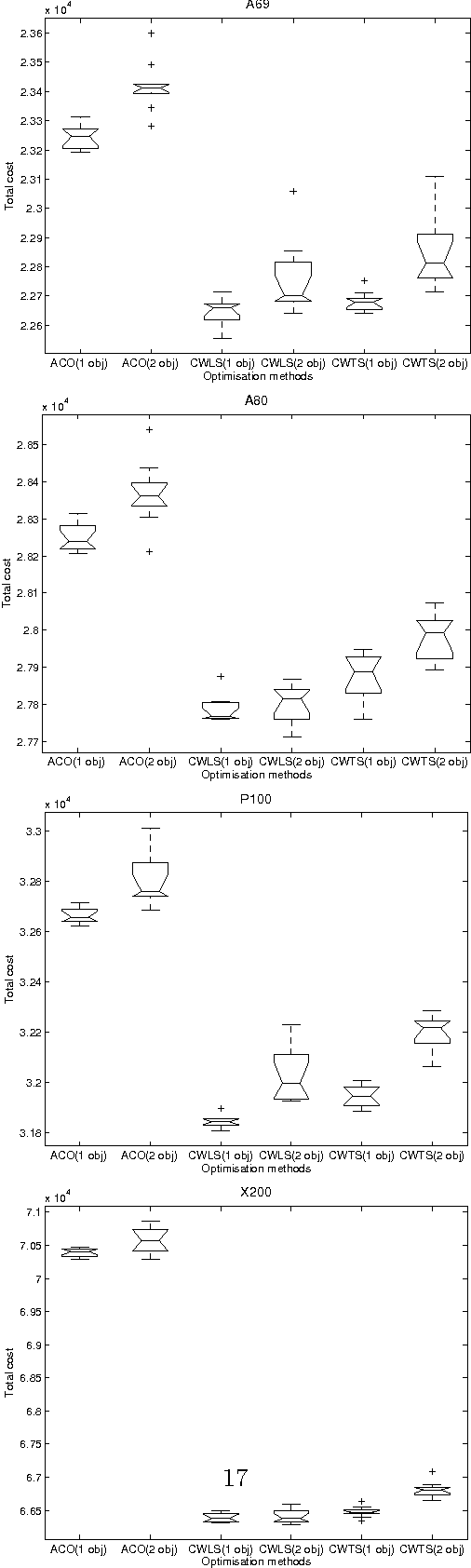
Using Dissortative Mating Genetic Algorithms to Track the Extrema of Dynamic Deceptive Functions
Apr 20, 2009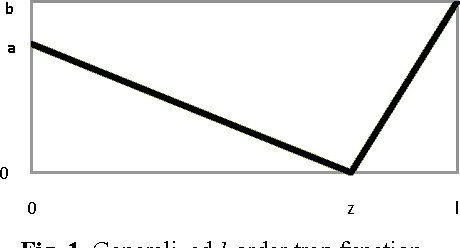


Traditional Genetic Algorithms (GAs) mating schemes select individuals for crossover independently of their genotypic or phenotypic similarities. In Nature, this behaviour is known as random mating. However, non-random schemes - in which individuals mate according to their kinship or likeness - are more common in natural systems. Previous studies indicate that, when applied to GAs, negative assortative mating (a specific type of non-random mating, also known as dissortative mating) may improve their performance (on both speed and reliability) in a wide range of problems. Dissortative mating maintains the genetic diversity at a higher level during the run, and that fact is frequently observed as an explanation for dissortative GAs ability to escape local optima traps. Dynamic problems, due to their specificities, demand special care when tuning a GA, because diversity plays an even more crucial role than it does when tackling static ones. This paper investigates the behaviour of dissortative mating GAs, namely the recently proposed Adaptive Dissortative Mating GA (ADMGA), on dynamic trap functions. ADMGA selects parents according to their Hamming distance, via a self-adjustable threshold value. The method, by keeping population diversity during the run, provides an effective means to deal with dynamic problems. Tests conducted with deceptive and nearly deceptive trap functions indicate that ADMGA is able to outperform other GAs, some specifically designed for tracking moving extrema, on a wide range of tests, being particularly effective when speed of change is not very fast. When comparing the algorithm to a previously proposed dissortative GA, results show that performance is equivalent on the majority of the experiments, but ADMGA performs better when solving the hardest instances of the test set.
KohonAnts: A Self-Organizing Ant Algorithm for Clustering and Pattern Classification
Mar 18, 2008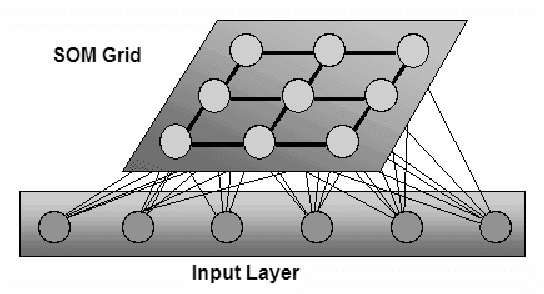
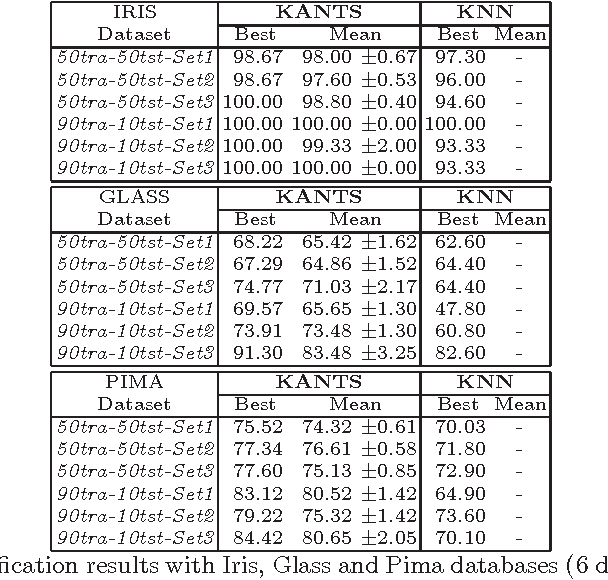
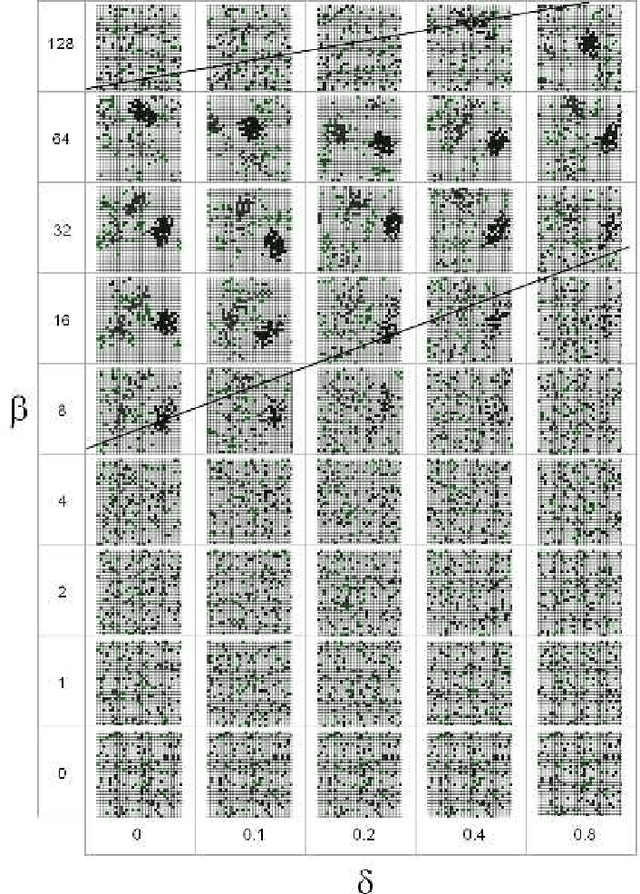
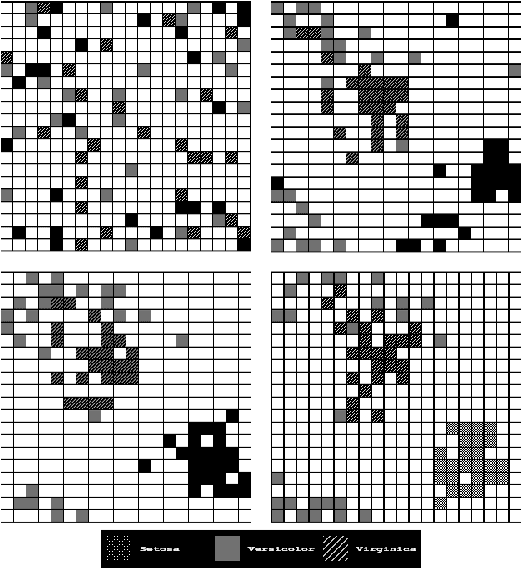
In this paper we introduce a new ant-based method that takes advantage of the cooperative self-organization of Ant Colony Systems to create a naturally inspired clustering and pattern recognition method. The approach considers each data item as an ant, which moves inside a grid changing the cells it goes through, in a fashion similar to Kohonen's Self-Organizing Maps. The resulting algorithm is conceptually more simple, takes less free parameters than other ant-based clustering algorithms, and, after some parameter tuning, yields very good results on some benchmark problems.
Improved evolutionary generation of XSLT stylesheets
Mar 13, 2008

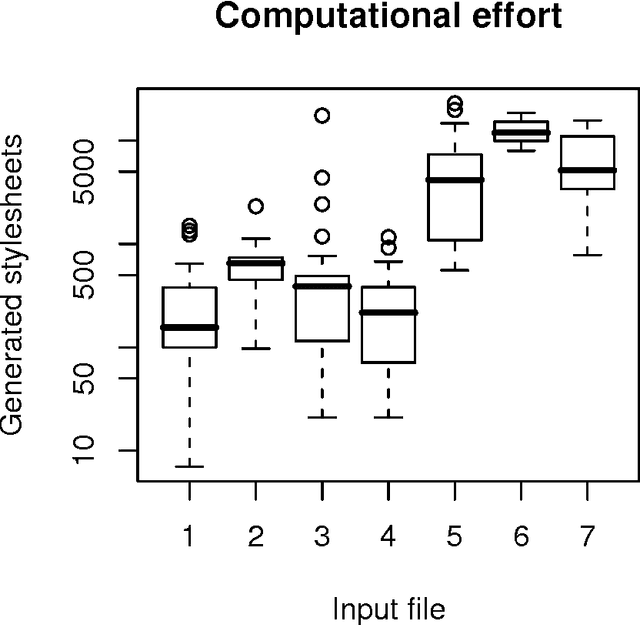
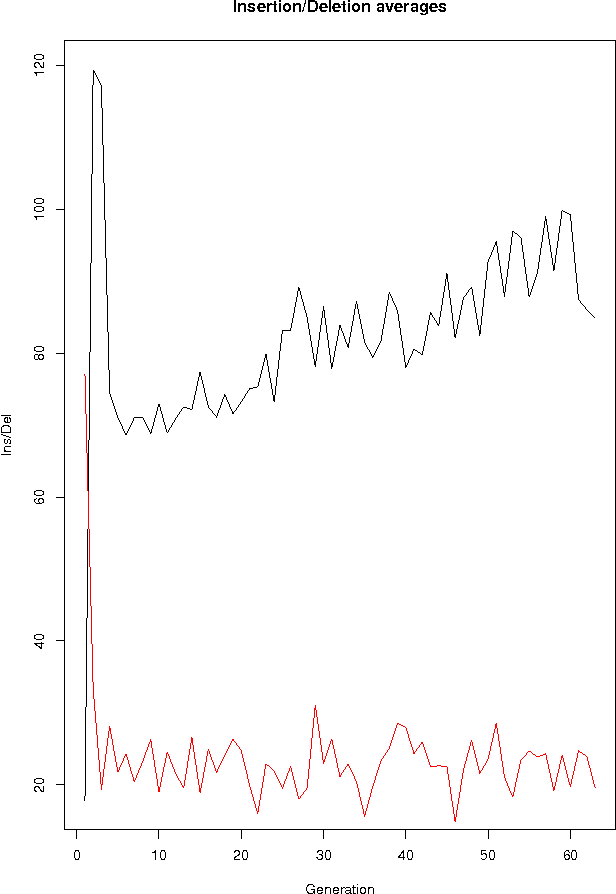
This paper introduces a procedure based on genetic programming to evolve XSLT programs (usually called stylesheets or logicsheets). XSLT is a general purpose, document-oriented functional language, generally used to transform XML documents (or, in general, solve any problem that can be coded as an XML document). The proposed solution uses a tree representation for the stylesheets as well as diverse specific operators in order to obtain, in the studied cases and a reasonable time, a XSLT stylesheet that performs the transformation. Several types of representation have been compared, resulting in different performance and degree of success.