 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAsynchronous Distributed Genetic Algorithms with Javascript and JSON
Jan 30, 2024



In a connected world, spare CPU cycles are up for grabs, if you only make its obtention easy enough. In this paper we present a distributed evolutionary computation system that uses the computational capabilities of the ubiquituous web browser. Using Asynchronous Javascript and JSON (Javascript Object Notation, a serialization protocol) allows anybody with a web browser (that is, mostly everybody connected to the Internet) to participate in a genetic algorithm experiment with little effort, or none at all. Since, in this case, computing becomes a social activity and is inherently impredictable, in this paper we will explore the performance of this kind of virtual computer by solving simple problems such as the Royal Road function and analyzing how many machines and evaluations it yields. We will also examine possible performance bottlenecks and how to solve them, and, finally, issue some advice on how to set up this kind of experiments to maximize turnout and, thus, performance.
Evolvable Agents, a Fine Grained Approach for Distributed Evolutionary Computing: Walking towards the Peer-to-Peer Computing Frontiers
Jan 30, 2024In this work we propose a fine grained approach with self-adaptive migration rate for distributed evolutionary computation. Our target is to gain some insights on the effects caused by communication when the algorithm scales. To this end, we consider a set of basic topologies in order to avoid the overlapping of algorithmic effects between communication and topological structures. We analyse the approach viability by comparing how solution quality and algorithm speed change when the number of processors increases and compare it with an Island model based implementation. A finer-grained approach implies a better chance of achieving a larger scalable system; such a feature is crucial concerning large-scale parallel architectures such as Peer-to-Peer systems. In order to check scalability, we perform a threefold experimental evaluation of this model: First, we concentrate on the algorithmic results when the problem scales up to eight nodes in comparison with how it does following the Island model. Second, we analyse the computing time speedup of the approach while scaling. Finally, we analyse the network performance with the proposed self-adaptive migration rate policy that depends on the link latency and bandwidth. With this experimental setup, our approach shows better scalability than the Island model and a equivalent robustness on the average of the three test functions under study.
An experimental study of exhaustive solutions for the Mastermind puzzle
Jul 05, 2012
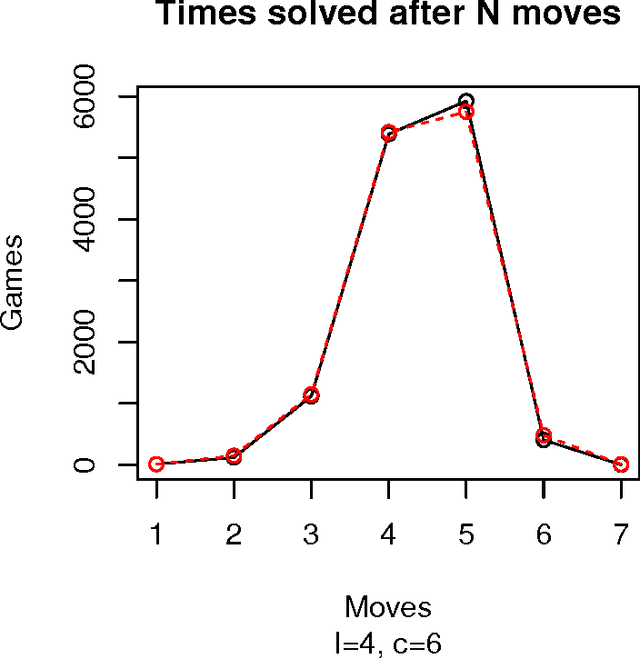
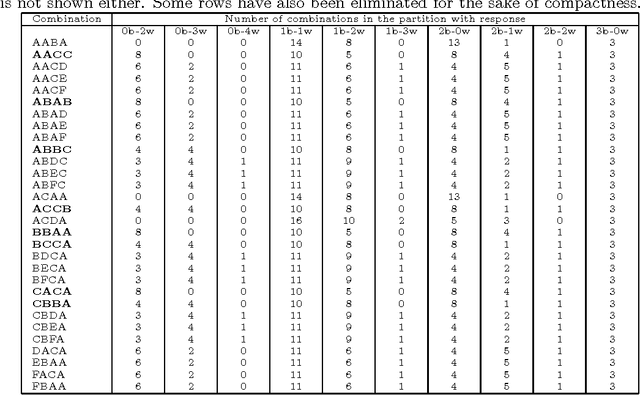
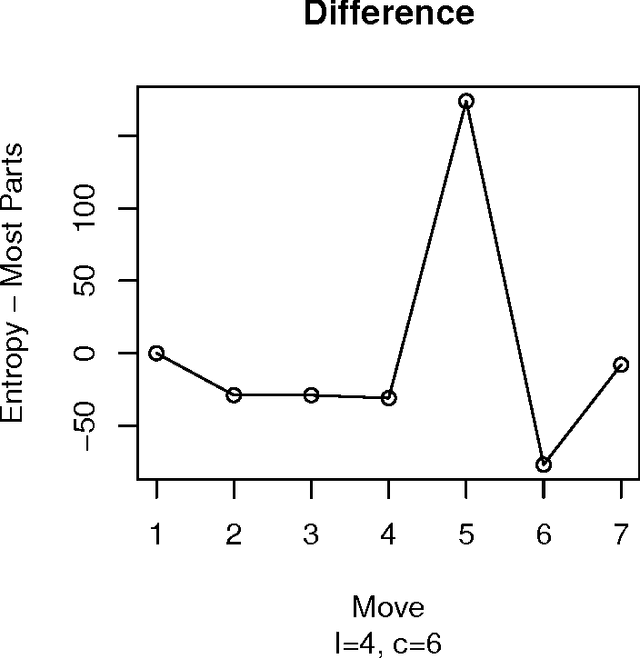
Mastermind is in essence a search problem in which a string of symbols that is kept secret must be found by sequentially playing strings that use the same alphabet, and using the responses that indicate how close are those other strings to the secret one as hints. Although it is commercialized as a game, it is a combinatorial problem of high complexity, with applications on fields that range from computer security to genomics. As such a kind of problem, there are no exact solutions; even exhaustive search methods rely on heuristics to choose, at every step, strings to get the best possible hint. These methods mostly try to play the move that offers the best reduction in search space size in the next step; this move is chosen according to an empirical score. However, in this paper we will examine several state of the art exhaustive search methods and show that another factor, the presence of the actual solution among the candidate moves, or, in other words, the fact that the actual solution has the highest score, plays also a very important role. Using that, we will propose new exhaustive search approaches that obtain results which are comparable to the classic ones, and besides, are better suited as a basis for non-exhaustive search strategies such as evolutionary algorithms, since their behavior in a series of key indicators is better than the classical algorithms.
Cloud-based Evolutionary Algorithms: An algorithmic study
May 31, 2011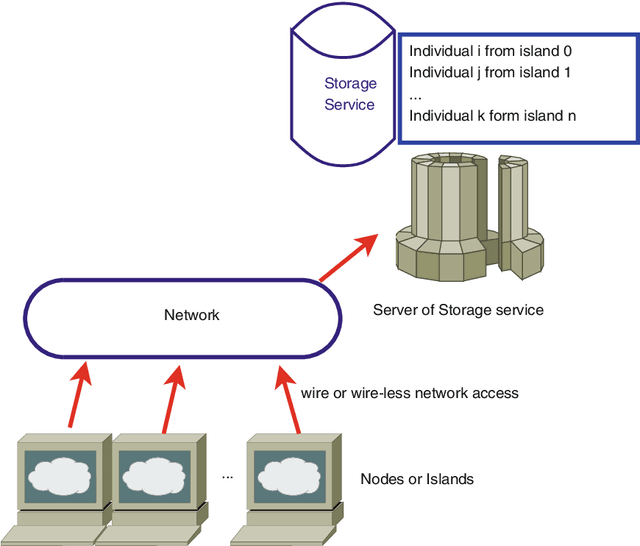

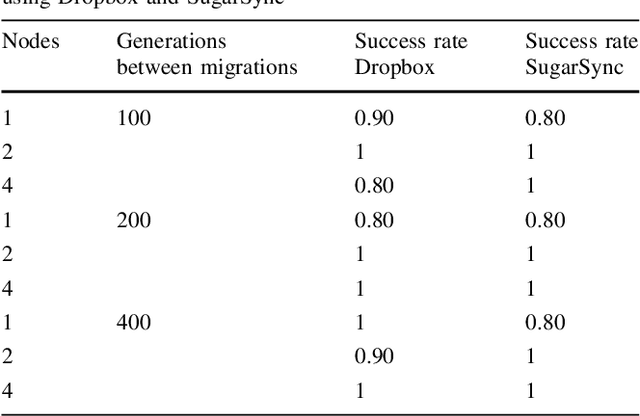
After a proof of concept using Dropbox(tm), a free storage and synchronization service, showed that an evolutionary algorithm using several dissimilar computers connected via WiFi or Ethernet had a good scaling behavior in terms of evaluations per second, it remains to be proved whether that effect also translates to the algorithmic performance of the algorithm. In this paper we will check several different, and difficult, problems, and see what effects the automatic load-balancing and asynchrony have on the speed of resolution of problems.