 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnsemble learning using individual neonatal data for seizure detection
Apr 11, 2022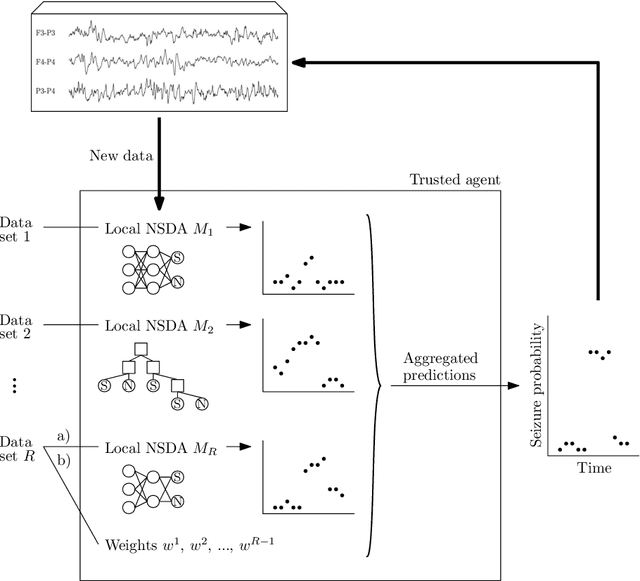
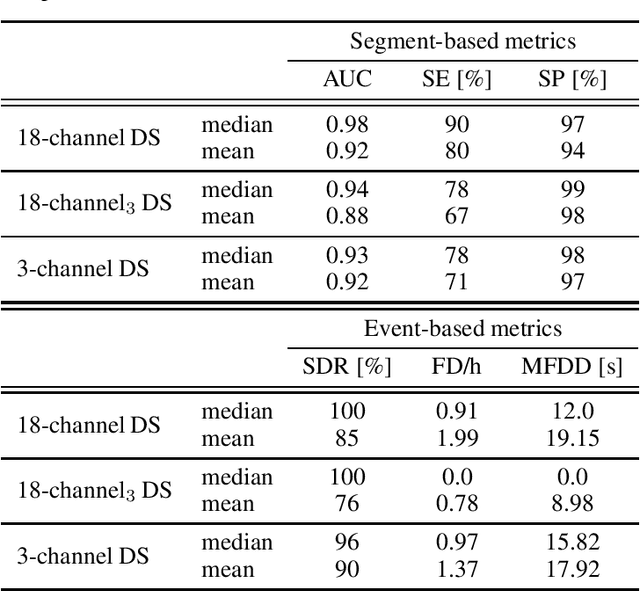
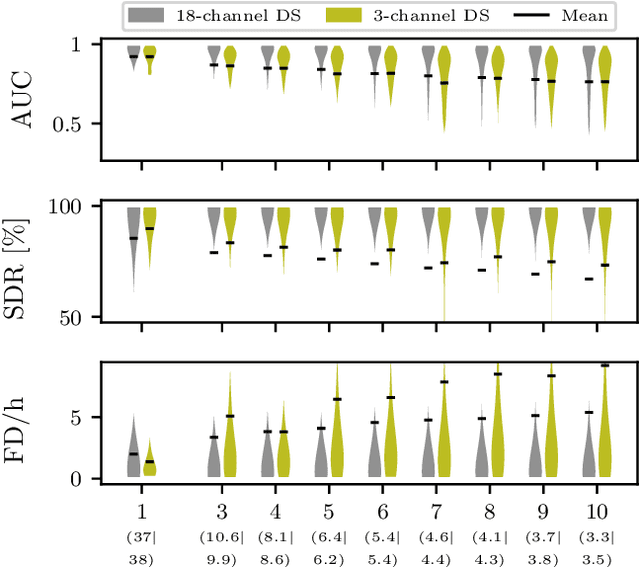
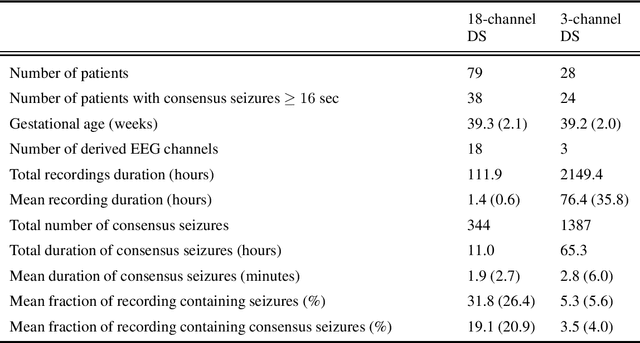
Sharing medical data between institutions is difficult in practice due to data protection laws and official procedures within institutions. Therefore, most existing algorithms are trained on relatively small electroencephalogram (EEG) data sets which is likely to be detrimental to prediction accuracy. In this work, we simulate a case when the data can not be shared by splitting the publicly available data set into disjoint sets representing data in individual institutions. We propose to train a (local) detector in each institution and aggregate their individual predictions into one final prediction. Four aggregation schemes are compared, namely, the majority vote, the mean, the weighted mean and the Dawid-Skene method. The approach allows different detector architectures amongst the institutions. The method was validated on an independent data set using only a subset of EEG channels. The ensemble reaches accuracy comparable to a single detector trained on all the data when sufficient amount of data is available in each institution. The weighted mean aggregation scheme showed best overall performance, it was only marginally outperformed by the Dawid-Skene method when local detectors approach performance of a single detector trained on all available data.
An experimental study of exhaustive solutions for the Mastermind puzzle
Jul 05, 2012
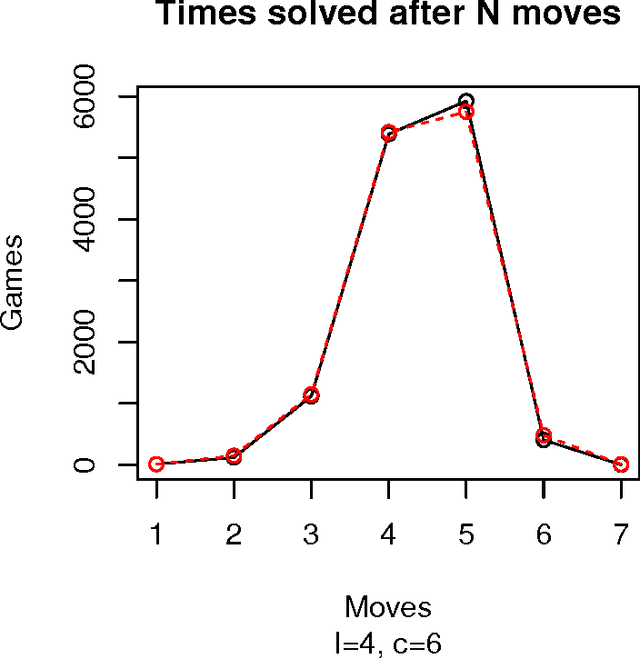
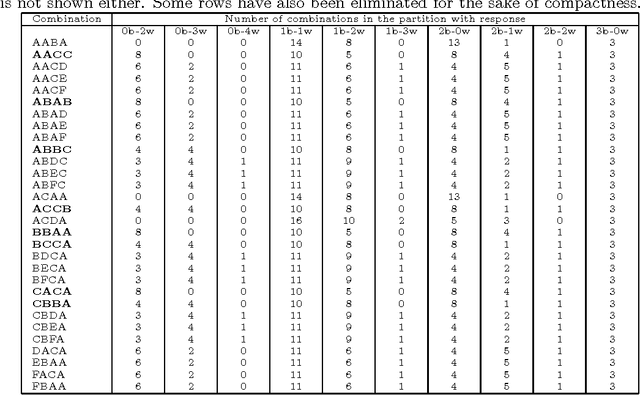
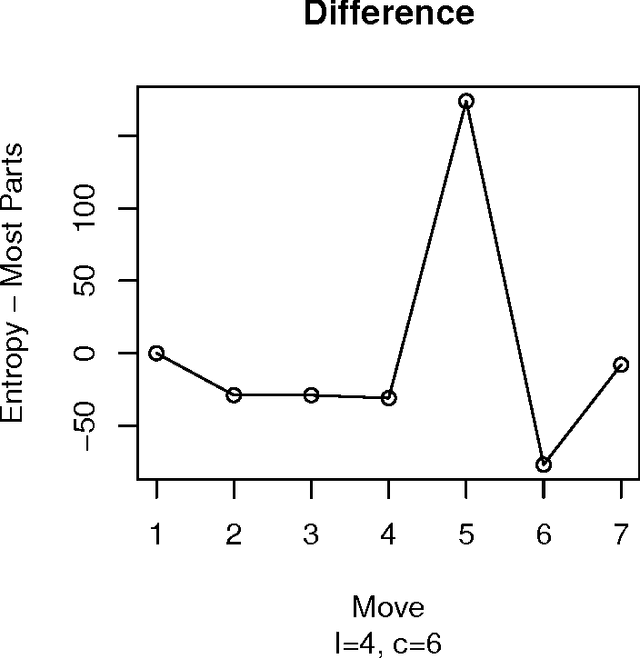
Mastermind is in essence a search problem in which a string of symbols that is kept secret must be found by sequentially playing strings that use the same alphabet, and using the responses that indicate how close are those other strings to the secret one as hints. Although it is commercialized as a game, it is a combinatorial problem of high complexity, with applications on fields that range from computer security to genomics. As such a kind of problem, there are no exact solutions; even exhaustive search methods rely on heuristics to choose, at every step, strings to get the best possible hint. These methods mostly try to play the move that offers the best reduction in search space size in the next step; this move is chosen according to an empirical score. However, in this paper we will examine several state of the art exhaustive search methods and show that another factor, the presence of the actual solution among the candidate moves, or, in other words, the fact that the actual solution has the highest score, plays also a very important role. Using that, we will propose new exhaustive search approaches that obtain results which are comparable to the classic ones, and besides, are better suited as a basis for non-exhaustive search strategies such as evolutionary algorithms, since their behavior in a series of key indicators is better than the classical algorithms.