 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpecialty detection in the context of telemedicine in a highly imbalanced multi-class distribution
Feb 21, 2024The Covid-19 pandemic has led to an increase in the awareness of and demand for telemedicine services, resulting in a need for automating the process and relying on machine learning (ML) to reduce the operational load. This research proposes a specialty detection classifier based on a machine learning model to automate the process of detecting the correct specialty for each question and routing it to the correct doctor. The study focuses on handling multiclass and highly imbalanced datasets for Arabic medical questions, comparing some oversampling techniques, developing a Deep Neural Network (DNN) model for specialty detection, and exploring the hidden business areas that rely on specialty detection such as customizing and personalizing the consultation flow for different specialties. The proposed module is deployed in both synchronous and asynchronous medical consultations to provide more real-time classification, minimize the doctor effort in addressing the correct specialty, and give the system more flexibility in customizing the medical consultation flow. The evaluation and assessment are based on accuracy, precision, recall, and F1-score. The experimental results suggest that combining multiple techniques, such as SMOTE and reweighing with keyword identification, is necessary to achieve improved performance in detecting rare classes in imbalanced multiclass datasets. By using these techniques, specialty detection models can more accurately detect rare classes in real-world scenarios where imbalanced data is common.
Effects of term weighting approach with and without stop words removing on Arabic text classification
Feb 21, 2024Classifying text is a method for categorizing documents into pre-established groups. Text documents must be prepared and represented in a way that is appropriate for the algorithms used for data mining prior to classification. As a result, a number of term weighting strategies have been created in the literature to enhance text categorization algorithms' functionality. This study compares the effects of Binary and Term frequency weighting feature methodologies on the text's classification method when stop words are eliminated once and when they are not. In recognition of assessing the effects of prior weighting of features approaches on classification results in terms of accuracy, recall, precision, and F-measure values, we used an Arabic data set made up of 322 documents divided into six main topics (agriculture, economy, health, politics, science, and sport), each of which contains 50 documents, with the exception of the health category, which contains 61 documents. The results demonstrate that for all metrics, the term frequency feature weighting approach with stop word removal outperforms the binary approach, while for accuracy, recall, and F-Measure, the binary approach outperforms the TF approach without stop word removal. However, for precision, the two approaches produce results that are very similar. Additionally, it is clear from the data that, using the same phrase weighting approach, stop word removing increases classification accuracy.
An Effective Networks Intrusion Detection Approach Based on Hybrid Harris Hawks and Multi-Layer Perceptron
Feb 21, 2024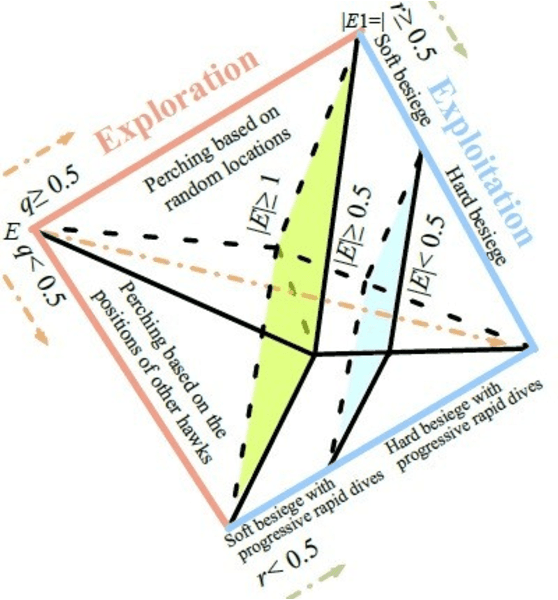
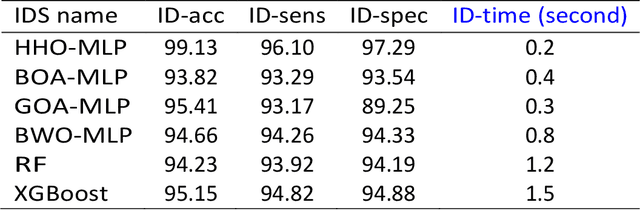
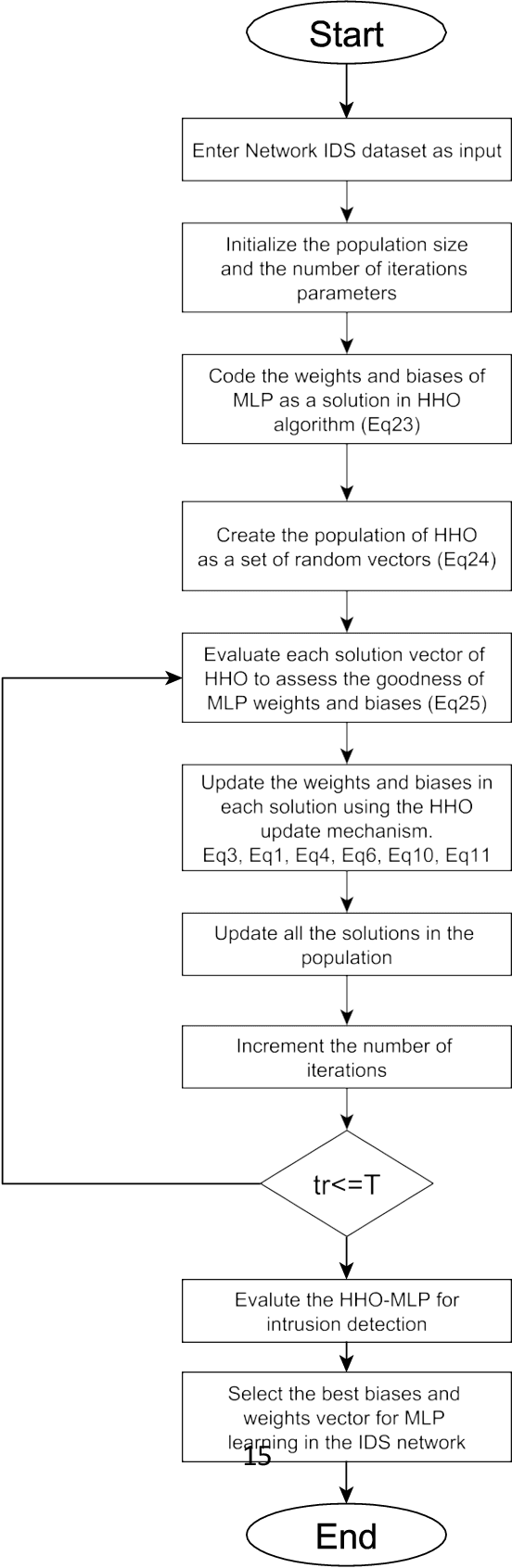
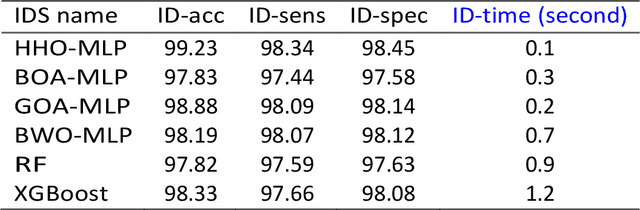
This paper proposes an Intrusion Detection System (IDS) employing the Harris Hawks Optimization algorithm (HHO) to optimize Multilayer Perceptron learning by optimizing bias and weight parameters. HHO-MLP aims to select optimal parameters in its learning process to minimize intrusion detection errors in networks. HHO-MLP has been implemented using EvoloPy NN framework, an open-source Python tool specialized for training MLPs using evolutionary algorithms. For purposes of comparing the HHO model against other evolutionary methodologies currently available, specificity and sensitivity measures, accuracy measures, and mse and rmse measures have been calculated using KDD datasets. Experiments have demonstrated the HHO MLP method is effective at identifying malicious patterns. HHO-MLP has been tested against evolutionary algorithms like Butterfly Optimization Algorithm (BOA), Grasshopper Optimization Algorithms (GOA), and Black Widow Optimizations (BOW), with validation by Random Forest (RF), XG-Boost. HHO-MLP showed superior performance by attaining top scores with accuracy rate of 93.17%, sensitivity level of 89.25%, and specificity percentage of 95.41%.
Determining the significance and relative importance of parameters of a simulated quenching algorithm using statistical tools
Feb 08, 2024When search methods are being designed it is very important to know which parameters have the greatest influence on the behaviour and performance of the algorithm. To this end, algorithm parameters are commonly calibrated by means of either theoretic analysis or intensive experimentation. When undertaking a detailed statistical analysis of the influence of each parameter, the designer should pay attention mostly to the parameters that are statistically significant. In this paper the ANOVA (ANalysis Of the VAriance) method is used to carry out an exhaustive analysis of a simulated annealing based method and the different parameters it requires. Following this idea, the significance and relative importance of the parameters regarding the obtained results, as well as suitable values for each of these, were obtained using ANOVA and post-hoc Tukey HSD test, on four well known function optimization problems and the likelihood function that is used to estimate the parameters involved in the lognormal diffusion process. Through this statistical study we have verified the adequacy of parameter values available in the bibliography using parametric hypothesis tests.
Evolvable Agents, a Fine Grained Approach for Distributed Evolutionary Computing: Walking towards the Peer-to-Peer Computing Frontiers
Jan 30, 2024In this work we propose a fine grained approach with self-adaptive migration rate for distributed evolutionary computation. Our target is to gain some insights on the effects caused by communication when the algorithm scales. To this end, we consider a set of basic topologies in order to avoid the overlapping of algorithmic effects between communication and topological structures. We analyse the approach viability by comparing how solution quality and algorithm speed change when the number of processors increases and compare it with an Island model based implementation. A finer-grained approach implies a better chance of achieving a larger scalable system; such a feature is crucial concerning large-scale parallel architectures such as Peer-to-Peer systems. In order to check scalability, we perform a threefold experimental evaluation of this model: First, we concentrate on the algorithmic results when the problem scales up to eight nodes in comparison with how it does following the Island model. Second, we analyse the computing time speedup of the approach while scaling. Finally, we analyse the network performance with the proposed self-adaptive migration rate policy that depends on the link latency and bandwidth. With this experimental setup, our approach shows better scalability than the Island model and a equivalent robustness on the average of the three test functions under study.
Asynchronous Distributed Genetic Algorithms with Javascript and JSON
Jan 30, 2024



In a connected world, spare CPU cycles are up for grabs, if you only make its obtention easy enough. In this paper we present a distributed evolutionary computation system that uses the computational capabilities of the ubiquituous web browser. Using Asynchronous Javascript and JSON (Javascript Object Notation, a serialization protocol) allows anybody with a web browser (that is, mostly everybody connected to the Internet) to participate in a genetic algorithm experiment with little effort, or none at all. Since, in this case, computing becomes a social activity and is inherently impredictable, in this paper we will explore the performance of this kind of virtual computer by solving simple problems such as the Royal Road function and analyzing how many machines and evaluations it yields. We will also examine possible performance bottlenecks and how to solve them, and, finally, issue some advice on how to set up this kind of experiments to maximize turnout and, thus, performance.
NodIO, a JavaScript framework for volunteer-based evolutionary algorithms : first results
Jan 07, 2016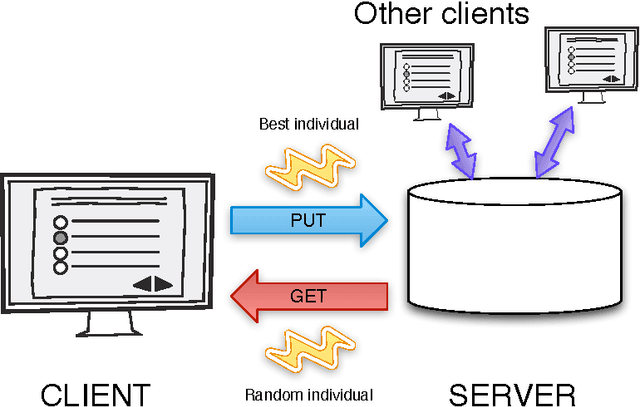
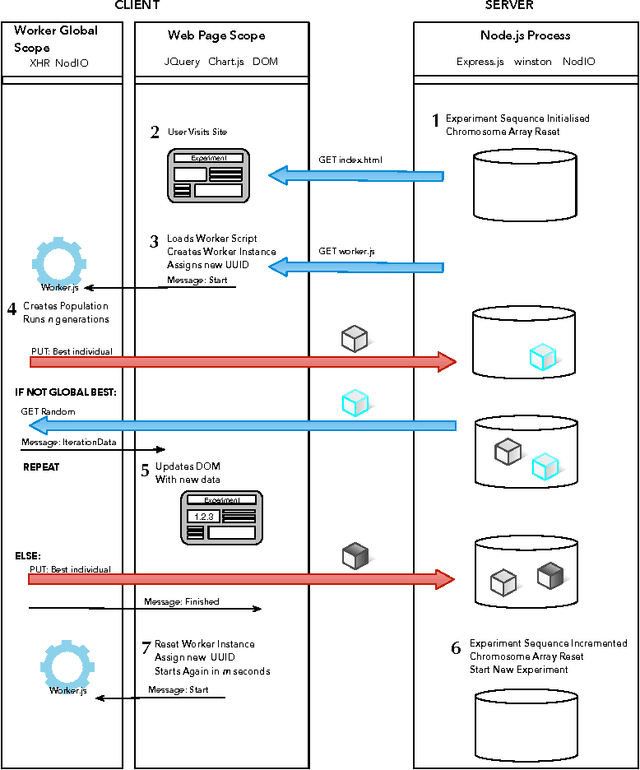
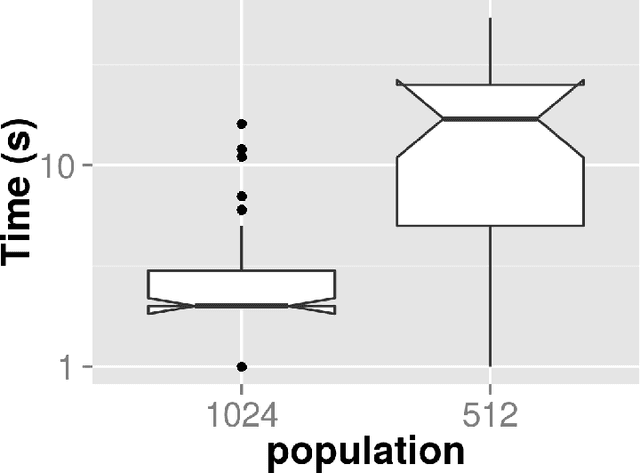
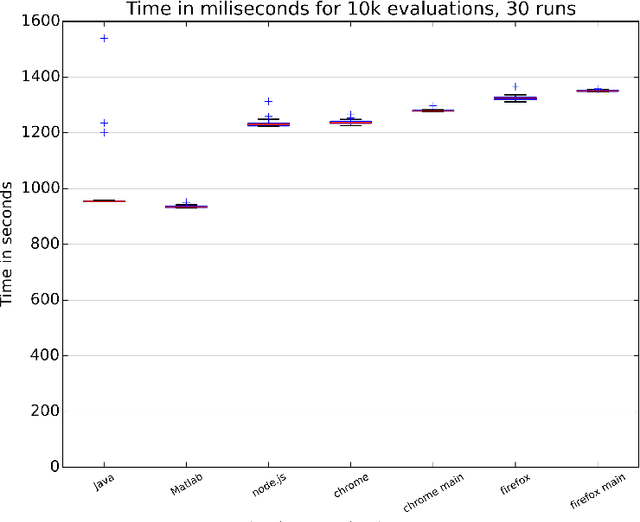
JavaScript is an interpreted language mainly known for its inclusion in web browsers, making them a container for rich Internet based applications. This has inspired its use, for a long time, as a tool for evolutionary algorithms, mainly so in browser-based volunteer computing environments. Several libraries have also been published so far and are in use. However, the last years have seen a resurgence of interest in the language, becoming one of the most popular and thus spawning the improvement of its implementations, which are now the foundation of many new client-server applications. We present such an application for running distributed volunteer-based evolutionary algorithm experiments, and we make a series of measurements to establish the speed of JavaScript in evolutionary algorithms that can serve as a baseline for comparison with other distributed computing experiments. These experiments use different integer and floating point problems, and prove that the speed of JavaScript is actually competitive with other languages commonly used by the evolutionary algorithm practitioner.