 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Effective Networks Intrusion Detection Approach Based on Hybrid Harris Hawks and Multi-Layer Perceptron
Feb 21, 2024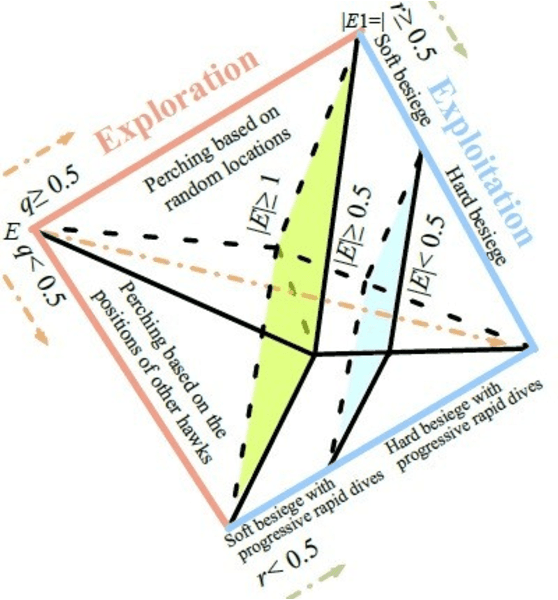
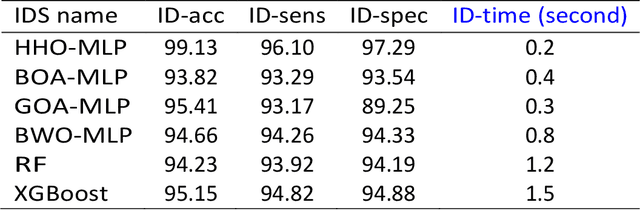
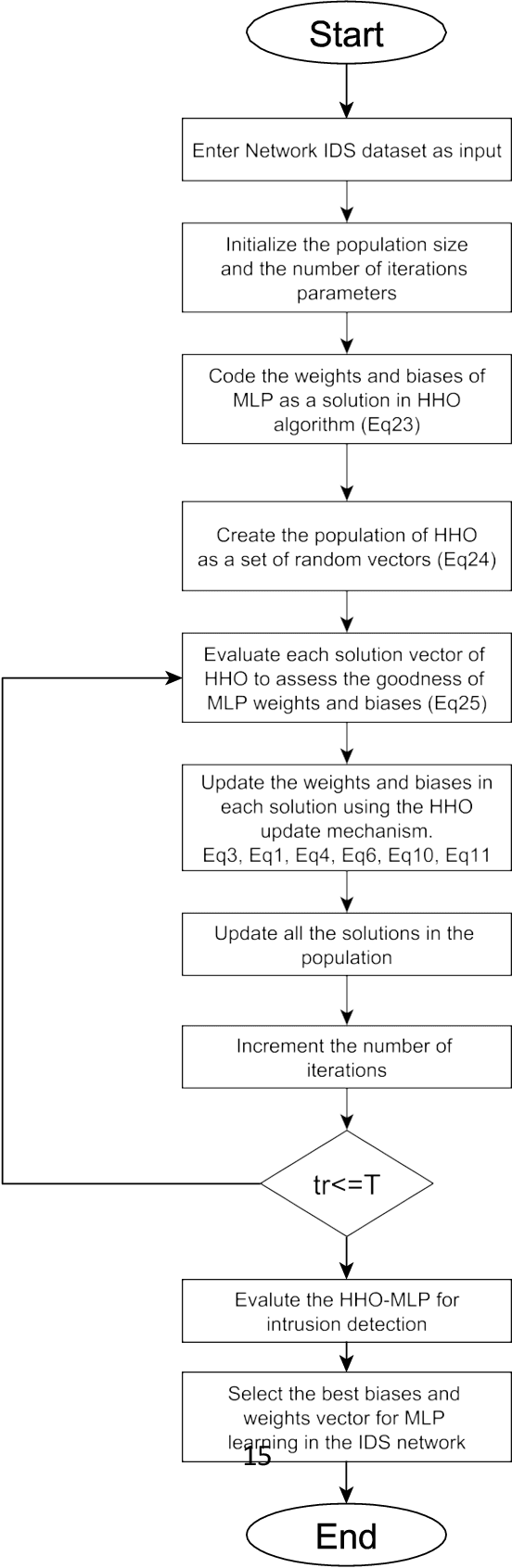
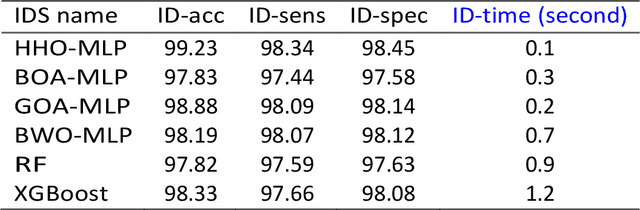
This paper proposes an Intrusion Detection System (IDS) employing the Harris Hawks Optimization algorithm (HHO) to optimize Multilayer Perceptron learning by optimizing bias and weight parameters. HHO-MLP aims to select optimal parameters in its learning process to minimize intrusion detection errors in networks. HHO-MLP has been implemented using EvoloPy NN framework, an open-source Python tool specialized for training MLPs using evolutionary algorithms. For purposes of comparing the HHO model against other evolutionary methodologies currently available, specificity and sensitivity measures, accuracy measures, and mse and rmse measures have been calculated using KDD datasets. Experiments have demonstrated the HHO MLP method is effective at identifying malicious patterns. HHO-MLP has been tested against evolutionary algorithms like Butterfly Optimization Algorithm (BOA), Grasshopper Optimization Algorithms (GOA), and Black Widow Optimizations (BOW), with validation by Random Forest (RF), XG-Boost. HHO-MLP showed superior performance by attaining top scores with accuracy rate of 93.17%, sensitivity level of 89.25%, and specificity percentage of 95.41%.
A new approach for solving global optimization and engineering problems based on modified Sea Horse Optimizer
Feb 21, 2024



Sea Horse Optimizer (SHO) is a noteworthy metaheuristic algorithm that emulates various intelligent behaviors exhibited by sea horses, encompassing feeding patterns, male reproductive strategies, and intricate movement patterns. To mimic the nuanced locomotion of sea horses, SHO integrates the logarithmic helical equation and Levy flight, effectively incorporating both random movements with substantial step sizes and refined local exploitation. Additionally, the utilization of Brownian motion facilitates a more comprehensive exploration of the search space. This study introduces a robust and high-performance variant of the SHO algorithm named mSHO. The enhancement primarily focuses on bolstering SHO's exploitation capabilities by replacing its original method with an innovative local search strategy encompassing three distinct steps: a neighborhood-based local search, a global non-neighbor-based search, and a method involving circumnavigation of the existing search region. These techniques improve mSHO algorithm's search capabilities, allowing it to navigate the search space and converge toward optimal solutions efficiently. The comprehensive results distinctly establish the supremacy and efficiency of the mSHO method as an exemplary tool for tackling an array of optimization quandaries. The results show that the proposed mSHO algorithm has a total rank of 1 for CEC'2020 test functions. In contrast, the mSHO achieved the best value for the engineering problems, recording a value of 0.012665, 2993.634, 0.01266, 1.724967, 263.8915, 0.032255, 58507.14, 1.339956, and 0.23524 for the pressure vessel design, speed reducer design, tension/compression spring, welded beam design, three-bar truss engineering design, industrial refrigeration system, multi-Product batch plant, cantilever beam problem, multiple disc clutch brake problems, respectively.
Effects of term weighting approach with and without stop words removing on Arabic text classification
Feb 21, 2024Classifying text is a method for categorizing documents into pre-established groups. Text documents must be prepared and represented in a way that is appropriate for the algorithms used for data mining prior to classification. As a result, a number of term weighting strategies have been created in the literature to enhance text categorization algorithms' functionality. This study compares the effects of Binary and Term frequency weighting feature methodologies on the text's classification method when stop words are eliminated once and when they are not. In recognition of assessing the effects of prior weighting of features approaches on classification results in terms of accuracy, recall, precision, and F-measure values, we used an Arabic data set made up of 322 documents divided into six main topics (agriculture, economy, health, politics, science, and sport), each of which contains 50 documents, with the exception of the health category, which contains 61 documents. The results demonstrate that for all metrics, the term frequency feature weighting approach with stop word removal outperforms the binary approach, while for accuracy, recall, and F-Measure, the binary approach outperforms the TF approach without stop word removal. However, for precision, the two approaches produce results that are very similar. Additionally, it is clear from the data that, using the same phrase weighting approach, stop word removing increases classification accuracy.