 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep memetic models for combinatorial optimization problems: application to the tool switching problem
Nov 04, 2024Memetic algorithms are techniques that orchestrate the interplay between population-based and trajectory-based algorithmic components. In particular, some memetic models can be regarded under this broad interpretation as a group of autonomous basic optimization algorithms that interact among them in a cooperative way in order to deal with a specific optimization problem, aiming to obtain better results than the algorithms that constitute it separately. Going one step beyond this traditional view of cooperative optimization algorithms, this work tackles deep meta-cooperation, namely the use of cooperative optimization algorithms in which some components can in turn be cooperative methods themselves, thus exhibiting a deep algorithmic architecture. The objective of this paper is to demonstrate that such models can be considered as an efficient alternative to other traditional forms of cooperative algorithms. To validate this claim, different structural parameters, such as the communication topology between the agents, or the parameter that influences the depth of the cooperative effort (the depth of meta-cooperation), have been analyzed. To do this, a comparison with the state-of-the-art cooperative methods to solve a specific combinatorial problem, the Tool Switching Problem, has been performed. Results show that deep models are effective to solve this problem, outperforming metaheuristics proposed in the literature.
* 32 pages, 5 figures
Optimizing Hearthstone Agents using an Evolutionary Algorithm
Oct 25, 2024



Digital collectible card games are not only a growing part of the video game industry, but also an interesting research area for the field of computational intelligence. This game genre allows researchers to deal with hidden information, uncertainty and planning, among other aspects. This paper proposes the use of evolutionary algorithms (EAs) to develop agents who play a card game, Hearthstone, by optimizing a data-driven decision-making mechanism that takes into account all the elements currently in play. Agents feature self-learning by means of a competitive coevolutionary training approach, whereby no external sparring element defined by the user is required for the optimization process. One of the agents developed through the proposed approach was runner-up (best 6%) in an international Hearthstone Artificial Intelligence (AI) competition. Our proposal performed remarkably well, even when it faced state-of-the-art techniques that attempted to take into account future game states, such as Monte-Carlo Tree search. This outcome shows how evolutionary computation could represent a considerable advantage in developing AIs for collectible card games such as Hearthstone.
* 43 pages, 11 figures
Determining the significance and relative importance of parameters of a simulated quenching algorithm using statistical tools
Feb 08, 2024When search methods are being designed it is very important to know which parameters have the greatest influence on the behaviour and performance of the algorithm. To this end, algorithm parameters are commonly calibrated by means of either theoretic analysis or intensive experimentation. When undertaking a detailed statistical analysis of the influence of each parameter, the designer should pay attention mostly to the parameters that are statistically significant. In this paper the ANOVA (ANalysis Of the VAriance) method is used to carry out an exhaustive analysis of a simulated annealing based method and the different parameters it requires. Following this idea, the significance and relative importance of the parameters regarding the obtained results, as well as suitable values for each of these, were obtained using ANOVA and post-hoc Tukey HSD test, on four well known function optimization problems and the likelihood function that is used to estimate the parameters involved in the lognormal diffusion process. Through this statistical study we have verified the adequacy of parameter values available in the bibliography using parametric hypothesis tests.
Metaheuristics "In the Large"
Dec 18, 2020Following decades of sustained improvement, metaheuristics are one of the great success stories of optimization research. However, in order for research in metaheuristics to avoid fragmentation and a lack of reproducibility, there is a pressing need for stronger scientific and computational infrastructure to support the development, analysis and comparison of new approaches. We argue that, via principled choice of infrastructure support, the field can pursue a higher level of scientific enquiry. We describe our vision and report on progress, showing how the adoption of common protocols for all metaheuristics can help liberate the potential of the field, easing the exploration of the design space of metaheuristics.
RedDwarfData: a simplified dataset of StarCraft matches
Dec 29, 2017The game Starcraft is one of the most interesting arenas to test new machine learning and computational intelligence techniques; however, StarCraft matches take a long time and creating a good dataset for training can be hard. Besides, analyzing match logs to extract the main characteristics can also be done in many different ways to the point that extracting and processing data itself can take an inordinate amount of time and of course, depending on what you choose, can bias learning algorithms. In this paper we present a simplified dataset extracted from the set of matches published by Robinson and Watson, which we have called RedDwarfData, containing several thousand matches processed to frames, so that temporal studies can also be undertaken. This dataset is available from GitHub under a free license. An initial analysis and appraisal of these matches is also made.
NodIO, a JavaScript framework for volunteer-based evolutionary algorithms : first results
Jan 07, 2016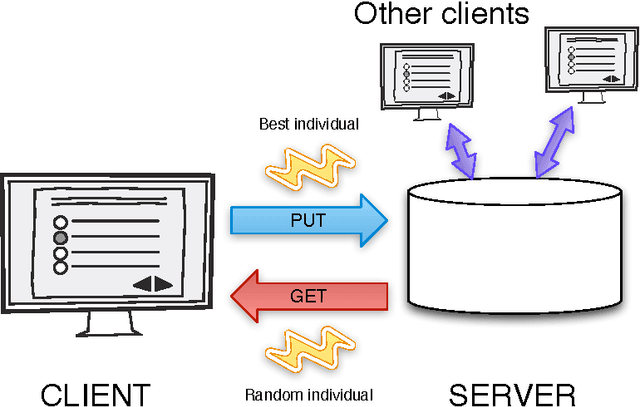
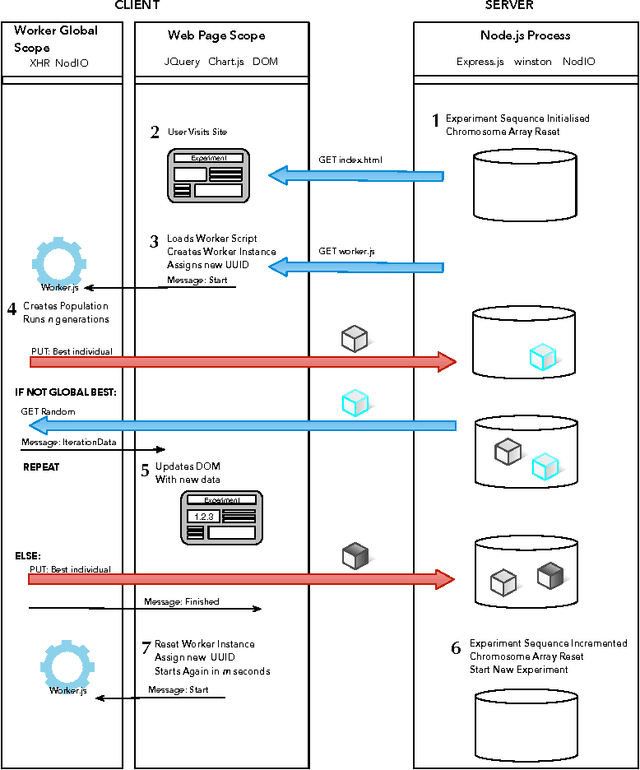
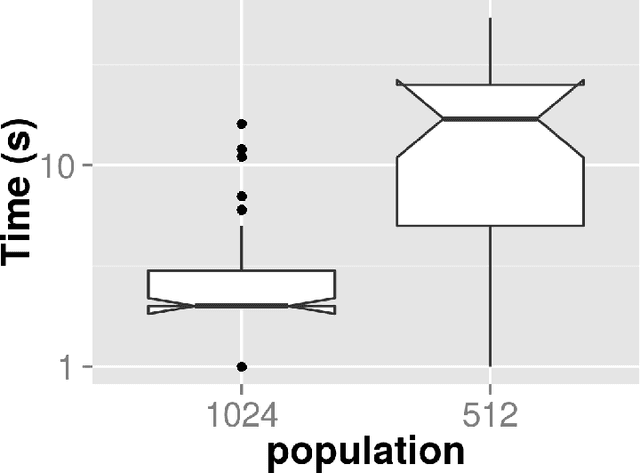
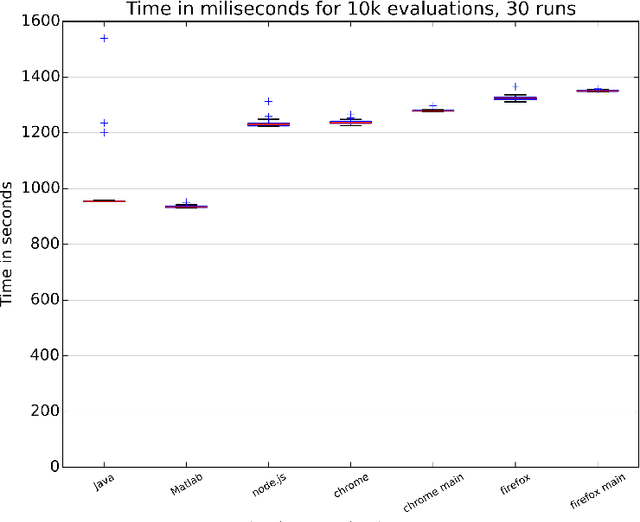
JavaScript is an interpreted language mainly known for its inclusion in web browsers, making them a container for rich Internet based applications. This has inspired its use, for a long time, as a tool for evolutionary algorithms, mainly so in browser-based volunteer computing environments. Several libraries have also been published so far and are in use. However, the last years have seen a resurgence of interest in the language, becoming one of the most popular and thus spawning the improvement of its implementations, which are now the foundation of many new client-server applications. We present such an application for running distributed volunteer-based evolutionary algorithm experiments, and we make a series of measurements to establish the speed of JavaScript in evolutionary algorithms that can serve as a baseline for comparison with other distributed computing experiments. These experiments use different integer and floating point problems, and prove that the speed of JavaScript is actually competitive with other languages commonly used by the evolutionary algorithm practitioner.
There is no fast lunch: an examination of the running speed of evolutionary algorithms in several languages
Nov 03, 2015
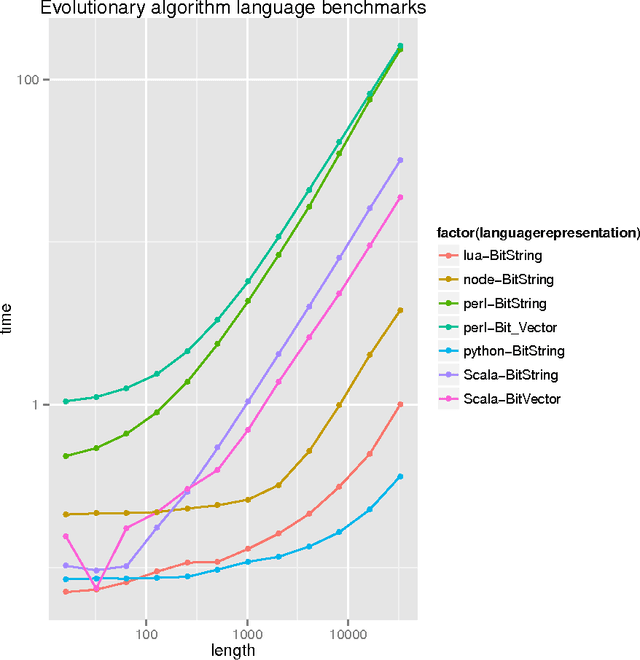
It is quite usual when an evolutionary algorithm tool or library uses a language other than C, C++, Java or Matlab that a reviewer or the audience questions its usefulness based on the speed of those other languages, purportedly slower than the aforementioned ones. Despite speed being not everything needed to design a useful evolutionary algorithm application, in this paper we will measure the speed for several very basic evolutionary algorithm operations in several languages which use different virtual machines and approaches, and prove that, in fact, there is no big difference in speed between interpreted and compiled languages, and that in some cases, interpreted languages such as JavaScript or Python can be faster than compiled languages such as Scala, making them worthy of use for evolutionary algorithm experimentation.
Modeling browser-based distributed evolutionary computation systems
Mar 22, 2015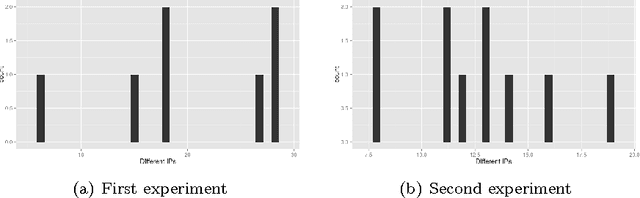
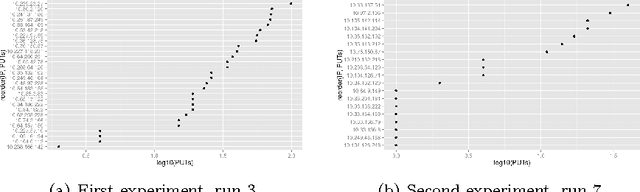
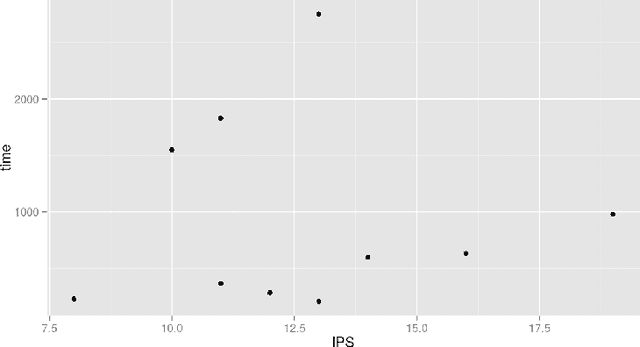
From the era of big science we are back to the "do it yourself", where you do not have any money to buy clusters or subscribe to grids but still have algorithms that crave many computing nodes and need them to measure scalability. Fortunately, this coincides with the era of big data, cloud computing, and browsers that include JavaScript virtual machines. Those are the reasons why this paper will focus on two different aspects of volunteer or freeriding computing: first, the pragmatic: where to find those resources, which ones can be used, what kind of support you have to give them; and then, the theoretical: how evolutionary algorithms can be adapted to an environment in which nodes come and go, have different computing capabilities and operate in complete asynchrony of each other. We will examine the setup needed to create a very simple distributed evolutionary algorithm using JavaScript and then find a model of how users react to it by collecting data from several experiments featuring different classical benchmark functions.
Comparing Single and Multiobjective Evolutionary Approaches to the Inventory and Transportation Problem
Sep 18, 2009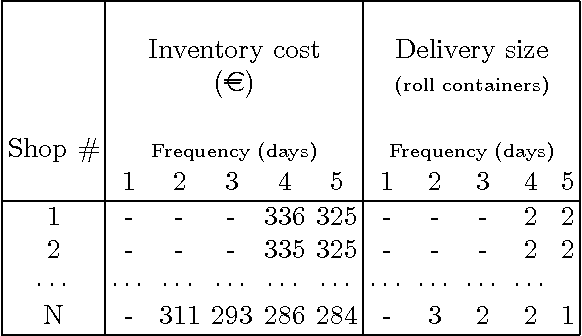
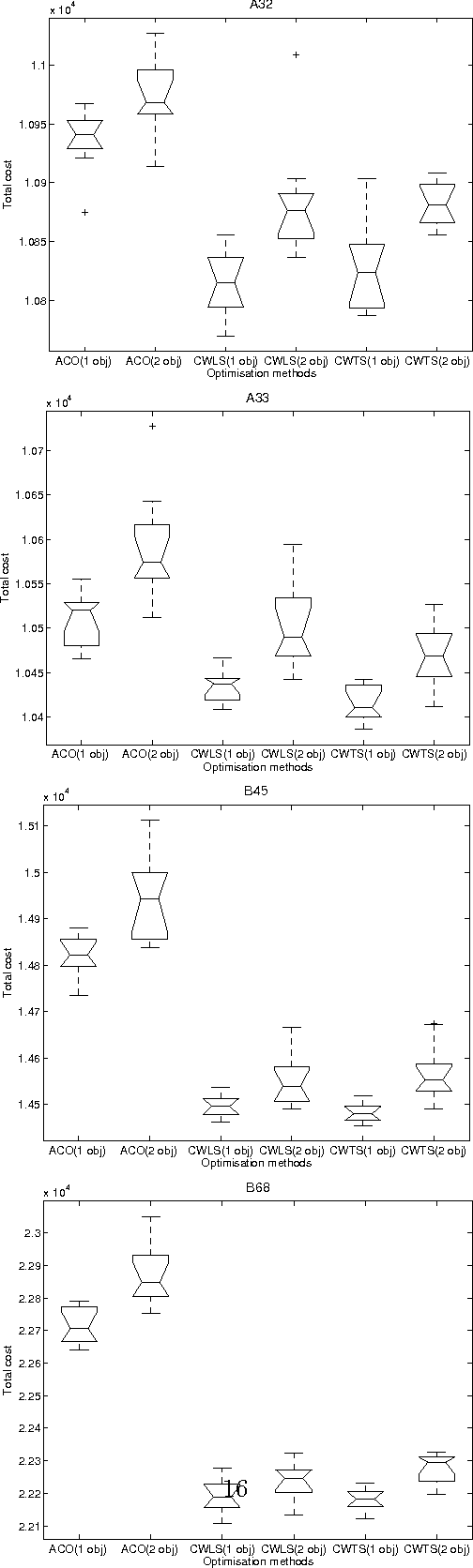
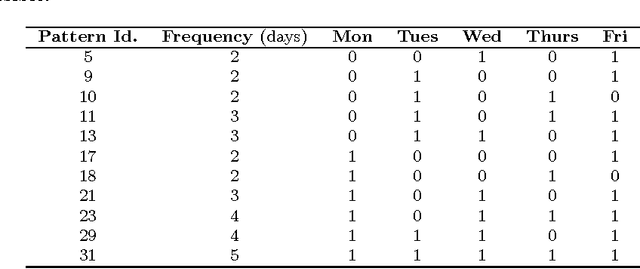
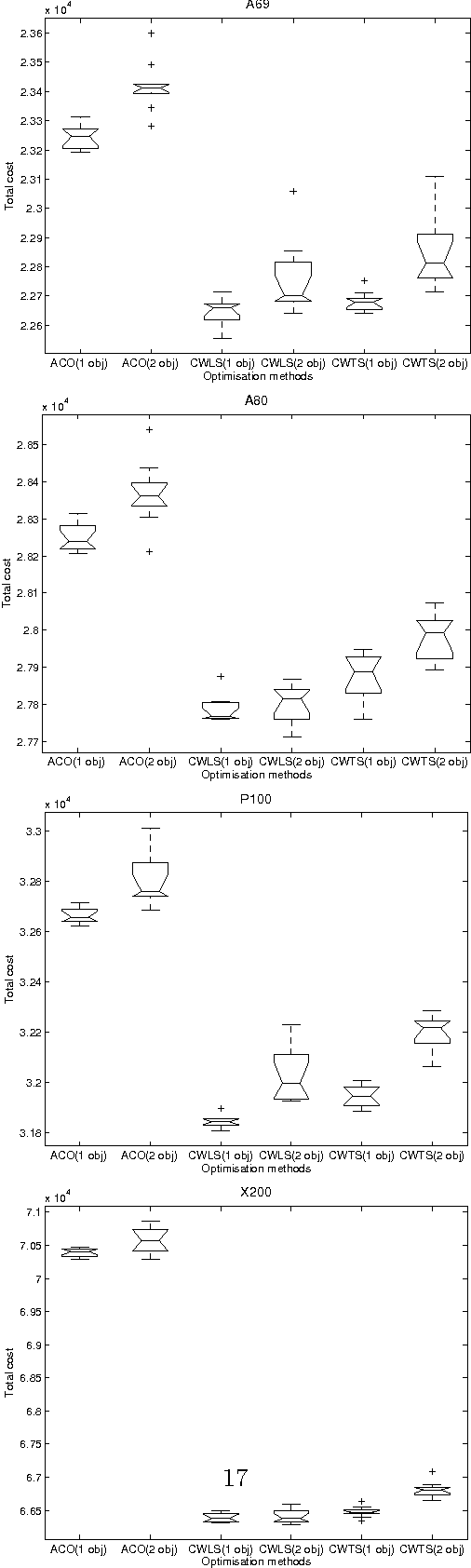
EVITA, standing for Evolutionary Inventory and Transportation Algorithm, is a two-level methodology designed to address the Inventory and Transportation Problem (ITP) in retail chains. The top level uses an evolutionary algorithm to obtain delivery patterns for each shop on a weekly basis so as to minimise the inventory costs, while the bottom level solves the Vehicle Routing Problem (VRP) for every day in order to obtain the minimum transport costs associated to a particular set of patterns. The aim of this paper is to investigate whether a multiobjective approach to this problem can yield any advantage over the previously used single objective approach. The analysis performed allows us to conclude that this is not the case and that the single objective approach is in gene- ral preferable for the ITP in the case studied. A further conclusion is that it is useful to employ a classical algorithm such as Clarke & Wright's as the seed for other metaheuristics like local search or tabu search in order to provide good results for the Vehicle Routing Problem.