 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOverview of PicTropes, a film trope dataset
Oct 26, 2018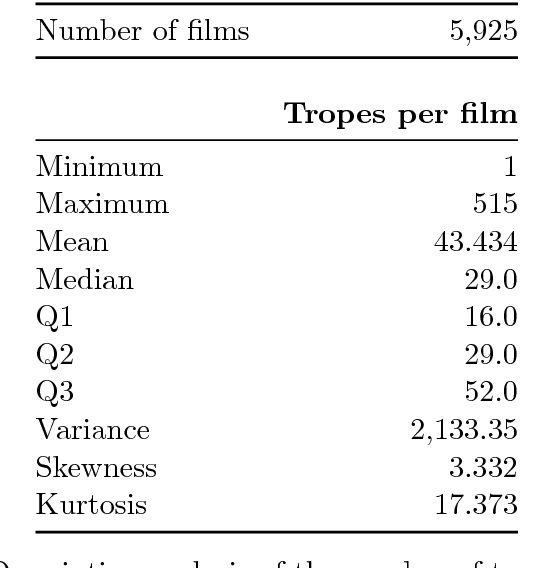
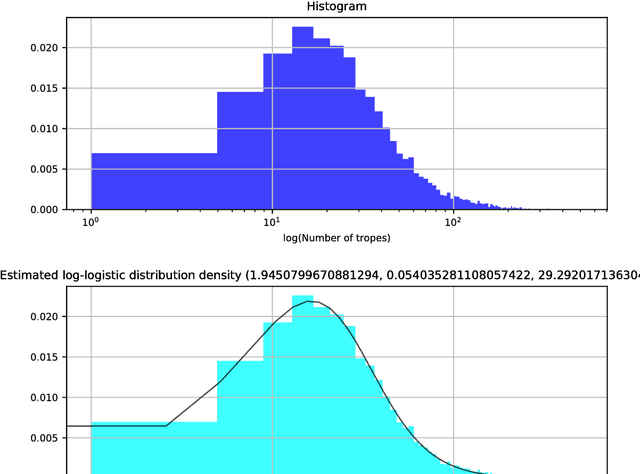
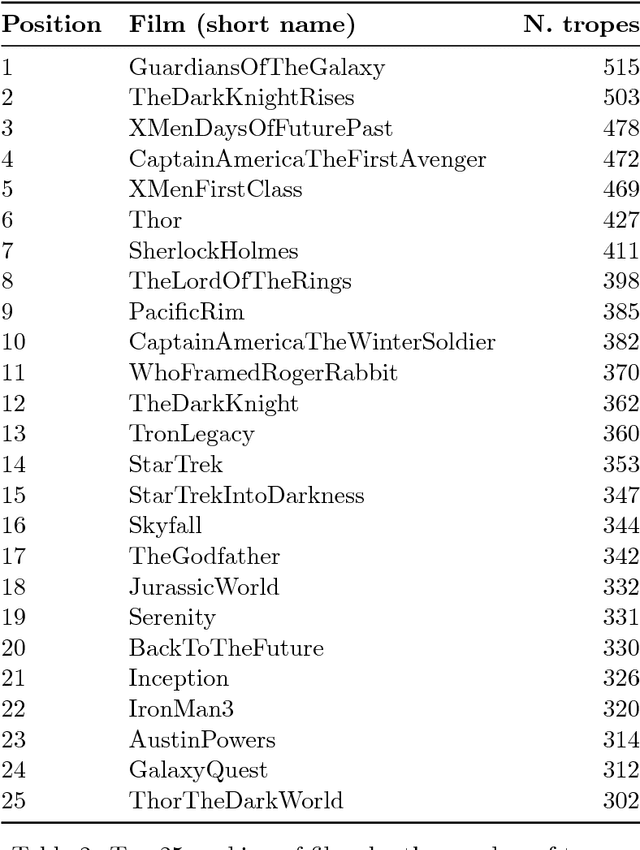
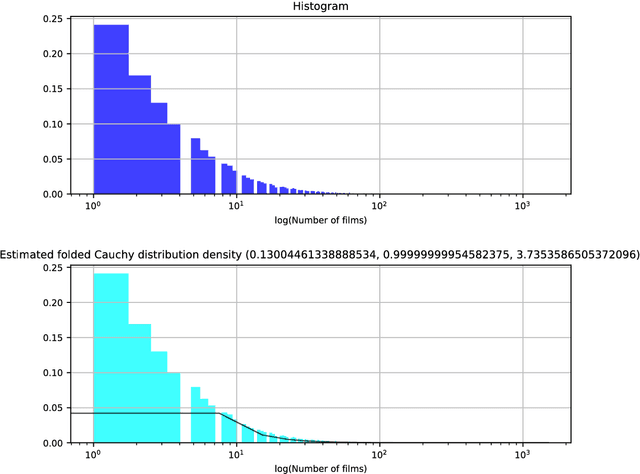
From the database DBTropes.org, we have created a dataset of films and the tropes that they use, which we have called PicTropes. In this report we provide the descriptive analysis and a further discussion on the dataset PicTropes: The extracted features will help us decide the best values for a future recommendation system and content generator, whereas the analysis of the distribution functions that fit the best will help us interpret the relation between the films and the tropes that were found inside them. Additionally, we provide rankings of the top-25 tropes and films, which will help us discuss and formulate questions to guide future extensions of the PicTropes dataset.
RedDwarfData: a simplified dataset of StarCraft matches
Dec 29, 2017The game Starcraft is one of the most interesting arenas to test new machine learning and computational intelligence techniques; however, StarCraft matches take a long time and creating a good dataset for training can be hard. Besides, analyzing match logs to extract the main characteristics can also be done in many different ways to the point that extracting and processing data itself can take an inordinate amount of time and of course, depending on what you choose, can bias learning algorithms. In this paper we present a simplified dataset extracted from the set of matches published by Robinson and Watson, which we have called RedDwarfData, containing several thousand matches processed to frames, so that temporal studies can also be undertaken. This dataset is available from GitHub under a free license. An initial analysis and appraisal of these matches is also made.