 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMetaheuristics "In the Large"
Dec 18, 2020Following decades of sustained improvement, metaheuristics are one of the great success stories of optimization research. However, in order for research in metaheuristics to avoid fragmentation and a lack of reproducibility, there is a pressing need for stronger scientific and computational infrastructure to support the development, analysis and comparison of new approaches. We argue that, via principled choice of infrastructure support, the field can pursue a higher level of scientific enquiry. We describe our vision and report on progress, showing how the adoption of common protocols for all metaheuristics can help liberate the potential of the field, easing the exploration of the design space of metaheuristics.
An Extensive Experimental Evaluation of Automated Machine Learning Methods for Recommending Classification Algorithms (Extended Version)
Sep 16, 2020

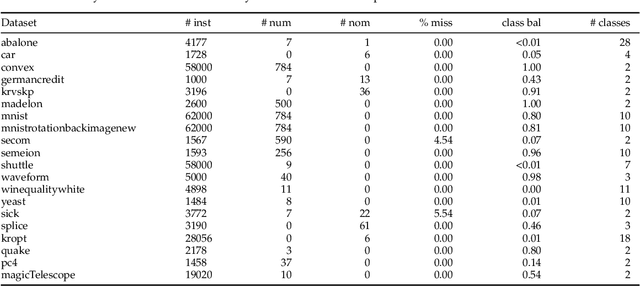
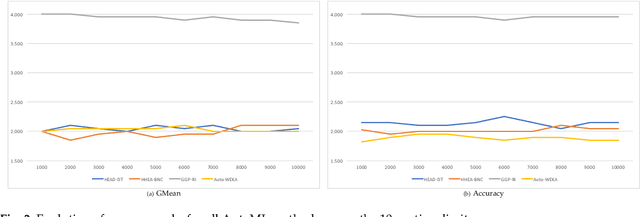
This paper presents an experimental comparison among four Automated Machine Learning (AutoML) methods for recommending the best classification algorithm for a given input dataset. Three of these methods are based on Evolutionary Algorithms (EAs), and the other is Auto-WEKA, a well-known AutoML method based on the Combined Algorithm Selection and Hyper-parameter optimisation (CASH) approach. The EA-based methods build classification algorithms from a single machine learning paradigm: either decision-tree induction, rule induction, or Bayesian network classification. Auto-WEKA combines algorithm selection and hyper-parameter optimisation to recommend classification algorithms from multiple paradigms. We performed controlled experiments where these four AutoML methods were given the same runtime limit for different values of this limit. In general, the difference in predictive accuracy of the three best AutoML methods was not statistically significant. However, the EA evolving decision-tree induction algorithms has the advantage of producing algorithms that generate interpretable classification models and that are more scalable to large datasets, by comparison with many algorithms from other learning paradigms that can be recommended by Auto-WEKA. We also observed that Auto-WEKA has shown meta-overfitting, a form of overfitting at the meta-learning level, rather than at the base-learning level.
Neural Architecture Search in Graph Neural Networks
Jul 31, 2020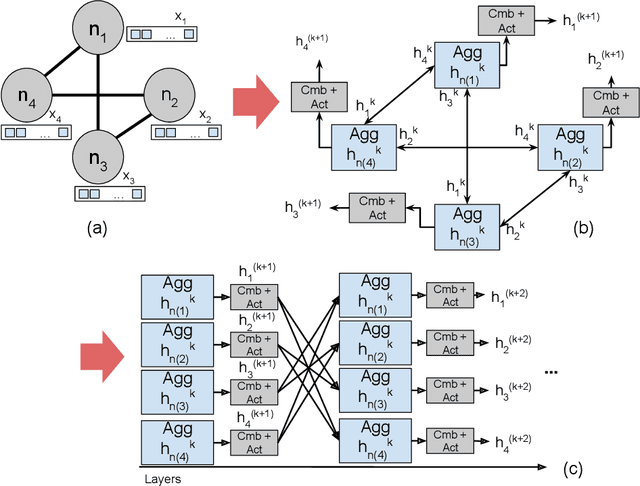



Performing analytical tasks over graph data has become increasingly interesting due to the ubiquity and large availability of relational information. However, unlike images or sentences, there is no notion of sequence in networks. Nodes (and edges) follow no absolute order, and it is hard for traditional machine learning (ML) algorithms to recognize a pattern and generalize their predictions on this type of data. Graph Neural Networks (GNN) successfully tackled this problem. They became popular after the generalization of the convolution concept to the graph domain. However, they possess a large number of hyperparameters and their design and optimization is currently hand-made, based on heuristics or empirical intuition. Neural Architecture Search (NAS) methods appear as an interesting solution to this problem. In this direction, this paper compares two NAS methods for optimizing GNN: one based on reinforcement learning and a second based on evolutionary algorithms. Results consider 7 datasets over two search spaces and show that both methods obtain similar accuracies to a random search, raising the question of how many of the search space dimensions are actually relevant to the problem.
A Robust Experimental Evaluation of Automated Multi-Label Classification Methods
May 16, 2020
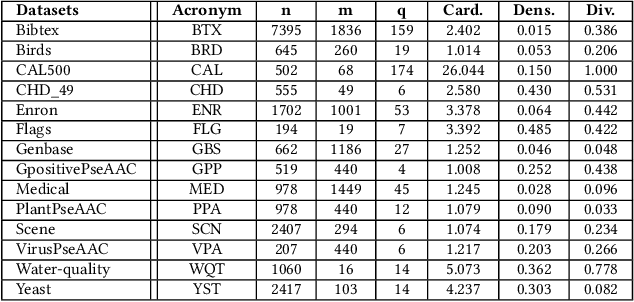
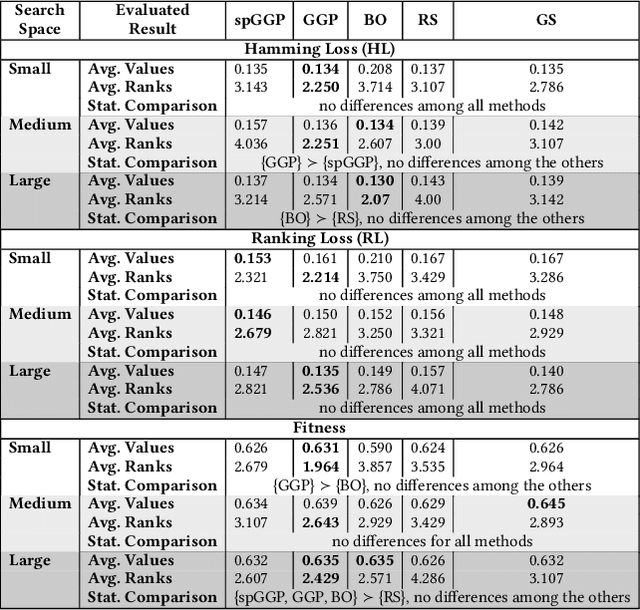
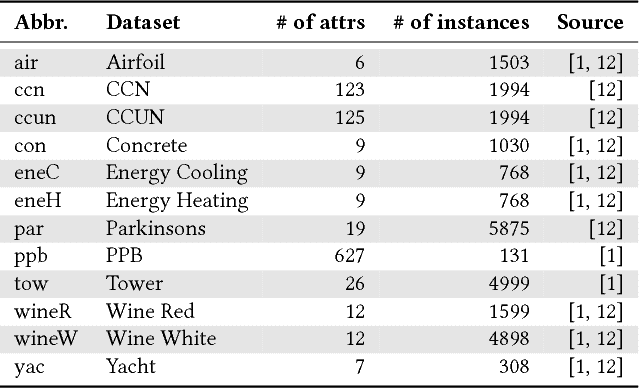
Automated Machine Learning (AutoML) has emerged to deal with the selection and configuration of algorithms for a given learning task. With the progression of AutoML, several effective methods were introduced, especially for traditional classification and regression problems. Apart from the AutoML success, several issues remain open. One issue, in particular, is the lack of ability of AutoML methods to deal with different types of data. Based on this scenario, this paper approaches AutoML for multi-label classification (MLC) problems. In MLC, each example can be simultaneously associated to several class labels, unlike the standard classification task, where an example is associated to just one class label. In this work, we provide a general comparison of five automated multi-label classification methods -- two evolutionary methods, one Bayesian optimization method, one random search and one greedy search -- on 14 datasets and three designed search spaces. Overall, we observe that the most prominent method is the one based on a canonical grammar-based genetic programming (GGP) search method, namely Auto-MEKA$_{GGP}$. Auto-MEKA$_{GGP}$ presented the best average results in our comparison and was statistically better than all the other methods in different search spaces and evaluated measures, except when compared to the greedy search method.
Multi-label classification search space in the MEKA software
Nov 28, 2018



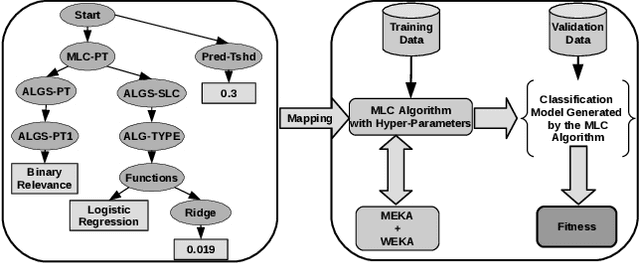
This technical report describes the multi-label classification (MLC) search space in the MEKA software, including the traditional/meta MLC algorithms, and the traditional/meta/pre-processing single-label classification (SLC) algorithms. The SLC search space is also studied because is part of MLC search space as several methods use problem transformation methods to create a solution (i.e., a classifier) for a MLC problem. This was done in order to understand better the MLC algorithms. Finally, we propose a grammar that formally expresses this understatement.
Solving the Exponential Growth of Symbolic Regression Trees in Geometric Semantic Genetic Programming
Apr 18, 2018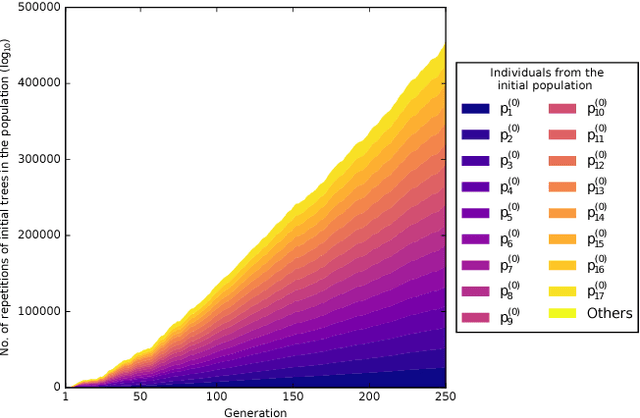
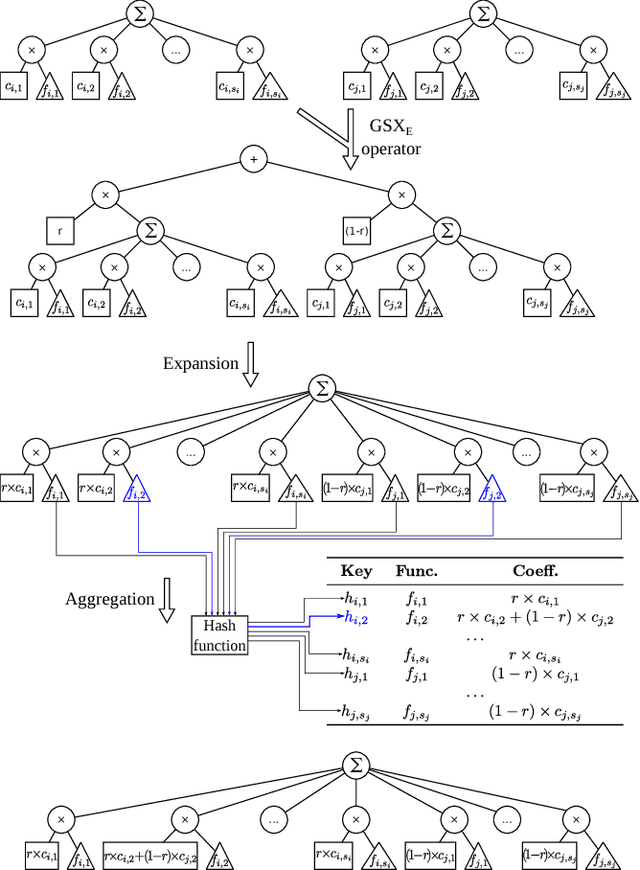
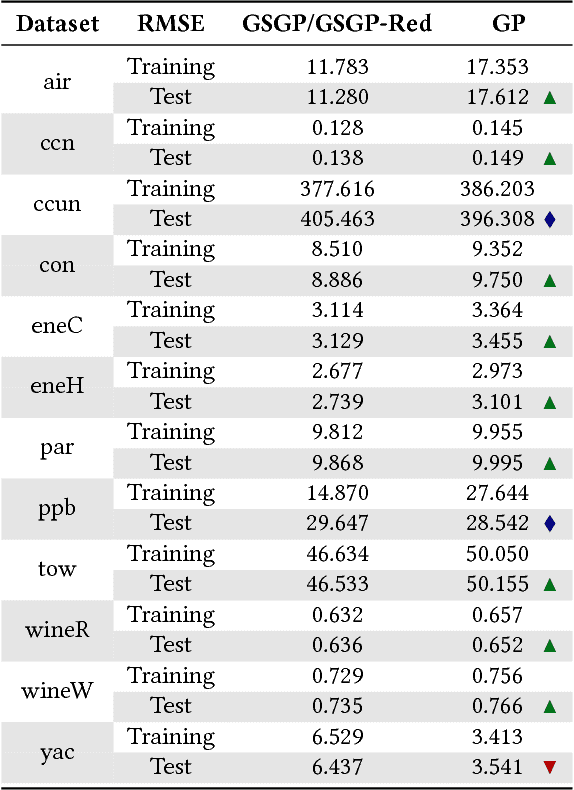
Advances in Geometric Semantic Genetic Programming (GSGP) have shown that this variant of Genetic Programming (GP) reaches better results than its predecessor for supervised machine learning problems, particularly in the task of symbolic regression. However, by construction, the geometric semantic crossover operator generates individuals that grow exponentially with the number of generations, resulting in solutions with limited use. This paper presents a new method for individual simplification named GSGP with Reduced trees (GSGP-Red). GSGP-Red works by expanding the functions generated by the geometric semantic operators. The resulting expanded function is guaranteed to be a linear combination that, in a second step, has its repeated structures and respective coefficients aggregated. Experiments in 12 real-world datasets show that it is not only possible to create smaller and completely equivalent individuals in competitive computational time, but also to reduce the number of nodes composing them by 58 orders of magnitude, on average.
How Noisy Data Affects Geometric Semantic Genetic Programming
Jul 04, 2017
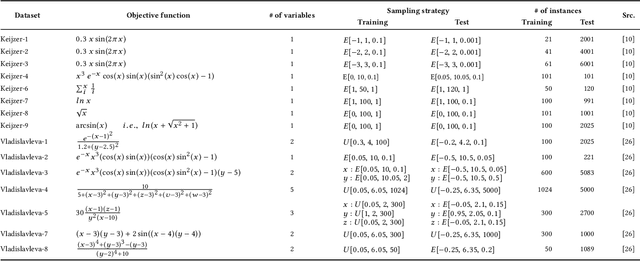

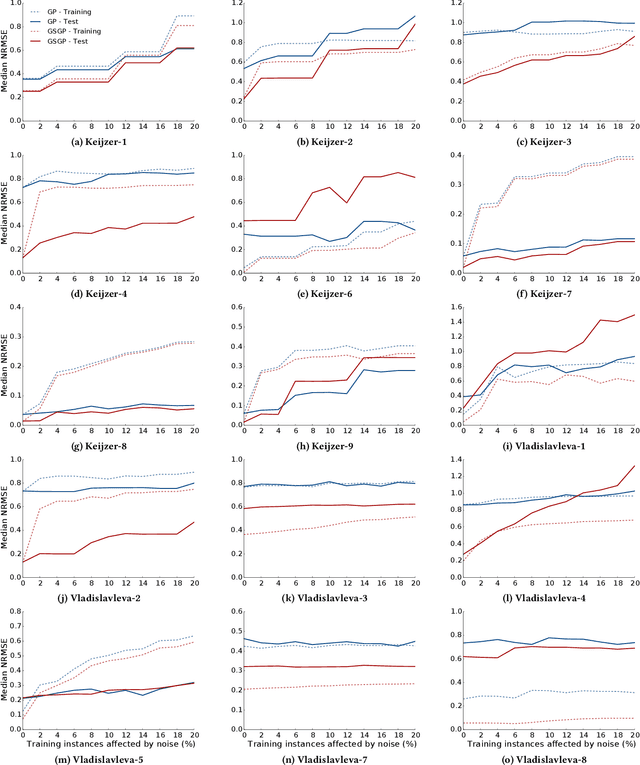
Noise is a consequence of acquiring and pre-processing data from the environment, and shows fluctuations from different sources---e.g., from sensors, signal processing technology or even human error. As a machine learning technique, Genetic Programming (GP) is not immune to this problem, which the field has frequently addressed. Recently, Geometric Semantic Genetic Programming (GSGP), a semantic-aware branch of GP, has shown robustness and high generalization capability. Researchers believe these characteristics may be associated with a lower sensibility to noisy data. However, there is no systematic study on this matter. This paper performs a deep analysis of the GSGP performance over the presence of noise. Using 15 synthetic datasets where noise can be controlled, we added different ratios of noise to the data and compared the results obtained with those of a canonical GP. The results show that, as we increase the percentage of noisy instances, the generalization performance degradation is more pronounced in GSGP than GP. However, in general, GSGP is more robust to noise than GP in the presence of up to 10% of noise, and presents no statistical difference for values higher than that in the test bed.
Selective Harvesting over Networks
Mar 15, 2017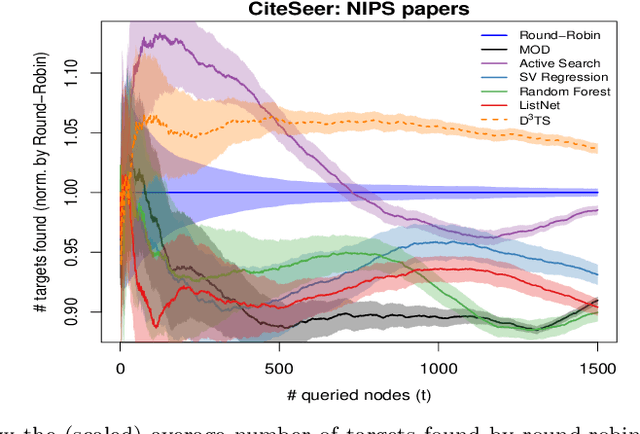

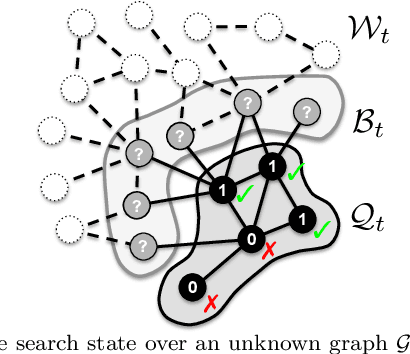
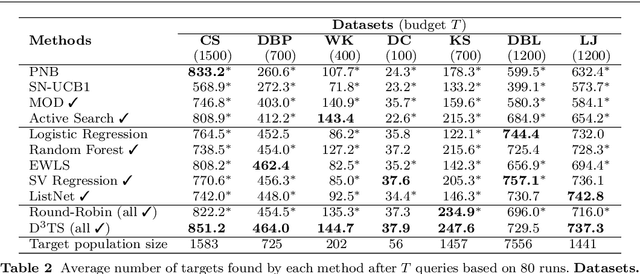
Active search (AS) on graphs focuses on collecting certain labeled nodes (targets) given global knowledge of the network topology and its edge weights under a query budget. However, in most networks, nodes, topology and edge weights are all initially unknown. We introduce selective harvesting, a variant of AS where the next node to be queried must be chosen among the neighbors of the current queried node set; the available training data for deciding which node to query is restricted to the subgraph induced by the queried set (and their node attributes) and their neighbors (without any node or edge attributes). Therefore, selective harvesting is a sequential decision problem, where we must decide which node to query at each step. A classifier trained in this scenario suffers from a tunnel vision effect: without recourse to independent sampling, the urge to query promising nodes forces classifiers to gather increasingly biased training data, which we show significantly hurts the performance of AS methods and standard classifiers. We find that it is possible to collect a much larger set of targets by using multiple classifiers, not by combining their predictions as an ensemble, but switching between classifiers used at each step, as a way to ease the tunnel vision effect. We discover that switching classifiers collects more targets by (a) diversifying the training data and (b) broadening the choices of nodes that can be queried next. This highlights an exploration, exploitation, and diversification trade-off in our problem that goes beyond the exploration and exploitation duality found in classic sequential decision problems. From these observations we propose D3TS, a method based on multi-armed bandits for non-stationary stochastic processes that enforces classifier diversity, matching or exceeding the performance of competing methods on seven real network datasets in our evaluation.