 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProtoAL: Interpretable Deep Active Learning with prototypes for medical imaging
Apr 06, 2024



The adoption of Deep Learning algorithms in the medical imaging field is a prominent area of research, with high potential for advancing AI-based Computer-aided diagnosis (AI-CAD) solutions. However, current solutions face challenges due to a lack of interpretability features and high data demands, prompting recent efforts to address these issues. In this study, we propose the ProtoAL method, where we integrate an interpretable DL model into the Deep Active Learning (DAL) framework. This approach aims to address both challenges by focusing on the medical imaging context and utilizing an inherently interpretable model based on prototypes. We evaluated ProtoAL on the Messidor dataset, achieving an area under the precision-recall curve of 0.79 while utilizing only 76.54\% of the available labeled data. These capabilities can enhances the practical usability of a DL model in the medical field, providing a means of trust calibration in domain experts and a suitable solution for learning in the data scarcity context often found.
Efficient Parameter Mining and Freezing for Continual Object Detection
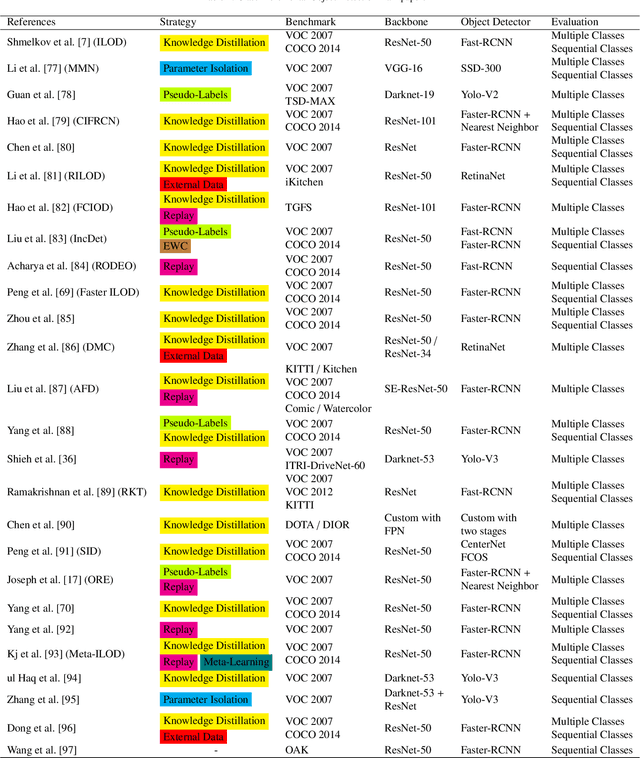
Feb 20, 2024Continual Object Detection is essential for enabling intelligent agents to interact proactively with humans in real-world settings. While parameter-isolation strategies have been extensively explored in the context of continual learning for classification, they have yet to be fully harnessed for incremental object detection scenarios. Drawing inspiration from prior research that focused on mining individual neuron responses and integrating insights from recent developments in neural pruning, we proposed efficient ways to identify which layers are the most important for a network to maintain the performance of a detector across sequential updates. The presented findings highlight the substantial advantages of layer-level parameter isolation in facilitating incremental learning within object detection models, offering promising avenues for future research and application in real-world scenarios.
Continual Object Detection: A review of definitions, strategies, and challenges
May 30, 2022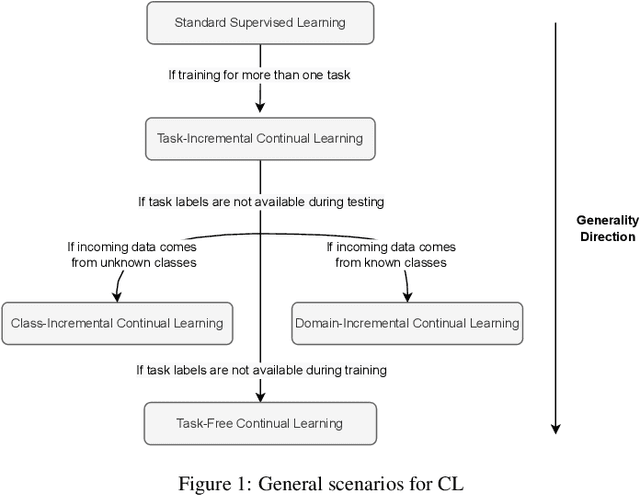


The field of Continual Learning investigates the ability to learn consecutive tasks without losing performance on those previously learned. Its focus has been mainly on incremental classification tasks. We believe that research in continual object detection deserves even more attention due to its vast range of applications in robotics and autonomous vehicles. This scenario is more complex than conventional classification given the occurrence of instances of classes that are unknown at the time, but can appear in subsequent tasks as a new class to be learned, resulting in missing annotations and conflicts with the background label. In this review, we analyze the current strategies proposed to tackle the problem of class-incremental object detection. Our main contributions are: (1) a short and systematic review of the methods that propose solutions to traditional incremental object detection scenarios; (2) A comprehensive evaluation of the existing approaches using a new metric to quantify the stability and plasticity of each technique in a standard way; (3) an overview of the current trends within continual object detection and a discussion of possible future research directions.
Forecasting Financial Market Structure from Network Features using Machine Learning
Oct 22, 2021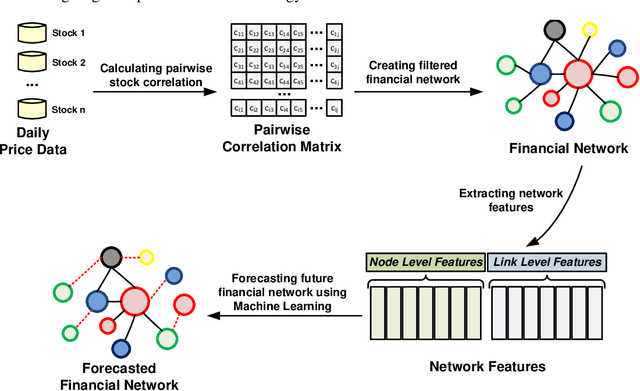



We propose a model that forecasts market correlation structure from link- and node-based financial network features using machine learning. For such, market structure is modeled as a dynamic asset network by quantifying time-dependent co-movement of asset price returns across company constituents of major global market indices. We provide empirical evidence using three different network filtering methods to estimate market structure, namely Dynamic Asset Graph (DAG), Dynamic Minimal Spanning Tree (DMST) and Dynamic Threshold Networks (DTN). Experimental results show that the proposed model can forecast market structure with high predictive performance with up to $40\%$ improvement over a time-invariant correlation-based benchmark. Non-pair-wise correlation features showed to be important compared to traditionally used pair-wise correlation measures for all markets studied, particularly in the long-term forecasting of stock market structure. Evidence is provided for stock constituents of the DAX30, EUROSTOXX50, FTSE100, HANGSENG50, NASDAQ100 and NIFTY50 market indices. Findings can be useful to improve portfolio selection and risk management methods, which commonly rely on a backward-looking covariance matrix to estimate portfolio risk.
An Extensive Experimental Evaluation of Automated Machine Learning Methods for Recommending Classification Algorithms (Extended Version)
Sep 16, 2020

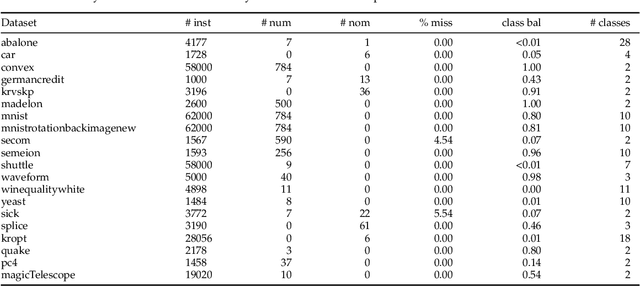
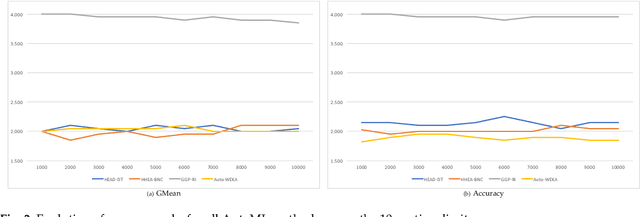
This paper presents an experimental comparison among four Automated Machine Learning (AutoML) methods for recommending the best classification algorithm for a given input dataset. Three of these methods are based on Evolutionary Algorithms (EAs), and the other is Auto-WEKA, a well-known AutoML method based on the Combined Algorithm Selection and Hyper-parameter optimisation (CASH) approach. The EA-based methods build classification algorithms from a single machine learning paradigm: either decision-tree induction, rule induction, or Bayesian network classification. Auto-WEKA combines algorithm selection and hyper-parameter optimisation to recommend classification algorithms from multiple paradigms. We performed controlled experiments where these four AutoML methods were given the same runtime limit for different values of this limit. In general, the difference in predictive accuracy of the three best AutoML methods was not statistically significant. However, the EA evolving decision-tree induction algorithms has the advantage of producing algorithms that generate interpretable classification models and that are more scalable to large datasets, by comparison with many algorithms from other learning paradigms that can be recommended by Auto-WEKA. We also observed that Auto-WEKA has shown meta-overfitting, a form of overfitting at the meta-learning level, rather than at the base-learning level.
A Preliminary Study on Hyperparameter Configuration for Human Activity Recognition
Oct 25, 2018



Human activity recognition (HAR) is a classification task that aims to classify human activities or predict human behavior by means of features extracted from sensors data. Typical HAR systems use wearable sensors and/or handheld and mobile devices with built-in sensing capabilities. Due to the widespread use of smartphones and to the inclusion of various sensors in all contemporary smartphones (e.g., accelerometers and gyroscopes), they are commonly used for extracting and collecting data from sensors and even for implementing HAR systems. When using mobile devices, e.g., smartphones, HAR systems need to deal with several constraints regarding battery, computation and memory. These constraints enforce the need of a system capable of managing its resources and maintain acceptable levels of classification accuracy. Moreover, several factors can influence activity recognition, such as classification models, sensors availability and size of data window for feature extraction, making stable accuracy a difficult task. In this paper, we present a semi-supervised classifier and a study regarding the influence of hyperparameter configuration in classification accuracy, depending on the user and the activities performed by each user. This study focuses on sensing data provided by the PAMAP2 dataset. Experimental results show that it is possible to maintain classification accuracy by adjusting hyperparameters, like window size and windows overlap factor, depending on user and activity performed. These experiments motivate the development of a system able to automatically adapt hyperparameter settings for the activity performed by each user.
Towards Reproducible Empirical Research in Meta-Learning
Aug 30, 2018
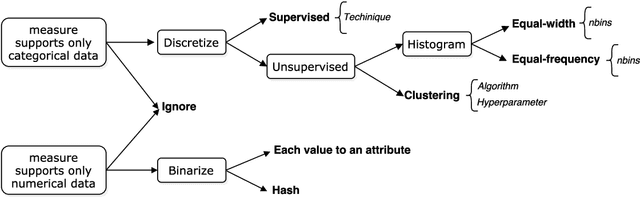
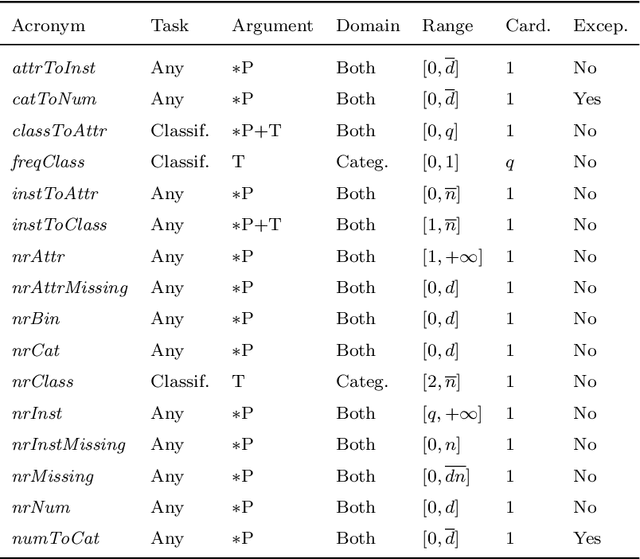
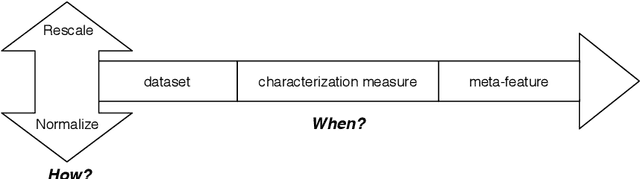
Meta-learning is increasingly used to support the recommendation of machine learning algorithms and their configurations. Such recommendations are made based on meta-data, consisting of performance evaluations of algorithms on prior datasets, as well as characterizations of these datasets. These characterizations, also called meta-features, describe properties of the data which are predictive for the performance of machine learning algorithms trained on them. Unfortunately, despite being used in a large number of studies, meta-features are not uniformly described and computed, making many empirical studies irreproducible and hard to compare. This paper aims to remedy this by systematizing and standardizing data characterization measures used in meta-learning, and performing an in-depth analysis of their utility. Moreover, it presents MFE, a new tool for extracting meta-features from datasets and identify more subtle reproducibility issues in the literature, proposing guidelines for data characterization that strengthen reproducible empirical research in meta-learning.
Algorithm Selection for Collaborative Filtering: the influence of graph metafeatures and multicriteria metatargets
Jul 23, 2018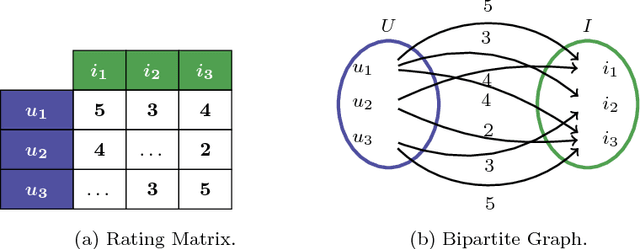
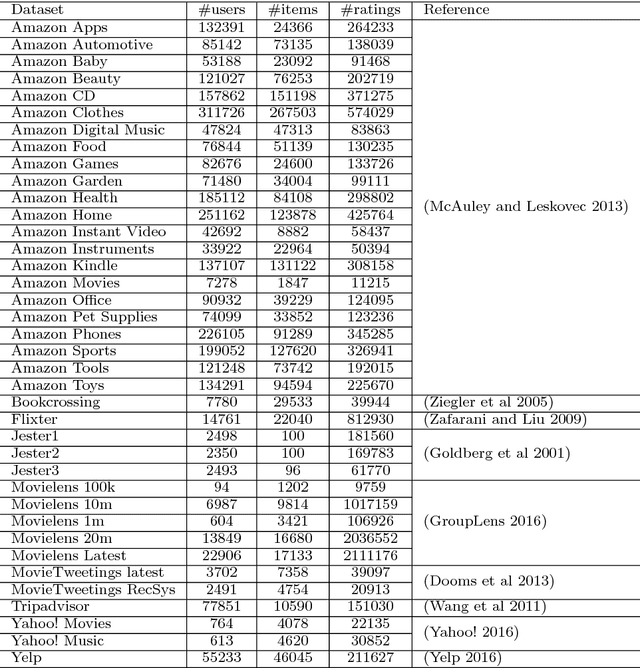
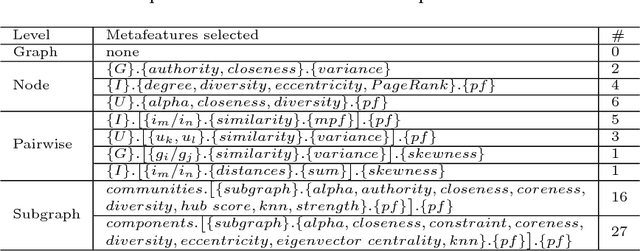
To select the best algorithm for a new problem is an expensive and difficult task. However, there are automatic solutions to address this problem: using Metalearning, which takes advantage of problem characteristics (i.e. metafeatures), one is able to predict the relative performance of algorithms. In the Collaborative Filtering scope, recent works have proposed diverse metafeatures describing several dimensions of this problem. Despite interesting and effective findings, it is still unknown whether these are the most effective metafeatures. Hence, this work proposes a new set of graph metafeatures, which approach the Collaborative Filtering problem from a Graph Theory perspective. Furthermore, in order to understand whether metafeatures from multiple dimensions are a better fit, we investigate the effects of comprehensive metafeatures. These metafeatures are a selection of the best metafeatures from all existing Collaborative Filtering metafeatures. The impact of the most representative metafeatures is investigated in a controlled experimental setup. Another contribution we present is the use of a Pareto-Efficient ranking procedure to create multicriteria metatargets. These new rankings of algorithms, which take into account multiple evaluation measures, allow to explore the algorithm selection problem in a fairer and more detailed way. According to the experimental results, the graph metafeatures are a good alternative to related work metafeatures. However, the results have shown that the feature selection procedure used to create the comprehensive metafeatures is is not effective, since there is no gain in predictive performance. Finally, an extensive metaknowledge analysis was conducted to identify the most influential metafeatures.