 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Reproducible Empirical Research in Meta-Learning
Aug 30, 2018
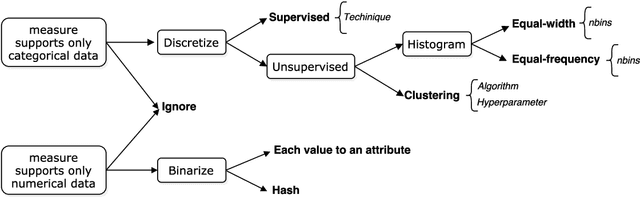
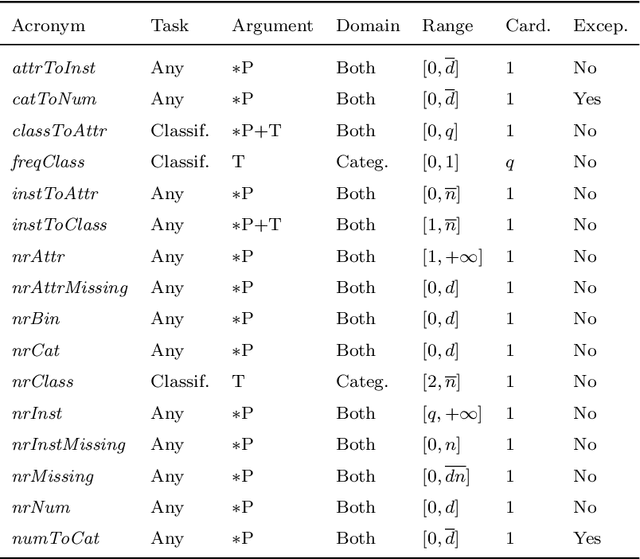
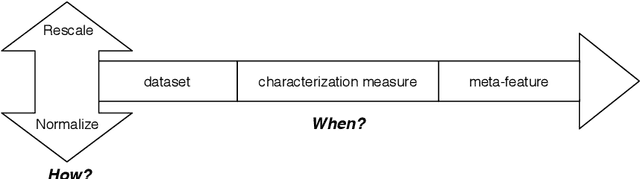
Meta-learning is increasingly used to support the recommendation of machine learning algorithms and their configurations. Such recommendations are made based on meta-data, consisting of performance evaluations of algorithms on prior datasets, as well as characterizations of these datasets. These characterizations, also called meta-features, describe properties of the data which are predictive for the performance of machine learning algorithms trained on them. Unfortunately, despite being used in a large number of studies, meta-features are not uniformly described and computed, making many empirical studies irreproducible and hard to compare. This paper aims to remedy this by systematizing and standardizing data characterization measures used in meta-learning, and performing an in-depth analysis of their utility. Moreover, it presents MFE, a new tool for extracting meta-features from datasets and identify more subtle reproducibility issues in the literature, proposing guidelines for data characterization that strengthen reproducible empirical research in meta-learning.
How Complex is your classification problem? A survey on measuring classification complexity
Aug 10, 2018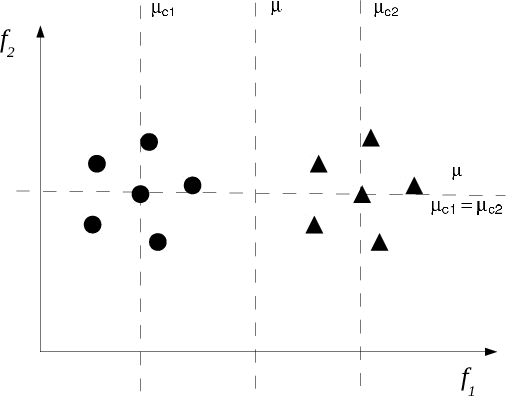
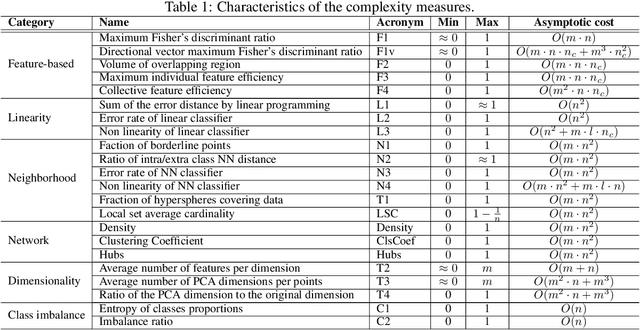
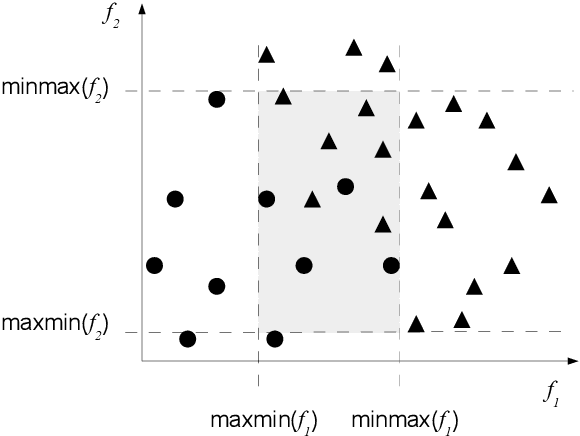
Extracting characteristics from the training datasets of classification problems has proven effective in a number of meta-analyses. Among them, measures of classification complexity can estimate the difficulty in separating the data points into their expected classes. Descriptors of the spatial distribution of the data and estimates of the shape and size of the decision boundary are among the existent measures for this characterization. This information can support the formulation of new data-driven pre-processing and pattern recognition techniques, which can in turn be focused on challenging characteristics of the problems. This paper surveys and analyzes measures which can be extracted from the training datasets in order to characterize the complexity of the respective classification problems. Their use in recent literature is also reviewed and discussed, allowing to prospect opportunities for future work in the area. Finally, descriptions are given on an R package named Extended Complexity Library (ECoL) that implements a set of complexity measures and is made publicly available.