 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevisiting Gene Ontology Knowledge Discovery with Hierarchical Feature Selection and Virtual Study Group of AI Agents
Mar 20, 2026Large language models have achieved great success in multiple challenging tasks, and their capacity can be further boosted by the emerging agentic AI techniques. This new computing paradigm has already started revolutionising the traditional scientific discovery pipelines. In this work, we propose a novel agentic AI-based knowledge discovery-oriented virtual study group that aims to extract meaningful ageing-related biological knowledge considering highly ageing-related Gene Ontology terms that are selected by hierarchical feature selection methods. We investigate the performance of the proposed agentic AI framework by considering four different model organisms' ageing-related Gene Ontology terms and validate the biological findings by reviewing existing research articles. It is found that the majority of the AI agent-generated scientific claims can be supported by existing literatures and the proposed internal mechanisms of the virtual study group also play an important role in the designed agentic AI-based knowledge discovery framework.
Positive-Unlabelled Learning for Identifying New Candidate Dietary Restriction-related Genes among Ageing-related Genes
Jun 14, 2024



Dietary Restriction (DR) is one of the most popular anti-ageing interventions, prompting exhaustive research into genes associated with its mechanisms. Recently, Machine Learning (ML) has been explored to identify potential DR-related genes among ageing-related genes, aiming to minimize costly wet lab experiments needed to expand our knowledge on DR. However, to train a model from positive (DR-related) and negative (non-DR-related) examples, existing ML methods naively label genes without known DR relation as negative examples, assuming that lack of DR-related annotation for a gene represents evidence of absence of DR-relatedness, rather than absence of evidence; this hinders the reliability of the negative examples (non-DR-related genes) and the method's ability to identify novel DR-related genes. This work introduces a novel gene prioritization method based on the two-step Positive-Unlabelled (PU) Learning paradigm: using a similarity-based, KNN-inspired approach, our method first selects reliable negative examples among the genes without known DR associations. Then, these reliable negatives and all known positives are used to train a classifier that effectively differentiates DR-related and non-DR-related genes, which is finally employed to generate a more reliable ranking of promising genes for novel DR-relatedness. Our method significantly outperforms the existing state-of-the-art non-PU approach for DR-relatedness prediction in three relevant performance metrics. In addition, curation of existing literature finds support for the top-ranked candidate DR-related genes identified by our model.
Automated Machine Learning for Positive-Unlabelled Learning
Jan 12, 2024Positive-Unlabelled (PU) learning is a growing field of machine learning that aims to learn classifiers from data consisting of labelled positive and unlabelled instances, which can be in reality positive or negative, but whose label is unknown. An extensive number of methods have been proposed to address PU learning over the last two decades, so many so that selecting an optimal method for a given PU learning task presents a challenge. Our previous work has addressed this by proposing GA-Auto-PU, the first Automated Machine Learning (Auto-ML) system for PU learning. In this work, we propose two new Auto-ML systems for PU learning: BO-Auto-PU, based on a Bayesian Optimisation approach, and EBO-Auto-PU, based on a novel evolutionary/Bayesian optimisation approach. We also present an extensive evaluation of the three Auto-ML systems, comparing them to each other and to well-established PU learning methods across 60 datasets (20 real-world datasets, each with 3 versions in terms of PU learning characteristics).
Hierarchical Dependency Constrained Tree Augmented Naive Bayes Classifiers for Hierarchical Feature Spaces
Feb 08, 2022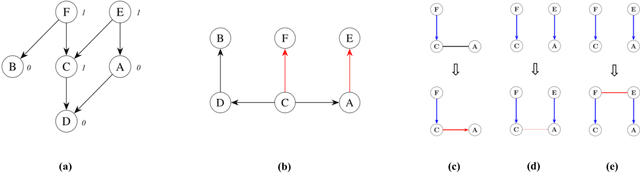
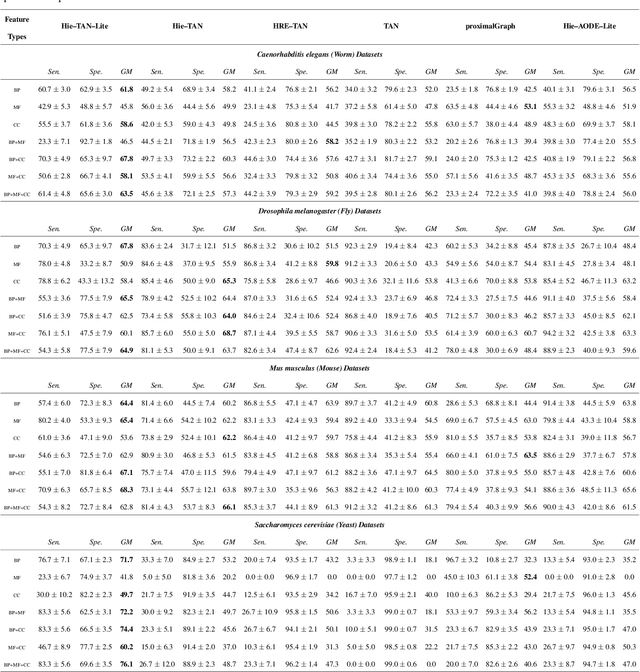
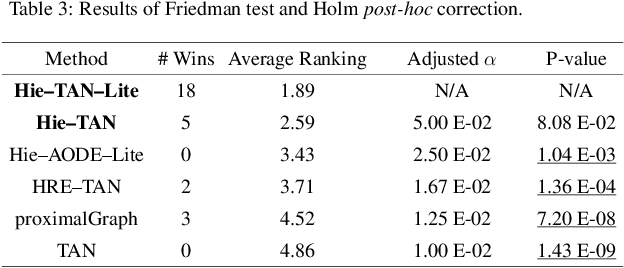
The Tree Augmented Naive Bayes (TAN) classifier is a type of probabilistic graphical model that constructs a single-parent dependency tree to estimate the distribution of the data. In this work, we propose two novel Hierarchical dependency-based Tree Augmented Naive Bayes algorithms, i.e. Hie-TAN and Hie-TAN-Lite. Both methods exploit the pre-defined parent-child (generalisation-specialisation) relationships between features as a type of constraint to learn the tree representation of dependencies among features, whilst the latter further eliminates the hierarchical redundancy during the classifier learning stage. The experimental results showed that Hie-TAN successfully obtained better predictive performance than several other hierarchical dependency constrained classification algorithms, and its predictive performance was further improved by eliminating the hierarchical redundancy, as suggested by the higher accuracy obtained by Hie-TAN-Lite.
An Extensive Experimental Evaluation of Automated Machine Learning Methods for Recommending Classification Algorithms (Extended Version)
Sep 16, 2020

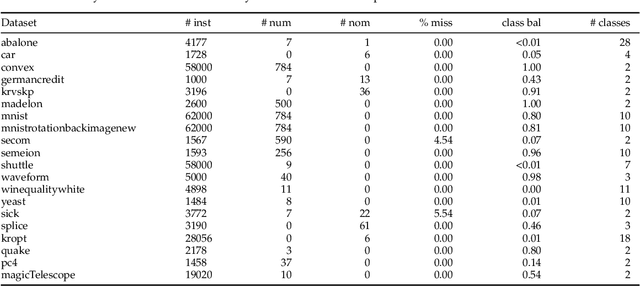
This paper presents an experimental comparison among four Automated Machine Learning (AutoML) methods for recommending the best classification algorithm for a given input dataset. Three of these methods are based on Evolutionary Algorithms (EAs), and the other is Auto-WEKA, a well-known AutoML method based on the Combined Algorithm Selection and Hyper-parameter optimisation (CASH) approach. The EA-based methods build classification algorithms from a single machine learning paradigm: either decision-tree induction, rule induction, or Bayesian network classification. Auto-WEKA combines algorithm selection and hyper-parameter optimisation to recommend classification algorithms from multiple paradigms. We performed controlled experiments where these four AutoML methods were given the same runtime limit for different values of this limit. In general, the difference in predictive accuracy of the three best AutoML methods was not statistically significant. However, the EA evolving decision-tree induction algorithms has the advantage of producing algorithms that generate interpretable classification models and that are more scalable to large datasets, by comparison with many algorithms from other learning paradigms that can be recommended by Auto-WEKA. We also observed that Auto-WEKA has shown meta-overfitting, a form of overfitting at the meta-learning level, rather than at the base-learning level.
A Robust Experimental Evaluation of Automated Multi-Label Classification Methods
May 16, 2020
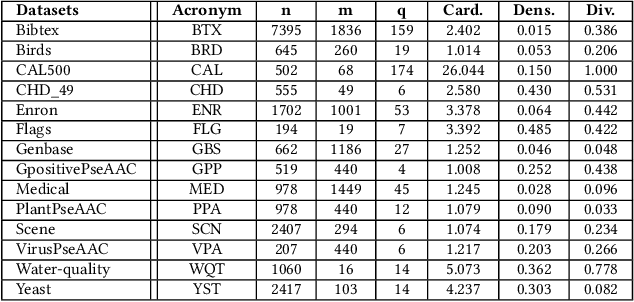
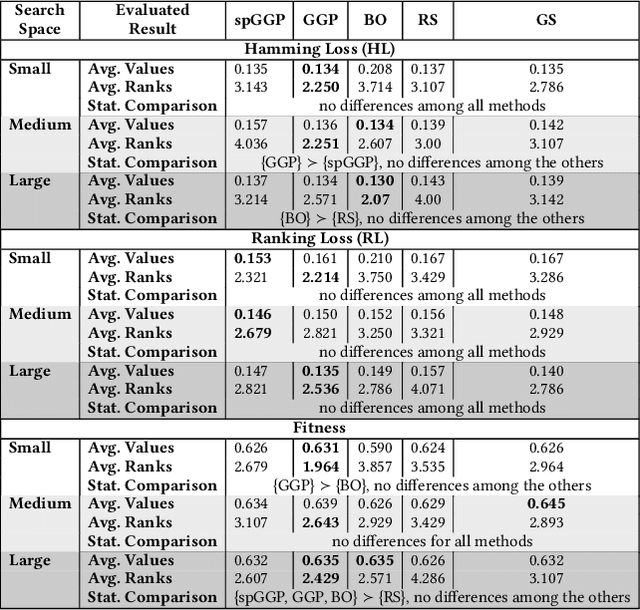
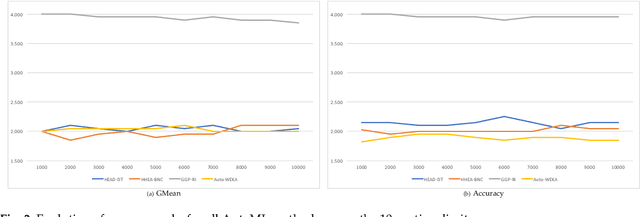
Automated Machine Learning (AutoML) has emerged to deal with the selection and configuration of algorithms for a given learning task. With the progression of AutoML, several effective methods were introduced, especially for traditional classification and regression problems. Apart from the AutoML success, several issues remain open. One issue, in particular, is the lack of ability of AutoML methods to deal with different types of data. Based on this scenario, this paper approaches AutoML for multi-label classification (MLC) problems. In MLC, each example can be simultaneously associated to several class labels, unlike the standard classification task, where an example is associated to just one class label. In this work, we provide a general comparison of five automated multi-label classification methods -- two evolutionary methods, one Bayesian optimization method, one random search and one greedy search -- on 14 datasets and three designed search spaces. Overall, we observe that the most prominent method is the one based on a canonical grammar-based genetic programming (GGP) search method, namely Auto-MEKA$_{GGP}$. Auto-MEKA$_{GGP}$ presented the best average results in our comparison and was statistically better than all the other methods in different search spaces and evaluated measures, except when compared to the greedy search method.
Multi-label classification search space in the MEKA software
Nov 28, 2018



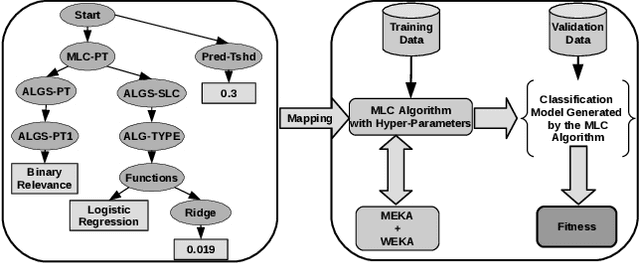
This technical report describes the multi-label classification (MLC) search space in the MEKA software, including the traditional/meta MLC algorithms, and the traditional/meta/pre-processing single-label classification (SLC) algorithms. The SLC search space is also studied because is part of MLC search space as several methods use problem transformation methods to create a solution (i.e., a classifier) for a MLC problem. This was done in order to understand better the MLC algorithms. Finally, we propose a grammar that formally expresses this understatement.
A New Hierarchical Redundancy Eliminated Tree Augmented Naive Bayes Classifier for Coping with Gene Ontology-based Features
Jul 06, 2016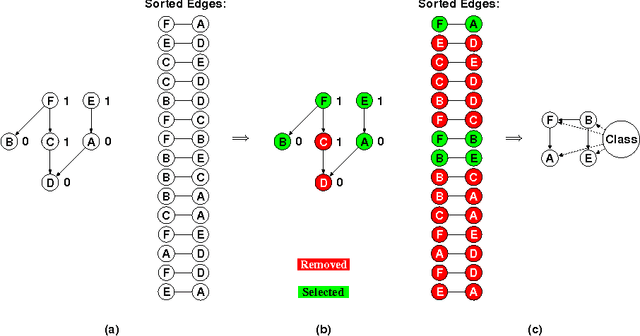

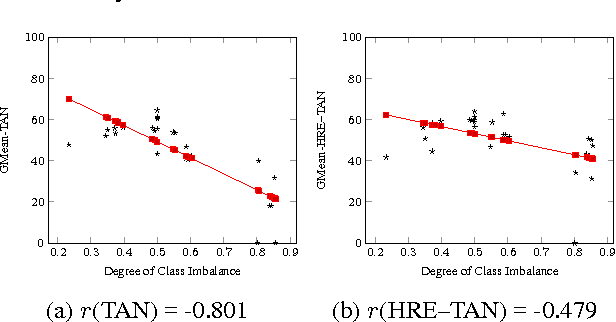
The Tree Augmented Naive Bayes classifier is a type of probabilistic graphical model that can represent some feature dependencies. In this work, we propose a Hierarchical Redundancy Eliminated Tree Augmented Naive Bayes (HRE-TAN) algorithm, which considers removing the hierarchical redundancy during the classifier learning process, when coping with data containing hierarchically structured features. The experiments showed that HRE-TAN obtains significantly better predictive performance than the conventional Tree Augmented Naive Bayes classifier, and enhanced the robustness against imbalanced class distributions, in aging-related gene datasets with Gene Ontology terms used as features.