 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClosing the Alignment-Maturity Gap in Federated Prototype Learning
Jun 01, 2026Learning discriminative visual representations from distributed, heterogeneous data is a fundamental challenge in Federated Learning (FL). Prototype-based methods address statistical heterogeneity by sharing class-level representations across clients but create a distance-dependent gradient pressure that is particularly severe during early training rounds: alignment pressure applied to immature global prototypes, aggregated from noisy local representations, generates large gradients that suppress the emergence of local discriminative structure. The result is a poorly organized embedding space and degraded recognition performance, particularly under severe non-IID conditions. We propose FedSAP, a framework that stabilises federated representation learning through two complementary mechanisms: a deterministic alignment curriculum that delays global alignment until local representations become stable and a geometry-driven proxy separation loss that enforces inter-class structure on the unit hypersphere using the existing prototype bank without introducing additional parameters or communication overhead. Together, these mechanisms produce compact, well-separated class clusters without altering the underlying communication protocol between federation's participants. Experiments across three benchmarks and varying degrees of heterogeneity show gains of up to 4 percentage points over the prototype-based baselines evaluated, with improvements most pronounced under high heterogeneity. The representational nature of our framework further enables a straightforward extension to semi-supervised settings, where unlabelled data is incorporated with minimal modification, underscoring the generality of scheduled alignment as a design principle.
FedHENet: A Frugal Federated Learning Framework for Heterogeneous Environments
Feb 13, 2026Federated Learning (FL) enables collaborative training without centralizing data, essential for privacy compliance in real-world scenarios involving sensitive visual information. Most FL approaches rely on expensive, iterative deep network optimization, which still risks privacy via shared gradients. In this work, we propose FedHENet, extending the FedHEONN framework to image classification. By using a fixed, pre-trained feature extractor and learning only a single output layer, we avoid costly local fine-tuning. This layer is learned by analytically aggregating client knowledge in a single round of communication using homomorphic encryption (HE). Experiments show that FedHENet achieves competitive accuracy compared to iterative FL baselines while demonstrating superior stability performance and up to 70\% better energy efficiency. Crucially, our method is hyperparameter-free, removing the carbon footprint associated with hyperparameter tuning in standard FL. Code available in https://github.com/AlejandroDopico2/FedHENet/
A robust methodology for long-term sustainability evaluation of Machine Learning models
Nov 11, 2025Sustainability and efficiency have become essential considerations in the development and deployment of Artificial Intelligence systems, yet existing regulatory and reporting practices lack standardized, model-agnostic evaluation protocols. Current assessments often measure only short-term experimental resource usage and disproportionately emphasize batch learning settings, failing to reflect real-world, long-term AI lifecycles. In this work, we propose a comprehensive evaluation protocol for assessing the long-term sustainability of ML models, applicable to both batch and streaming learning scenarios. Through experiments on diverse classification tasks using a range of model types, we demonstrate that traditional static train-test evaluations do not reliably capture sustainability under evolving data and repeated model updates. Our results show that long-term sustainability varies significantly across models, and in many cases, higher environmental cost yields little performance benefit.
Positive-Unlabelled Learning for Improving Image-based Recommender System Explainability
Jul 09, 2024
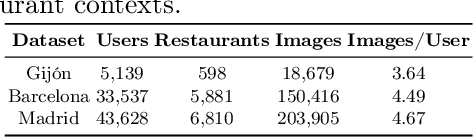

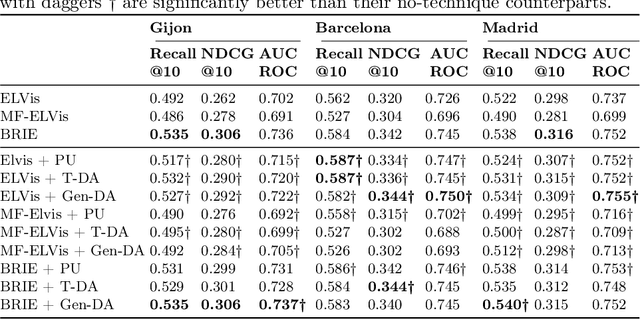
Among the existing approaches for visual-based Recommender System (RS) explainability, utilizing user-uploaded item images as efficient, trustable explanations is a promising option. However, current models following this paradigm assume that, for any user, all images uploaded by other users can be considered negative training examples (i.e. bad explanatory images), an inadvertedly naive labelling assumption that contradicts the rationale of the approach. This work proposes a new explainer training pipeline by leveraging Positive-Unlabelled (PU) Learning techniques to train image-based explainer with refined subsets of reliable negative examples for each user selected through a novel user-personalized, two-step, similarity-based PU Learning algorithm. Computational experiments show this PU-based approach outperforms the state-of-the-art non-PU method in six popular real-world datasets, proving that an improvement of visual-based RS explainability can be achieved by maximizing training data quality rather than increasing model complexity.
Positive-Unlabelled Learning for Identifying New Candidate Dietary Restriction-related Genes among Ageing-related Genes
Jun 14, 2024



Dietary Restriction (DR) is one of the most popular anti-ageing interventions, prompting exhaustive research into genes associated with its mechanisms. Recently, Machine Learning (ML) has been explored to identify potential DR-related genes among ageing-related genes, aiming to minimize costly wet lab experiments needed to expand our knowledge on DR. However, to train a model from positive (DR-related) and negative (non-DR-related) examples, existing ML methods naively label genes without known DR relation as negative examples, assuming that lack of DR-related annotation for a gene represents evidence of absence of DR-relatedness, rather than absence of evidence; this hinders the reliability of the negative examples (non-DR-related genes) and the method's ability to identify novel DR-related genes. This work introduces a novel gene prioritization method based on the two-step Positive-Unlabelled (PU) Learning paradigm: using a similarity-based, KNN-inspired approach, our method first selects reliable negative examples among the genes without known DR associations. Then, these reliable negatives and all known positives are used to train a classifier that effectively differentiates DR-related and non-DR-related genes, which is finally employed to generate a more reliable ranking of promising genes for novel DR-relatedness. Our method significantly outperforms the existing state-of-the-art non-PU approach for DR-relatedness prediction in three relevant performance metrics. In addition, curation of existing literature finds support for the top-ranked candidate DR-related genes identified by our model.
Beyond RMSE and MAE: Introducing EAUC to unmask hidden bias and unfairness in dyadic regression models
Jan 19, 2024Dyadic regression models, which predict real-valued outcomes for pairs of entities, are fundamental in many domains (e.g. predicting the rating of a user to a product in Recommender Systems) and promising and under exploration in many others (e.g. approximating the adequate dosage of a drug for a patient in personalized pharmacology). In this work, we demonstrate that non-uniformity in the observed value distributions of individual entities leads to severely biased predictions in state-of-the-art models, skewing predictions towards the average of observed past values for the entity and providing worse-than-random predictive power in eccentric yet equally important cases. We show that the usage of global error metrics like Root Mean Squared Error (RMSE) and Mean Absolute Error (MAE) is insufficient to capture this phenomenon, which we name eccentricity bias, and we introduce Eccentricity-Area Under the Curve (EAUC) as a new complementary metric that can quantify it in all studied models and datasets. We also prove the adequateness of EAUC by using naive de-biasing corrections to demonstrate that a lower model bias correlates with a lower EAUC and vice-versa. This work contributes a bias-aware evaluation of dyadic regression models to avoid potential unfairness and risks in critical real-world applications of such systems.
An effective and efficient green federated learning method for one-layer neural networks
Dec 22, 2023Nowadays, machine learning algorithms continue to grow in complexity and require a substantial amount of computational resources and energy. For these reasons, there is a growing awareness of the development of new green algorithms and distributed AI can contribute to this. Federated learning (FL) is one of the most active research lines in machine learning, as it allows the training of collaborative models in a distributed way, an interesting option in many real-world environments, such as the Internet of Things, allowing the use of these models in edge computing devices. In this work, we present a FL method, based on a neural network without hidden layers, capable of generating a global collaborative model in a single training round, unlike traditional FL methods that require multiple rounds for convergence. This allows obtaining an effective and efficient model that simplifies the management of the training process. Moreover, this method preserve data privacy by design, a crucial aspect in current data protection regulations. We conducted experiments with large datasets and a large number of federated clients. Despite being based on a network model without hidden layers, it maintains in all cases competitive accuracy results compared to more complex state-of-the-art machine learning models. Furthermore, we show that the method performs equally well in both identically and non-identically distributed scenarios. Finally, it is an environmentally friendly algorithm as it allows significant energy savings during the training process compared to its centralized counterpart.
Explained anomaly detection in text reviews: Can subjective scenarios be correctly evaluated?
Nov 08, 2023This paper presents a pipeline to detect and explain anomalous reviews in online platforms. The pipeline is made up of three modules and allows the detection of reviews that do not generate value for users due to either worthless or malicious composition. The classifications are accompanied by a normality score and an explanation that justifies the decision made. The pipeline's ability to solve the anomaly detection task was evaluated using different datasets created from a large Amazon database. Additionally, a study comparing three explainability techniques involving 241 participants was conducted to assess the explainability module. The study aimed to measure the impact of explanations on the respondents' ability to reproduce the classification model and their perceived usefulness. This work can be useful to automate tasks in review online platforms, such as those for electronic commerce, and offers inspiration for addressing similar problems in the field of anomaly detection in textual data. We also consider it interesting to have carried out a human evaluation of the capacity of different explainability techniques in a real and infrequent scenario such as the detection of anomalous reviews, as well as to reflect on whether it is possible to explain tasks as humanly subjective as this one.
Agent-Based Model: Simulating a Virus Expansion Based on the Acceptance of Containment Measures
Jul 28, 2023Compartmental epidemiological models categorize individuals based on their disease status, such as the SEIRD model (Susceptible-Exposed-Infected-Recovered-Dead). These models determine the parameters that influence the magnitude of an outbreak, such as contagion and recovery rates. However, they don't account for individual characteristics or population actions, which are crucial for assessing mitigation strategies like mask usage in COVID-19 or condom distribution in HIV. Additionally, studies highlight the role of citizen solidarity, interpersonal trust, and government credibility in explaining differences in contagion rates between countries. Agent-Based Modeling (ABM) offers a valuable approach to study complex systems by simulating individual components, their actions, and interactions within an environment. ABM provides a useful tool for analyzing social phenomena. In this study, we propose an ABM architecture that combines an adapted SEIRD model with a decision-making model for citizens. In this paper, we propose an ABM architecture that allows us to analyze the evolution of virus infections in a society based on two components: 1) an adaptation of the SEIRD model and 2) a decision-making model for citizens. In this way, the evolution of infections is affected, in addition to the spread of the virus itself, by individual behavior when accepting or rejecting public health measures. We illustrate the designed model by examining the progression of SARS-CoV-2 infections in A Coru\~na, Spain. This approach makes it possible to analyze the effect of the individual actions of citizens during an epidemic on the spread of the virus.
Fast Deep Autoencoder for Federated learning
Jun 13, 2022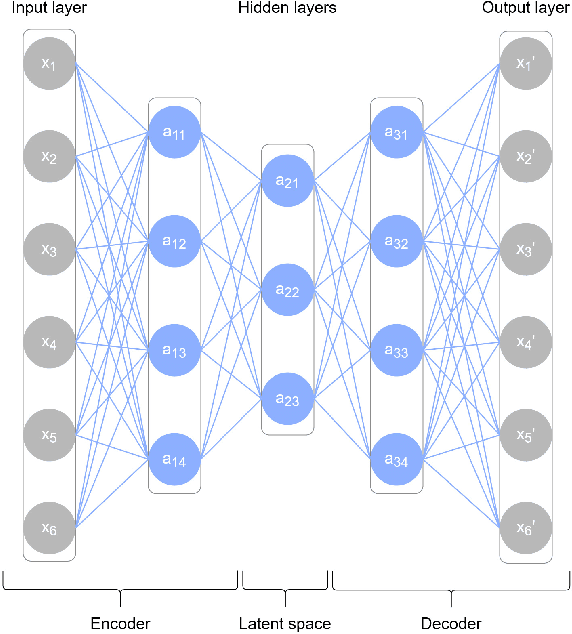
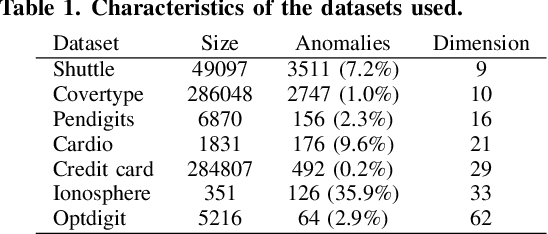
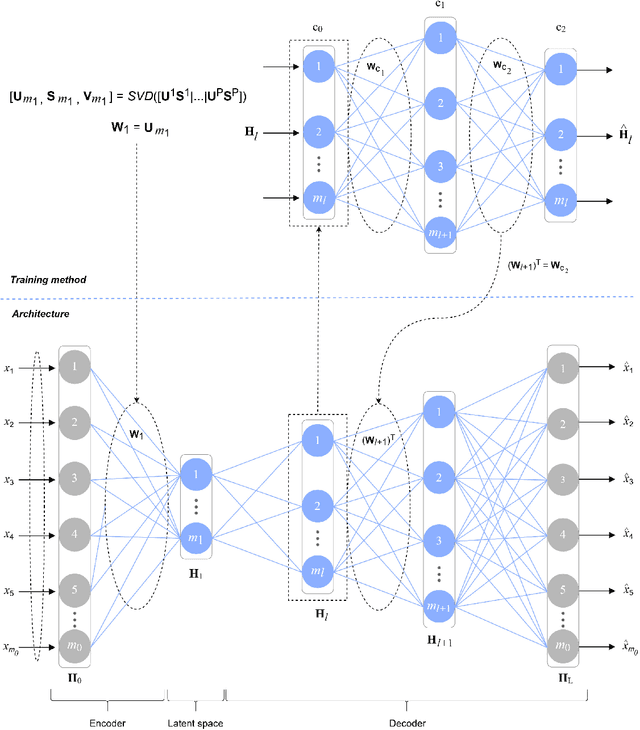

This paper presents a novel, fast and privacy preserving implementation of deep autoencoders. DAEF (Deep Autoencoder for Federated learning), unlike traditional neural networks, trains a deep autoencoder network in a non-iterative way, which drastically reduces its training time. Its training can be carried out in a distributed way (several partitions of the dataset in parallel) and incrementally (aggregation of partial models), and due to its mathematical formulation, the data that is exchanged does not endanger the privacy of the users. This makes DAEF a valid method for edge computing and federated learning scenarios. The method has been evaluated and compared to traditional (iterative) deep autoencoders using seven real anomaly detection datasets, and their performance have been shown to be similar despite DAEF's faster training.