 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Dynamic Feature Selection for Robust Latent Spaces in Vision Tasks
Oct 02, 2025Latent representations are critical for the performance and robustness of machine learning models, as they encode the essential features of data in a compact and informative manner. However, in vision tasks, these representations are often affected by noisy or irrelevant features, which can degrade the model's performance and generalization capabilities. This paper presents a novel approach for enhancing latent representations using unsupervised Dynamic Feature Selection (DFS). For each instance, the proposed method identifies and removes misleading or redundant information in images, ensuring that only the most relevant features contribute to the latent space. By leveraging an unsupervised framework, our approach avoids reliance on labeled data, making it broadly applicable across various domains and datasets. Experiments conducted on image datasets demonstrate that models equipped with unsupervised DFS achieve significant improvements in generalization performance across various tasks, including clustering and image generation, while incurring a minimal increase in the computational cost.
Beyond RMSE and MAE: Introducing EAUC to unmask hidden bias and unfairness in dyadic regression models
Jan 19, 2024Dyadic regression models, which predict real-valued outcomes for pairs of entities, are fundamental in many domains (e.g. predicting the rating of a user to a product in Recommender Systems) and promising and under exploration in many others (e.g. approximating the adequate dosage of a drug for a patient in personalized pharmacology). In this work, we demonstrate that non-uniformity in the observed value distributions of individual entities leads to severely biased predictions in state-of-the-art models, skewing predictions towards the average of observed past values for the entity and providing worse-than-random predictive power in eccentric yet equally important cases. We show that the usage of global error metrics like Root Mean Squared Error (RMSE) and Mean Absolute Error (MAE) is insufficient to capture this phenomenon, which we name eccentricity bias, and we introduce Eccentricity-Area Under the Curve (EAUC) as a new complementary metric that can quantify it in all studied models and datasets. We also prove the adequateness of EAUC by using naive de-biasing corrections to demonstrate that a lower model bias correlates with a lower EAUC and vice-versa. This work contributes a bias-aware evaluation of dyadic regression models to avoid potential unfairness and risks in critical real-world applications of such systems.
Sustainable Transparency in Recommender Systems: Bayesian Ranking of Images for Explainability
Jul 27, 2023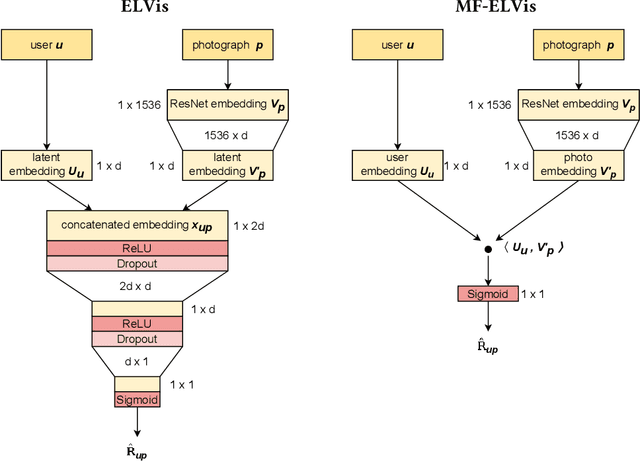
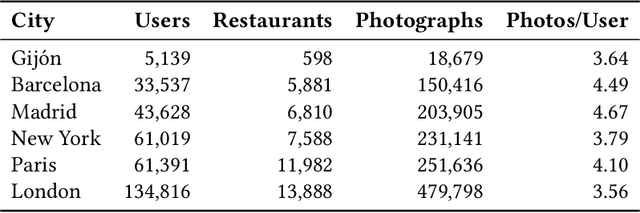
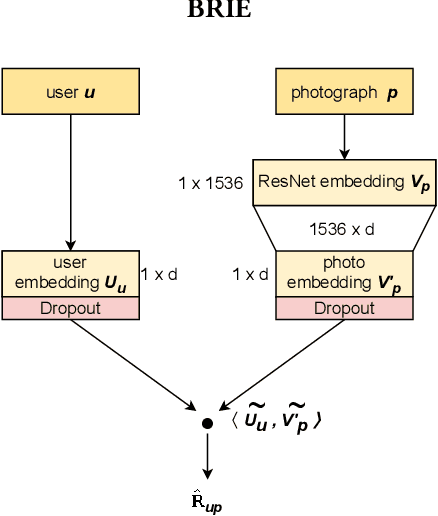
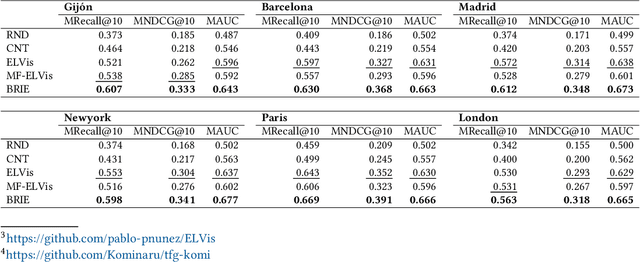
Recommender Systems have become crucial in the modern world, commonly guiding users towards relevant content or products, and having a large influence over the decisions of users and citizens. However, ensuring transparency and user trust in these systems remains a challenge; personalized explanations have emerged as a solution, offering justifications for recommendations. Among the existing approaches for generating personalized explanations, using visual content created by the users is one particularly promising option, showing a potential to maximize transparency and user trust. Existing models for explaining recommendations in this context face limitations: sustainability has been a critical concern, as they often require substantial computational resources, leading to significant carbon emissions comparable to the Recommender Systems where they would be integrated. Moreover, most models employ surrogate learning goals that do not align with the objective of ranking the most effective personalized explanations for a given recommendation, leading to a suboptimal learning process and larger model sizes. To address these limitations, we present BRIE, a novel model designed to tackle the existing challenges by adopting a more adequate learning goal based on Bayesian Pairwise Ranking, enabling it to achieve consistently superior performance than state-of-the-art models in six real-world datasets, while exhibiting remarkable efficiency, emitting up to 75% less CO${_2}$ during training and inference with a model up to 64 times smaller than previous approaches.
E2E-FS: An End-to-End Feature Selection Method for Neural Networks
Dec 14, 2020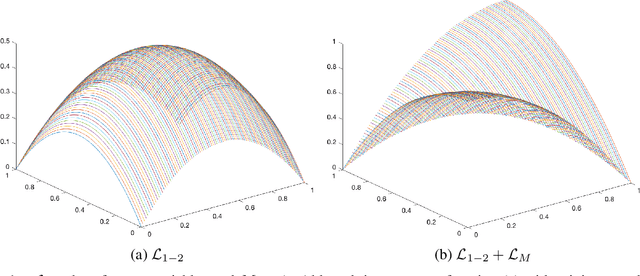
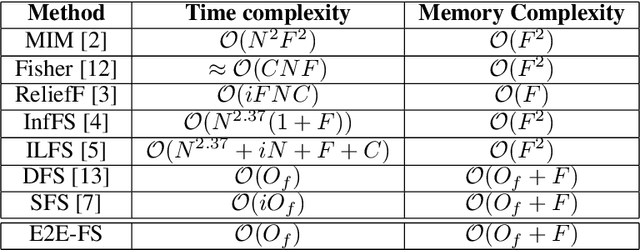
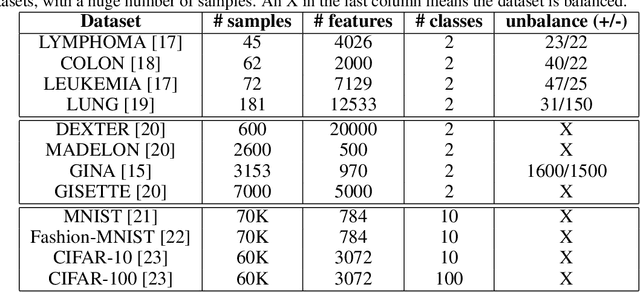
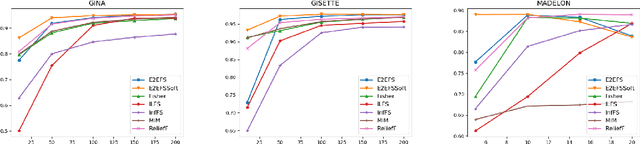
Classic embedded feature selection algorithms are often divided in two large groups: tree-based algorithms and lasso variants. Both approaches are focused in different aspects: while the tree-based algorithms provide a clear explanation about which variables are being used to trigger a certain output, lasso-like approaches sacrifice a detailed explanation in favor of increasing its accuracy. In this paper, we present a novel embedded feature selection algorithm, called End-to-End Feature Selection (E2E-FS), that aims to provide both accuracy and explainability in a clever way. Despite having non-convex regularization terms, our algorithm, similar to the lasso approach, is solved with gradient descent techniques, introducing some restrictions that force the model to specifically select a maximum number of features that are going to be used subsequently by the classifier. Although these are hard restrictions, the experimental results obtained show that this algorithm can be used with any learning model that is trained using a gradient descent algorithm.
Mining Human Mobility Data to Discover Locations and Habits
Sep 25, 2019


Many aspects of life are associated with places of human mobility patterns and nowadays we are facing an increase in the pervasiveness of mobile devices these individuals carry. Positioning technologies that serve these devices such as the cellular antenna (GSM networks), global navigation satellite systems (GPS), and more recently the WiFi positioning system (WPS) provide large amounts of spatio-temporal data in a continuous way. Therefore, detecting significant places and the frequency of movements between them is fundamental to understand human behavior. In this paper, we propose a method for discovering user habits without any a priori or external knowledge by introducing a density-based clustering for spatio-temporal data to identify meaningful places and by applying a Gaussian Mixture Model (GMM) over the set of meaningful places to identify the representations of individual habits. To evaluate the proposed method we use two real-world datasets. One dataset contains high-density GPS data and the other one contains GSM mobile phone data in a coarse representation. The results show that the proposed method is suitable for this task as many unique habits were identified. This can be used for understanding users' behavior and to draw their characterizing profiles having a panorama of the mobility patterns from the data.
A scalable saliency-based Feature selection method with instance level information
Apr 30, 2019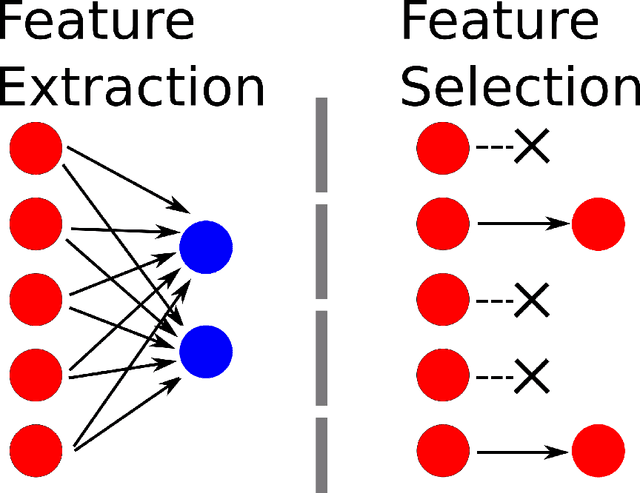

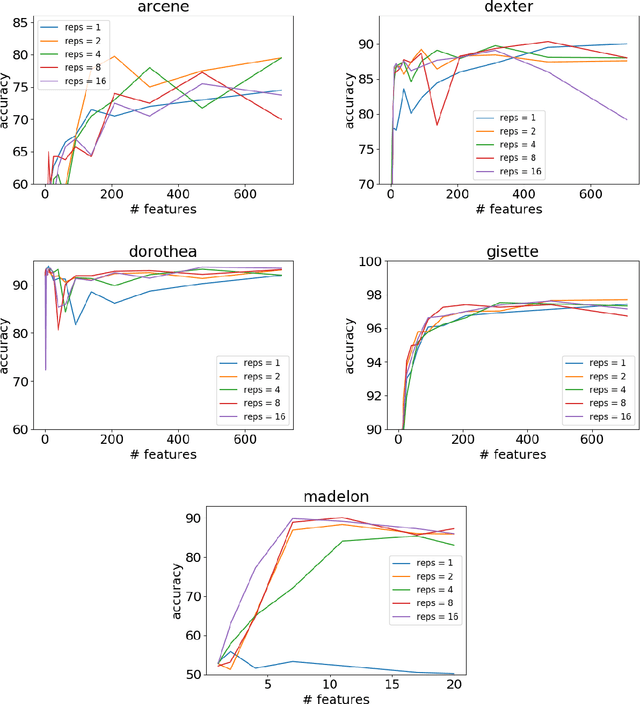
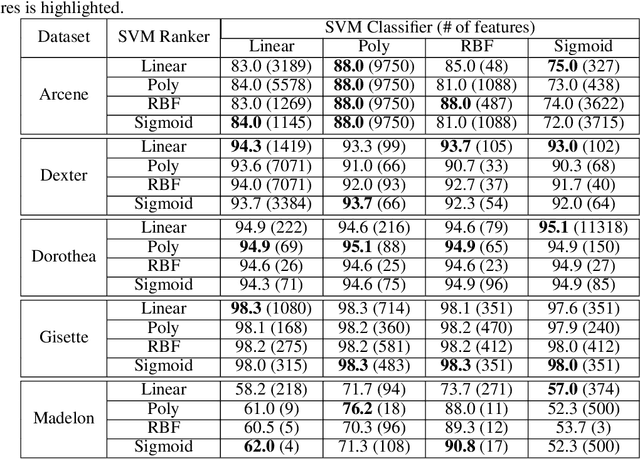
Classic feature selection techniques remove those features that are either irrelevant or redundant, achieving a subset of relevant features that help to provide a better knowledge extraction. This allows the creation of compact models that are easier to interpret. Most of these techniques work over the whole dataset, but they are unable to provide the user with successful information when only instance information is needed. In short, given any example, classic feature selection algorithms do not give any information about which the most relevant information is, regarding this sample. This work aims to overcome this handicap by developing a novel feature selection method, called Saliency-based Feature Selection (SFS), based in deep-learning saliency techniques. Our experimental results will prove that this algorithm can be successfully used not only in Neural Networks, but also under any given architecture trained by using Gradient Descent techniques.