 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplain and Conquer: Personalised Text-based Reviews to Achieve Transparency
May 03, 2022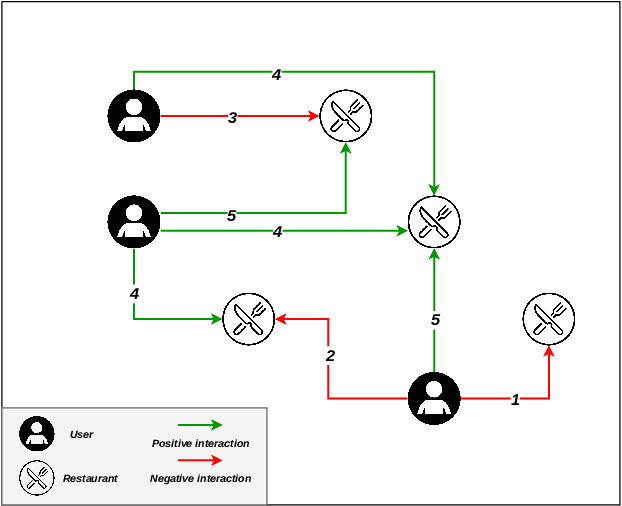
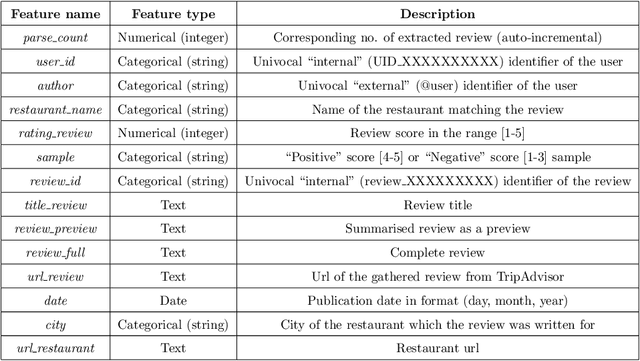
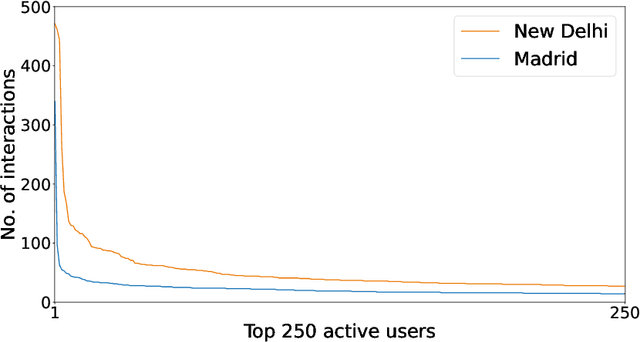
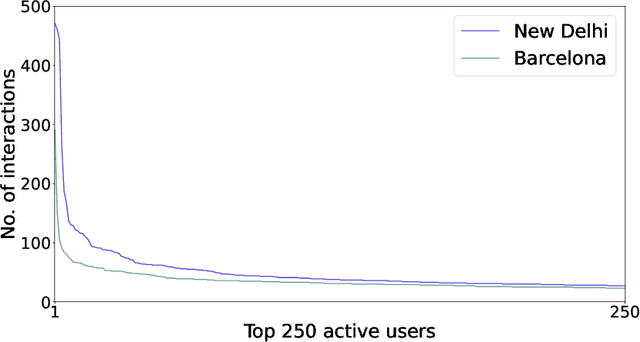
There are many contexts where dyadic data is present. Social networking is a well-known example, where transparency has grown on importance. In these contexts, pairs of items are linked building a network where interactions play a crucial role. Explaining why these relationships are established is core to address transparency. These explanations are often presented using text, thanks to the spread of the natural language understanding tasks. We have focused on the TripAdvisor platform, considering the applicability to other dyadic data contexts. The items are a subset of users and restaurants and the interactions the reviews posted by these users. Our aim is to represent and explain pairs (user, restaurant) established by agents (e.g., a recommender system or a paid promotion mechanism), so that personalisation is taken into account. We propose the PTER (Personalised TExt-based Reviews) model. We predict, from the available reviews for a given restaurant, those that fit to the specific user interactions. PTER leverages the BERT (Bidirectional Encoders Representations from Transformers) language model. We customised a deep neural network following the feature-based approach. The performance metrics show the validity of our labelling proposal. We defined an evaluation framework based on a clustering process to assess our personalised representation. PTER clearly outperforms the proposed adversary in 5 of the 6 datasets, with a minimum ratio improvement of 4%.
E2E-FS: An End-to-End Feature Selection Method for Neural Networks
Dec 14, 2020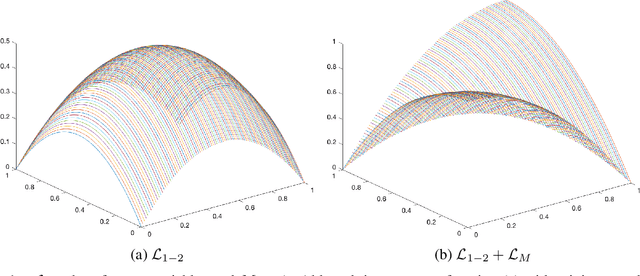
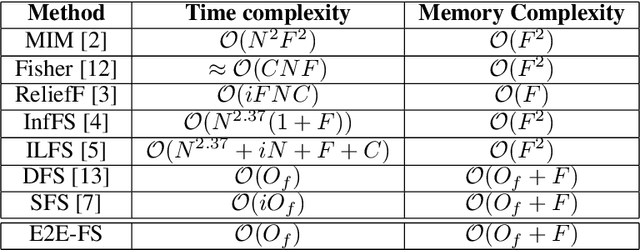
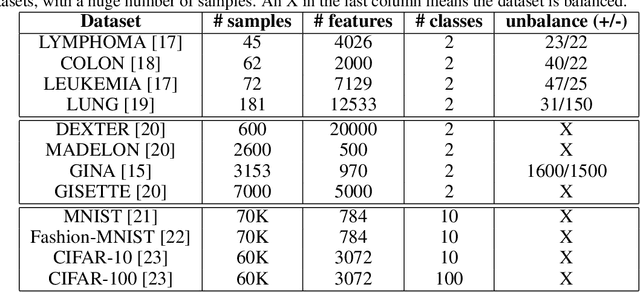
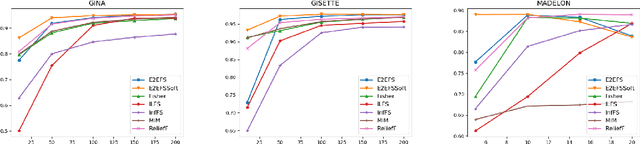
Classic embedded feature selection algorithms are often divided in two large groups: tree-based algorithms and lasso variants. Both approaches are focused in different aspects: while the tree-based algorithms provide a clear explanation about which variables are being used to trigger a certain output, lasso-like approaches sacrifice a detailed explanation in favor of increasing its accuracy. In this paper, we present a novel embedded feature selection algorithm, called End-to-End Feature Selection (E2E-FS), that aims to provide both accuracy and explainability in a clever way. Despite having non-convex regularization terms, our algorithm, similar to the lasso approach, is solved with gradient descent techniques, introducing some restrictions that force the model to specifically select a maximum number of features that are going to be used subsequently by the classifier. Although these are hard restrictions, the experimental results obtained show that this algorithm can be used with any learning model that is trained using a gradient descent algorithm.
A scalable saliency-based Feature selection method with instance level information
Apr 30, 2019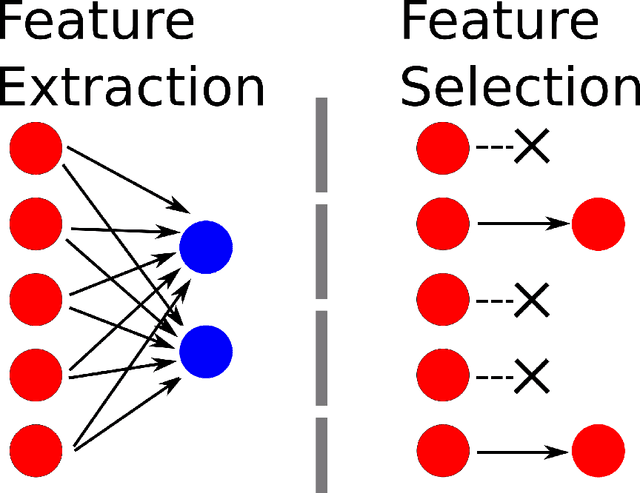

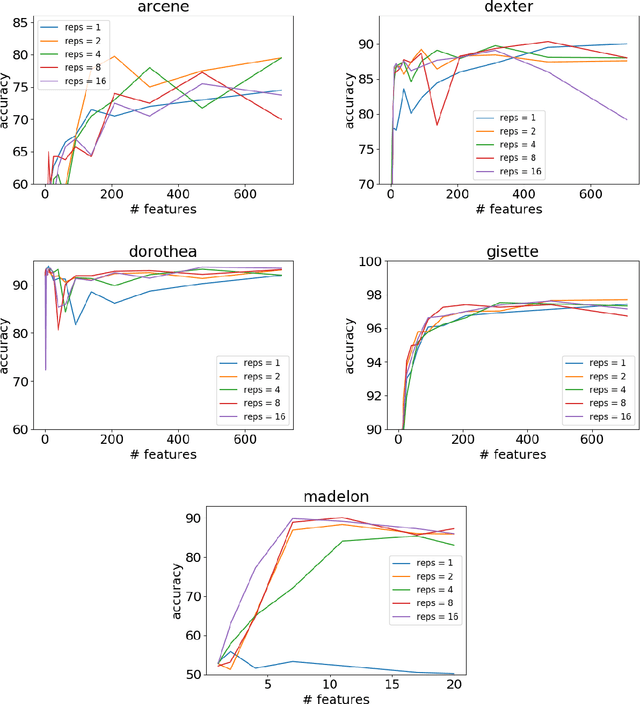
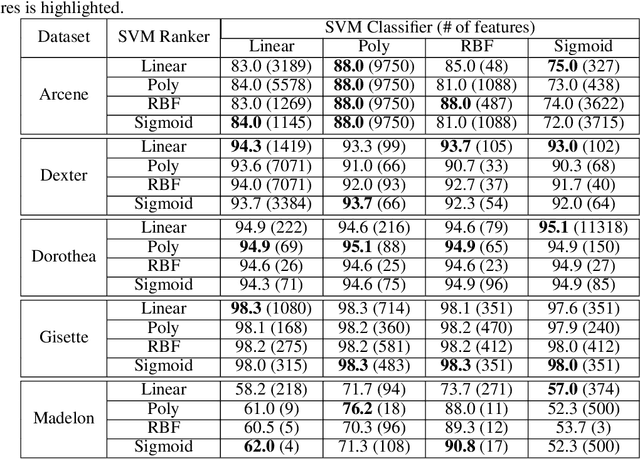
Classic feature selection techniques remove those features that are either irrelevant or redundant, achieving a subset of relevant features that help to provide a better knowledge extraction. This allows the creation of compact models that are easier to interpret. Most of these techniques work over the whole dataset, but they are unable to provide the user with successful information when only instance information is needed. In short, given any example, classic feature selection algorithms do not give any information about which the most relevant information is, regarding this sample. This work aims to overcome this handicap by developing a novel feature selection method, called Saliency-based Feature Selection (SFS), based in deep-learning saliency techniques. Our experimental results will prove that this algorithm can be successfully used not only in Neural Networks, but also under any given architecture trained by using Gradient Descent techniques.
An Information Theoretic Feature Selection Framework for Big Data under Apache Spark
Oct 19, 2016
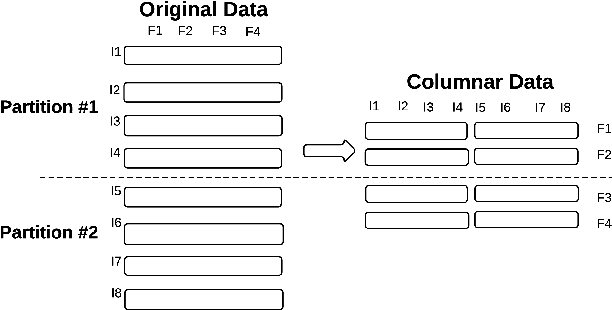
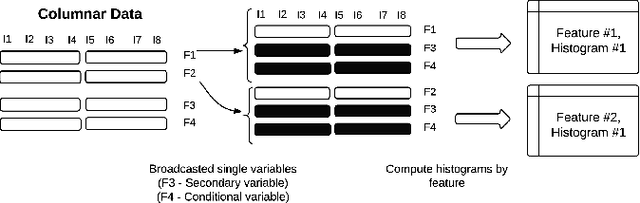

With the advent of extremely high dimensional datasets, dimensionality reduction techniques are becoming mandatory. Among many techniques, feature selection has been growing in interest as an important tool to identify relevant features on huge datasets --both in number of instances and features--. The purpose of this work is to demonstrate that standard feature selection methods can be parallelized in Big Data platforms like Apache Spark, boosting both performance and accuracy. We thus propose a distributed implementation of a generic feature selection framework which includes a wide group of well-known Information Theoretic methods. Experimental results on a wide set of real-world datasets show that our distributed framework is capable of dealing with ultra-high dimensional datasets as well as those with a huge number of samples in a short period of time, outperforming the sequential version in all the cases studied.