 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplanation Method for Anomaly Detection on Mixed Numerical and Categorical Spaces
Sep 09, 2022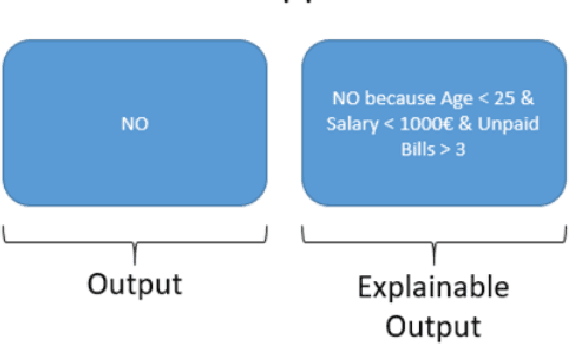
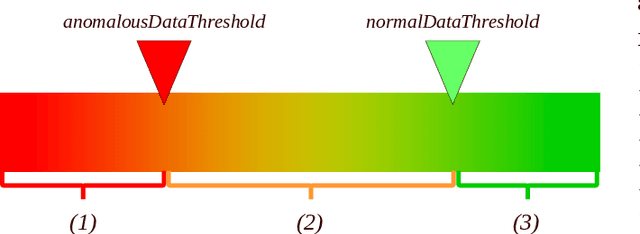

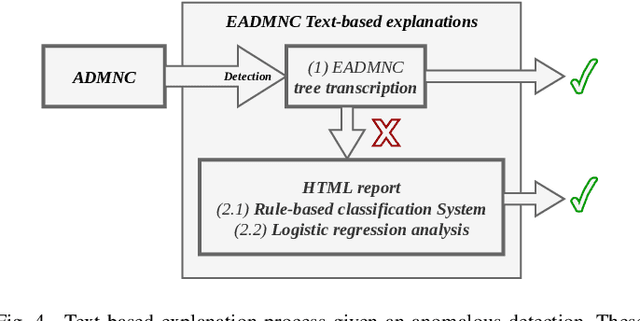
Most proposals in the anomaly detection field focus exclusively on the detection stage, specially in the recent deep learning approaches. While providing highly accurate predictions, these models often lack transparency, acting as "black boxes". This criticism has grown to the point that explanation is now considered very relevant in terms of acceptability and reliability. In this paper, we addressed this issue by inspecting the ADMNC (Anomaly Detection on Mixed Numerical and Categorical Spaces) model, an existing very accurate although opaque anomaly detector capable to operate with both numerical and categorical inputs. This work presents the extension EADMNC (Explainable Anomaly Detection on Mixed Numerical and Categorical spaces), which adds explainability to the predictions obtained with the original model. We preserved the scalability of the original method thanks to the Apache Spark framework. EADMNC leverages the formulation of the previous ADMNC model to offer pre hoc and post hoc explainability, while maintaining the accuracy of the original architecture. We present a pre hoc model that globally explains the outputs by segmenting input data into homogeneous groups, described with only a few variables. We designed a graphical representation based on regression trees, which supervisors can inspect to understand the differences between normal and anomalous data. Our post hoc explanations consist of a text-based template method that locally provides textual arguments supporting each detection. We report experimental results on extensive real-world data, particularly in the domain of network intrusion detection. The usefulness of the explanations is assessed by theory analysis using expert knowledge in the network intrusion domain.
Explain and Conquer: Personalised Text-based Reviews to Achieve Transparency
May 03, 2022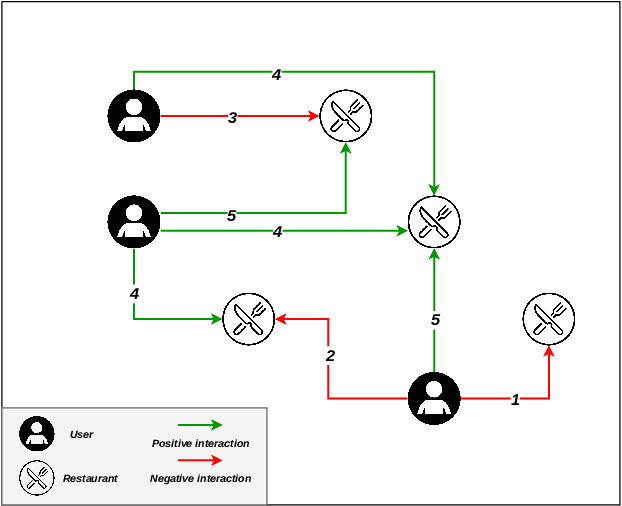
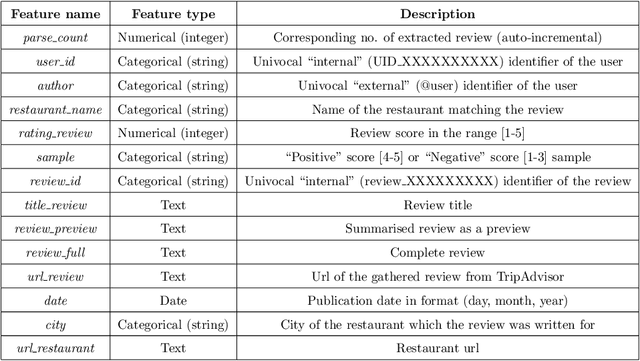
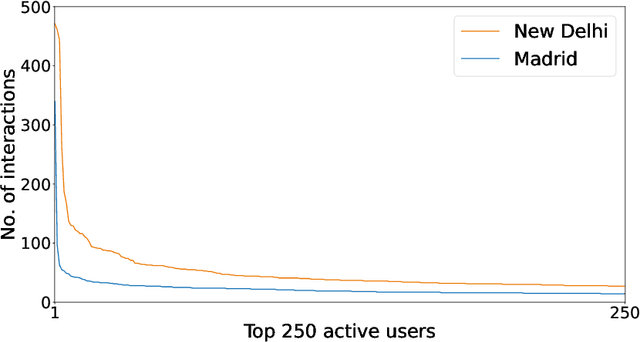
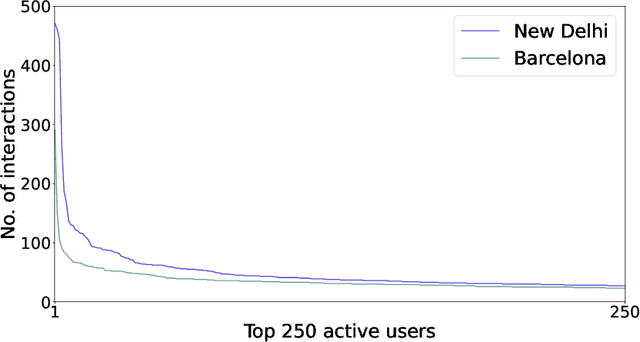
There are many contexts where dyadic data is present. Social networking is a well-known example, where transparency has grown on importance. In these contexts, pairs of items are linked building a network where interactions play a crucial role. Explaining why these relationships are established is core to address transparency. These explanations are often presented using text, thanks to the spread of the natural language understanding tasks. We have focused on the TripAdvisor platform, considering the applicability to other dyadic data contexts. The items are a subset of users and restaurants and the interactions the reviews posted by these users. Our aim is to represent and explain pairs (user, restaurant) established by agents (e.g., a recommender system or a paid promotion mechanism), so that personalisation is taken into account. We propose the PTER (Personalised TExt-based Reviews) model. We predict, from the available reviews for a given restaurant, those that fit to the specific user interactions. PTER leverages the BERT (Bidirectional Encoders Representations from Transformers) language model. We customised a deep neural network following the feature-based approach. The performance metrics show the validity of our labelling proposal. We defined an evaluation framework based on a clustering process to assess our personalised representation. PTER clearly outperforms the proposed adversary in 5 of the 6 datasets, with a minimum ratio improvement of 4%.