 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplanation Method for Anomaly Detection on Mixed Numerical and Categorical Spaces
Sep 09, 2022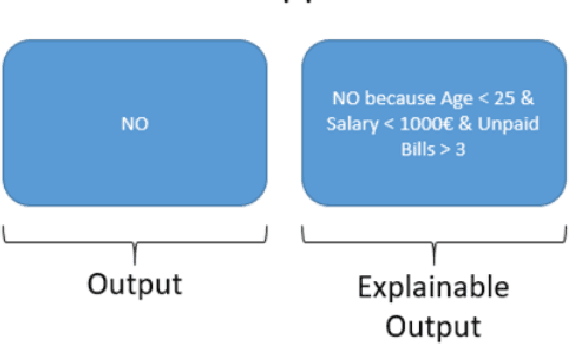
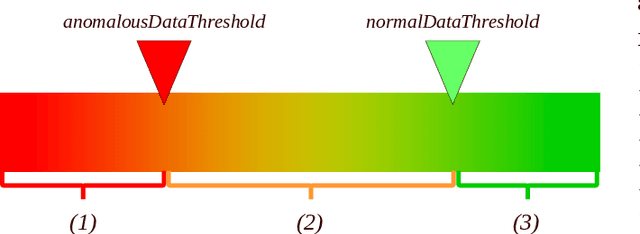

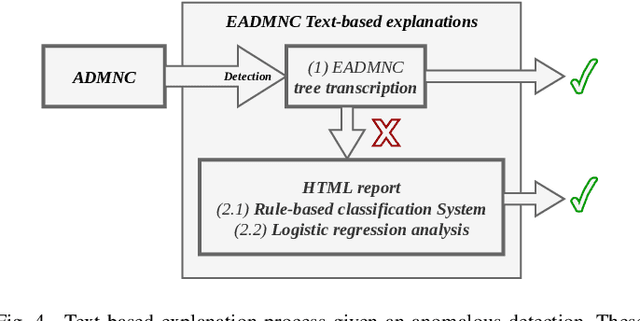
Most proposals in the anomaly detection field focus exclusively on the detection stage, specially in the recent deep learning approaches. While providing highly accurate predictions, these models often lack transparency, acting as "black boxes". This criticism has grown to the point that explanation is now considered very relevant in terms of acceptability and reliability. In this paper, we addressed this issue by inspecting the ADMNC (Anomaly Detection on Mixed Numerical and Categorical Spaces) model, an existing very accurate although opaque anomaly detector capable to operate with both numerical and categorical inputs. This work presents the extension EADMNC (Explainable Anomaly Detection on Mixed Numerical and Categorical spaces), which adds explainability to the predictions obtained with the original model. We preserved the scalability of the original method thanks to the Apache Spark framework. EADMNC leverages the formulation of the previous ADMNC model to offer pre hoc and post hoc explainability, while maintaining the accuracy of the original architecture. We present a pre hoc model that globally explains the outputs by segmenting input data into homogeneous groups, described with only a few variables. We designed a graphical representation based on regression trees, which supervisors can inspect to understand the differences between normal and anomalous data. Our post hoc explanations consist of a text-based template method that locally provides textual arguments supporting each detection. We report experimental results on extensive real-world data, particularly in the domain of network intrusion detection. The usefulness of the explanations is assessed by theory analysis using expert knowledge in the network intrusion domain.
Detecting fraudulent activity in a cloud using privacy-friendly data aggregates
Nov 25, 2014
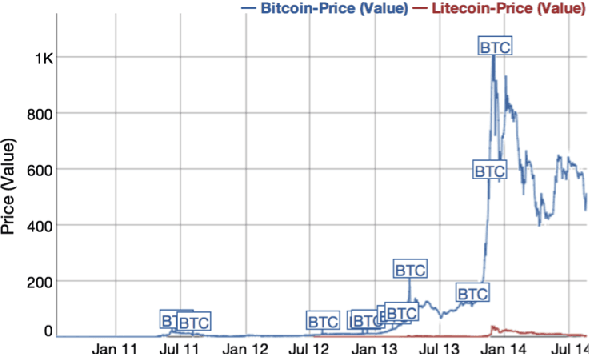
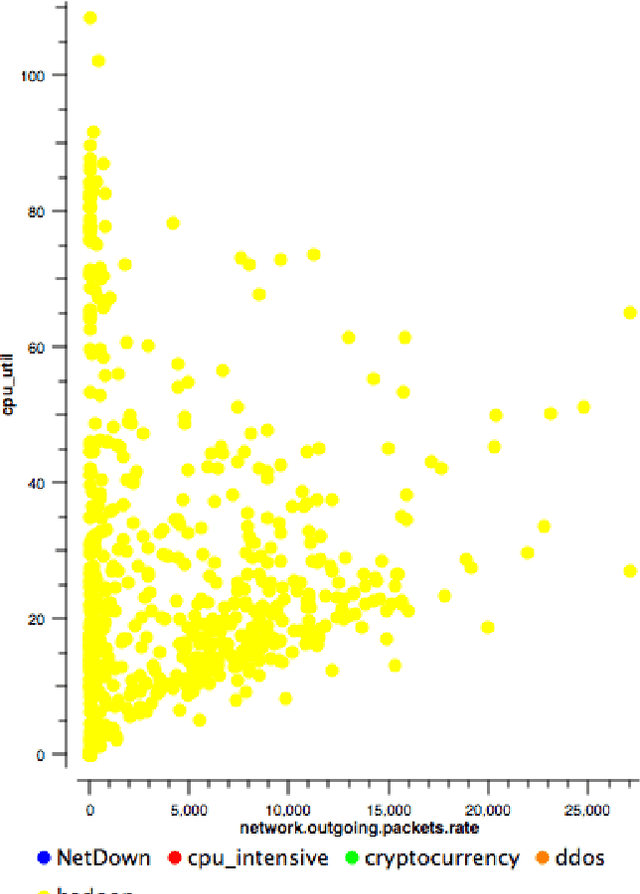
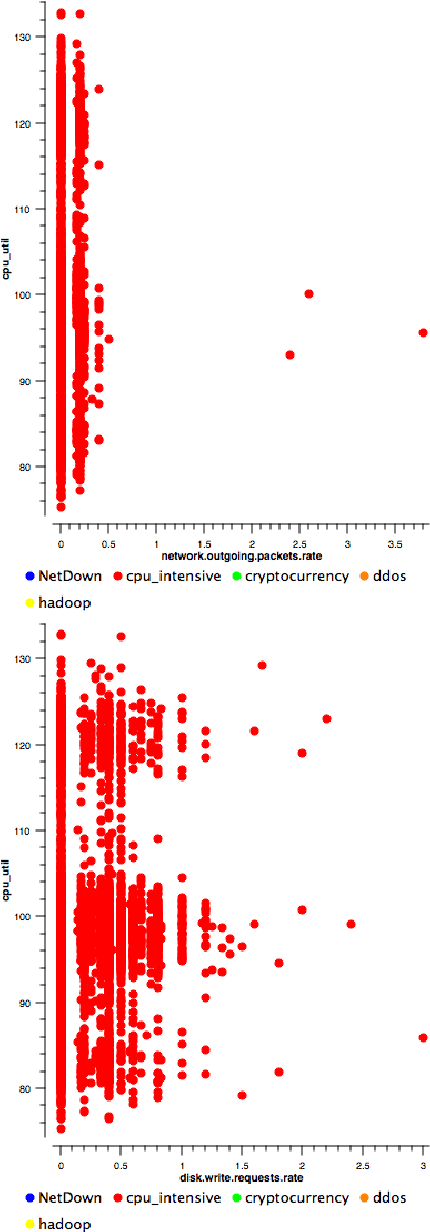
More users and companies make use of cloud services every day. They all expect a perfect performance and any issue to remain transparent to them. This last statement is very challenging to perform. A user's activities in our cloud can affect the overall performance of our servers, having an impact on other resources. We can consider these kind of activities as fraudulent. They can be either illegal activities, such as launching a DDoS attack or just activities which are undesired by the cloud provider, such as Bitcoin mining, which uses substantial power, reduces the life of the hardware and can possibly slow down other user's activities. This article discusses a method to detect such activities by using non-intrusive, privacy-friendly data: billing data. We use OpenStack as an example with data provided by Telemetry, the component in charge of measuring resource usage for billing purposes. Results will be shown proving the efficiency of this method and ways to improve it will be provided as well as its advantages and disadvantages.