 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBELIEF: A distance-based redundancy-proof feature selection method for Big Data
Apr 16, 2018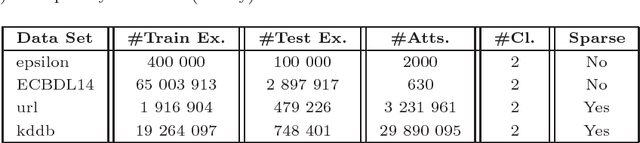
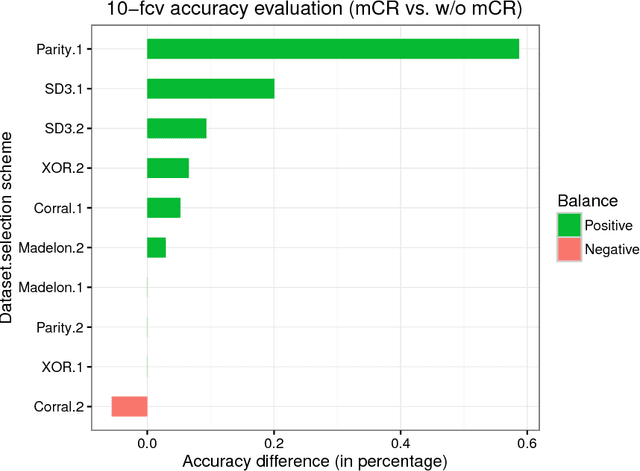

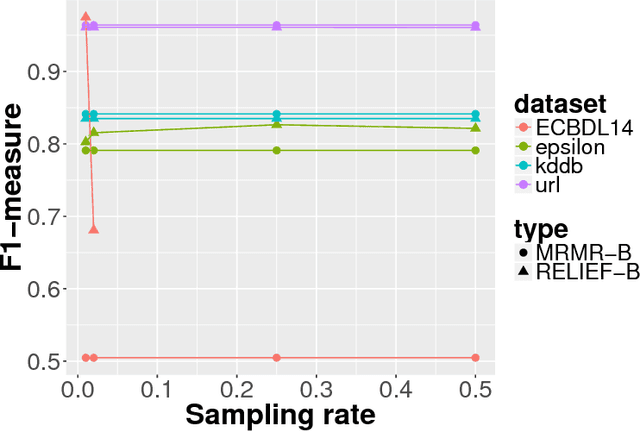
With the advent of Big Data era, data reduction methods are highly demanded given its ability to simplify huge data, and ease complex learning processes. Concretely, algorithms that are able to filter relevant dimensions from a set of millions are of huge importance. Although effective, these techniques suffer from the "scalability" curse as well. In this work, we propose a distributed feature weighting algorithm, which is able to rank millions of features in parallel using large samples. This method, inspired by the well-known RELIEF algorithm, introduces a novel redundancy elimination measure that provides similar schemes to those based on entropy at a much lower cost. It also allows smooth scale up when more instances are demanded in feature estimations. Empirical tests performed on our method show its estimation ability in manifold huge sets --both in number of features and instances--, as well as its simplified runtime cost (specially, at the redundancy detection step).
An Information Theoretic Feature Selection Framework for Big Data under Apache Spark
Oct 19, 2016
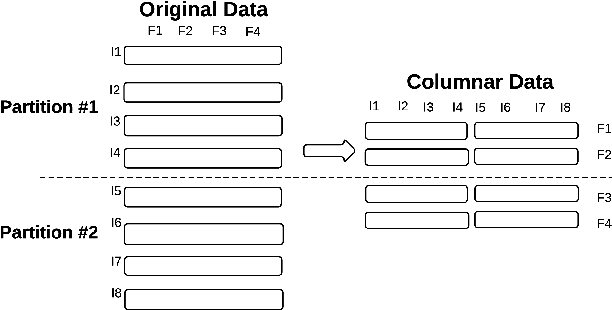
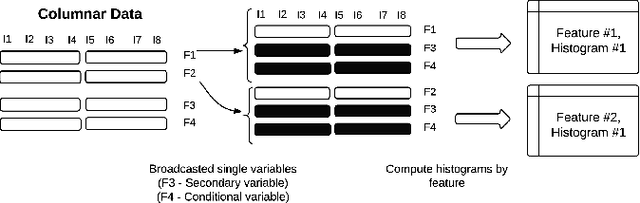

With the advent of extremely high dimensional datasets, dimensionality reduction techniques are becoming mandatory. Among many techniques, feature selection has been growing in interest as an important tool to identify relevant features on huge datasets --both in number of instances and features--. The purpose of this work is to demonstrate that standard feature selection methods can be parallelized in Big Data platforms like Apache Spark, boosting both performance and accuracy. We thus propose a distributed implementation of a generic feature selection framework which includes a wide group of well-known Information Theoretic methods. Experimental results on a wide set of real-world datasets show that our distributed framework is capable of dealing with ultra-high dimensional datasets as well as those with a huge number of samples in a short period of time, outperforming the sequential version in all the cases studied.