 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeABCD: Trust enhanced Attention based Convolutional Autoencoder for Risk Assessment
Apr 24, 2024Anomaly detection in industrial systems is crucial for preventing equipment failures, ensuring risk identification, and maintaining overall system efficiency. Traditional monitoring methods often rely on fixed thresholds and empirical rules, which may not be sensitive enough to detect subtle changes in system health and predict impending failures. To address this limitation, this paper proposes, a novel Attention-based convolutional autoencoder (ABCD) for risk detection and map the risk value derive to the maintenance planning. ABCD learns the normal behavior of conductivity from historical data of a real-world industrial cooling system and reconstructs the input data, identifying anomalies that deviate from the expected patterns. The framework also employs calibration techniques to ensure the reliability of its predictions. Evaluation results demonstrate that with the attention mechanism in ABCD a 57.4% increase in performance and a reduction of false alarms by 9.37% is seen compared to without attention. The approach can effectively detect risks, the risk priority rank mapped to maintenance, providing valuable insights for cooling system designers and service personnel. Calibration error of 0.03% indicates that the model is well-calibrated and enhances model's trustworthiness, enabling informed decisions about maintenance strategies
S2DEVFMAP: Self-Supervised Learning Framework with Dual Ensemble Voting Fusion for Maximizing Anomaly Prediction in Timeseries
Apr 24, 2024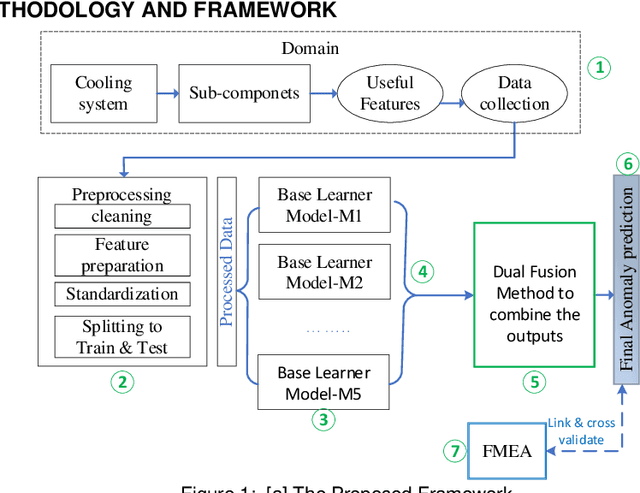
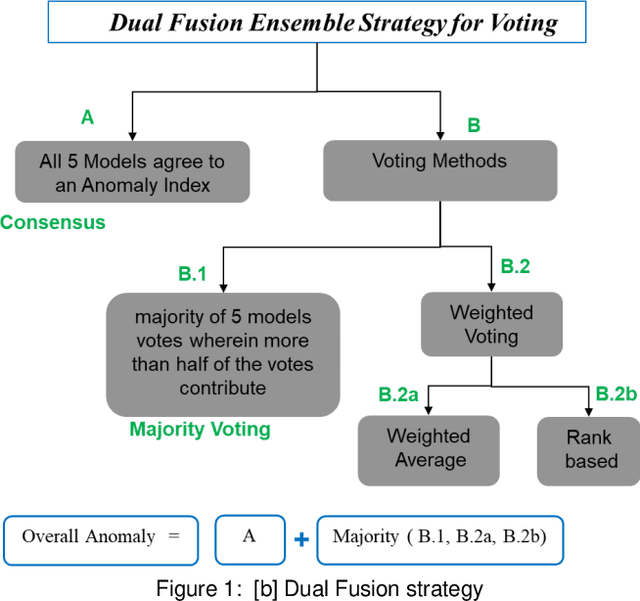

Anomaly detection plays a crucial role in industrial settings, particularly in maintaining the reliability and optimal performance of cooling systems. Traditional anomaly detection methods often face challenges in handling diverse data characteristics and variations in noise levels, resulting in limited effectiveness. And yet traditional anomaly detection often relies on application of single models. This work proposes a novel, robust approach using five heterogeneous independent models combined with a dual ensemble fusion of voting techniques. Diverse models capture various system behaviors, while the fusion strategy maximizes detection effectiveness and minimizes false alarms. Each base autoencoder model learns a unique representation of the data, leveraging their complementary strengths to improve anomaly detection performance. To increase the effectiveness and reliability of final anomaly prediction, dual ensemble technique is applied. This approach outperforms in maximizing the coverage of identifying anomalies. Experimental results on a real-world dataset of industrial cooling system data demonstrate the effectiveness of the proposed approach. This approach can be extended to other industrial applications where anomaly detection is critical for ensuring system reliability and preventing potential malfunctions.
Smart Data based Ensemble for Imbalanced Big Data Classification
Jan 16, 2020

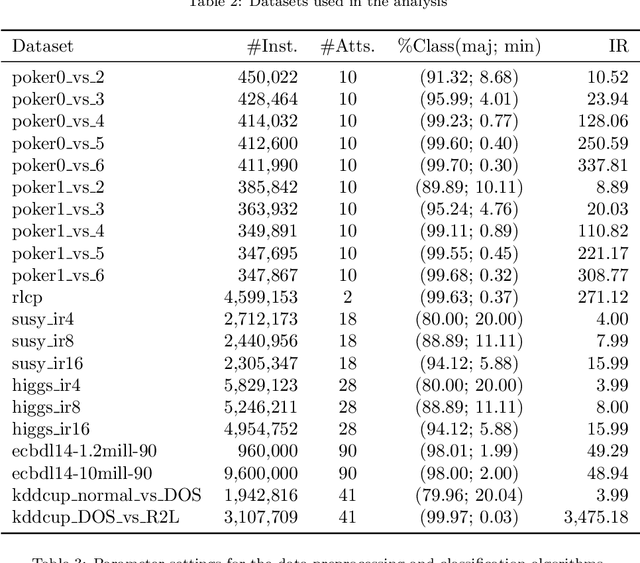
Big Data scenarios pose a new challenge to traditional data mining algorithms, since they are not prepared to work with such amount of data. Smart Data refers to data of enough quality to improve the outcome from a data mining algorithm. Existing data mining algorithms unability to handle Big Datasets prevents the transition from Big to Smart Data. Automation in data acquisition that characterizes Big Data also brings some problems, such as differences in data size per class. This will lead classifiers to lean towards the most represented classes. This problem is known as imbalanced data distribution, where one class is underrepresented in the dataset. Ensembles of classifiers are machine learning methods that improve the performance of a single base classifier by the combination of several of them. Ensembles are not exempt from the imbalanced classification problem. To deal with this issue, the ensemble method have to be designed specifically. In this paper, a data preprocessing ensemble for imbalanced Big Data classification is presented, with focus on two-class problems. Experiments carried out in 21 Big Datasets have proved that our ensemble classifier outperforms classic machine learning models with an added data balancing method, such as Random Forests.
Finding the most similar textual documents using Case-Based Reasoning
Nov 01, 2019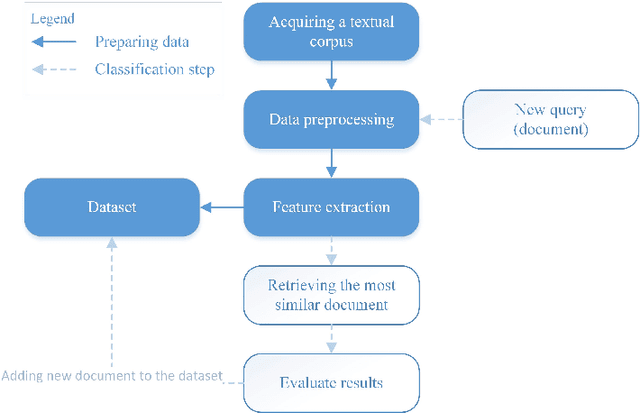
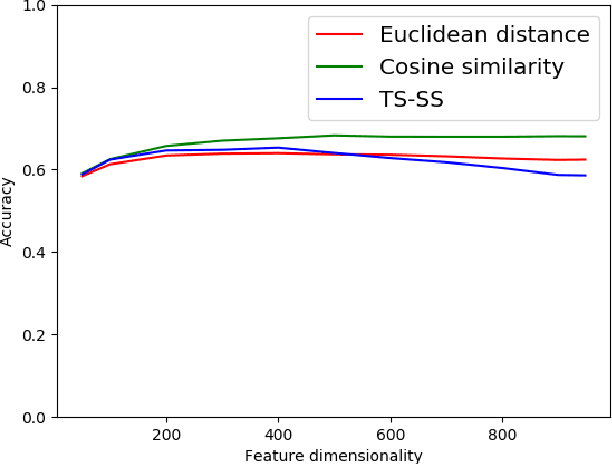
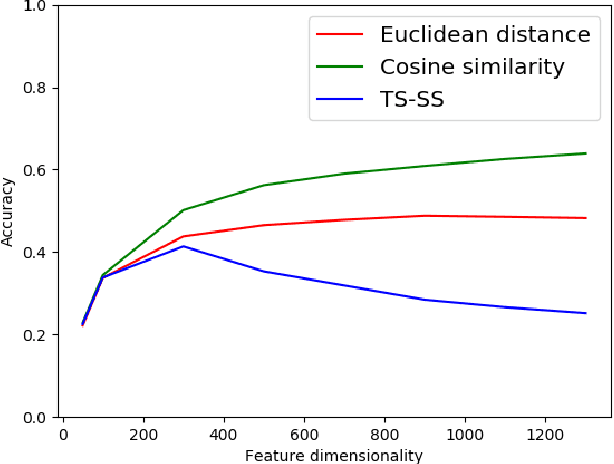
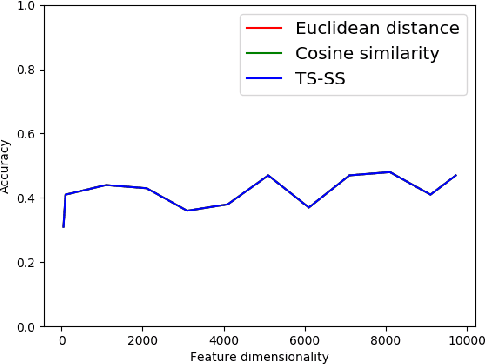
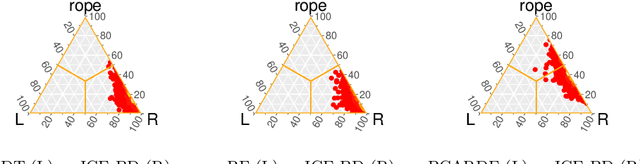
In recent years, huge amounts of unstructured textual data on the Internet are a big difficulty for AI algorithms to provide the best recommendations for users and their search queries. Since the Internet became widespread, a lot of research has been done in the field of Natural Language Processing (NLP) and machine learning. Almost every solution transforms documents into Vector Space Models (VSM) in order to apply AI algorithms over them. One such approach is based on Case-Based Reasoning (CBR). Therefore, the most important part of those systems is to compute the similarity between numerical data points. In 2016, the new similarity TS-SS metric is proposed, which showed state-of-the-art results in the field of textual mining for unsupervised learning. However, no one before has investigated its performances for supervised learning (classification task). In this work, we devised a CBR system capable of finding the most similar documents for a given query aiming to investigate performances of the new state-of-the-art metric, TS-SS, in addition to the two other geometrical similarity measures --- Euclidean distance and Cosine similarity --- that showed the best predictive results over several benchmark corpora. The results show surprising inappropriateness of TS-SS measure for high dimensional features.
BELIEF: A distance-based redundancy-proof feature selection method for Big Data
Apr 16, 2018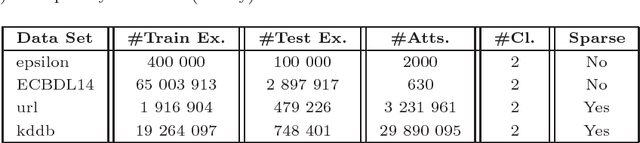

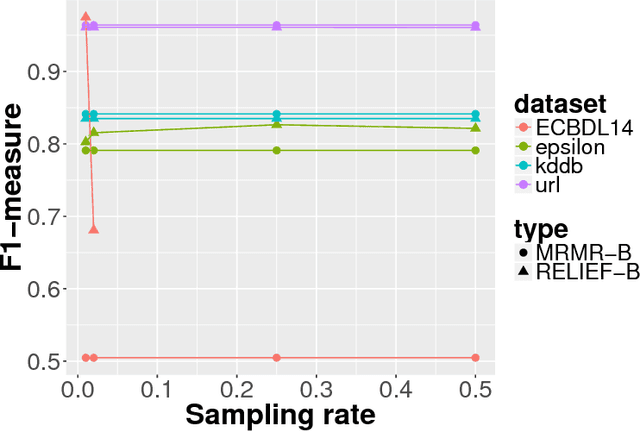
With the advent of Big Data era, data reduction methods are highly demanded given its ability to simplify huge data, and ease complex learning processes. Concretely, algorithms that are able to filter relevant dimensions from a set of millions are of huge importance. Although effective, these techniques suffer from the "scalability" curse as well. In this work, we propose a distributed feature weighting algorithm, which is able to rank millions of features in parallel using large samples. This method, inspired by the well-known RELIEF algorithm, introduces a novel redundancy elimination measure that provides similar schemes to those based on entropy at a much lower cost. It also allows smooth scale up when more instances are demanded in feature estimations. Empirical tests performed on our method show its estimation ability in manifold huge sets --both in number of features and instances--, as well as its simplified runtime cost (specially, at the redundancy detection step).