 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSmart Data based Ensemble for Imbalanced Big Data Classification
Jan 16, 2020

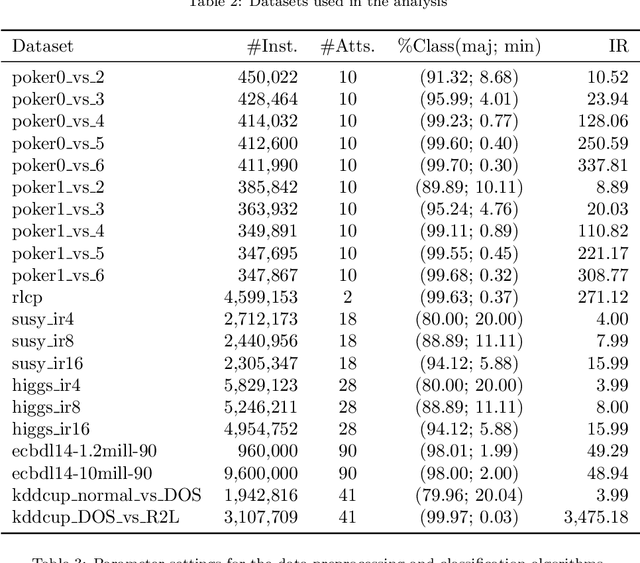
Big Data scenarios pose a new challenge to traditional data mining algorithms, since they are not prepared to work with such amount of data. Smart Data refers to data of enough quality to improve the outcome from a data mining algorithm. Existing data mining algorithms unability to handle Big Datasets prevents the transition from Big to Smart Data. Automation in data acquisition that characterizes Big Data also brings some problems, such as differences in data size per class. This will lead classifiers to lean towards the most represented classes. This problem is known as imbalanced data distribution, where one class is underrepresented in the dataset. Ensembles of classifiers are machine learning methods that improve the performance of a single base classifier by the combination of several of them. Ensembles are not exempt from the imbalanced classification problem. To deal with this issue, the ensemble method have to be designed specifically. In this paper, a data preprocessing ensemble for imbalanced Big Data classification is presented, with focus on two-class problems. Experiments carried out in 21 Big Datasets have proved that our ensemble classifier outperforms classic machine learning models with an added data balancing method, such as Random Forests.
DPASF: A Flink Library for Streaming Data preprocessing
Oct 14, 2018
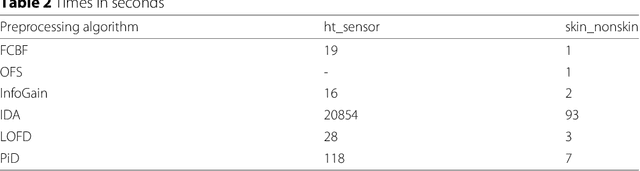
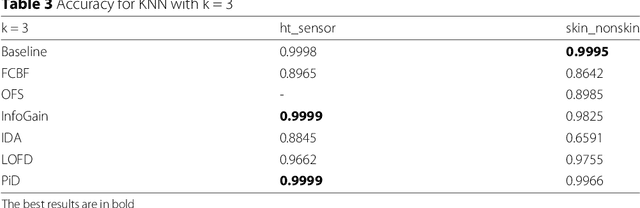
Data preprocessing techniques are devoted to correct or alleviate errors in data. Discretization and feature selection are two of the most extended data preprocessing techniques. Although we can find many proposals for static Big Data preprocessing, there is little research devoted to the continuous Big Data problem. Apache Flink is a recent and novel Big Data framework, following the MapReduce paradigm, focused on distributed stream and batch data processing. In this paper we propose a data stream library for Big Data preprocessing, named DPASF, under Apache Flink. We have implemented six of the most popular data preprocessing algorithms, three for discretization and the rest for feature selection. The algorithms have been tested using two Big Data datasets. Experimental results show that preprocessing can not only reduce the size of the data, but to maintain or even improve the original accuracy in a short time. DPASF contains useful algorithms when dealing with Big Data data streams. The preprocessing algorithms included in the library are able to tackle Big Datasets efficiently and to correct imperfections in the data.
Enabling Smart Data: Noise filtering in Big Data classification
Jul 28, 2017
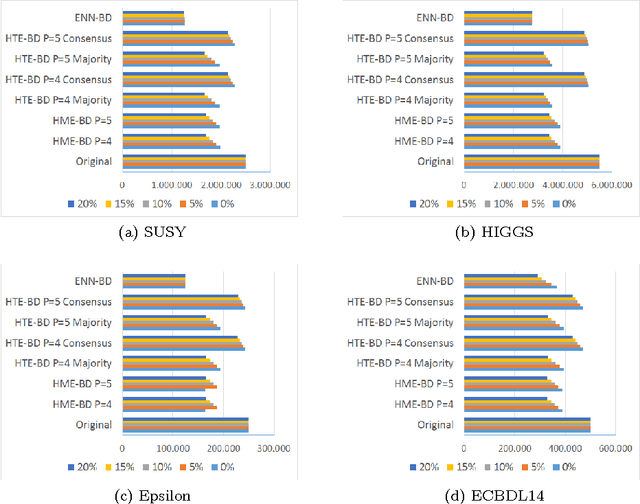
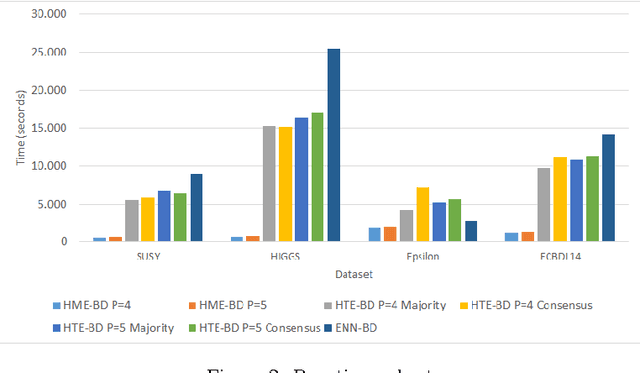

In any knowledge discovery process the value of extracted knowledge is directly related to the quality of the data used. Big Data problems, generated by massive growth in the scale of data observed in recent years, also follow the same dictate. A common problem affecting data quality is the presence of noise, particularly in classification problems, where label noise refers to the incorrect labeling of training instances, and is known to be a very disruptive feature of data. However, in this Big Data era, the massive growth in the scale of the data poses a challenge to traditional proposals created to tackle noise, as they have difficulties coping with such a large amount of data. New algorithms need to be proposed to treat the noise in Big Data problems, providing high quality and clean data, also known as Smart Data. In this paper, two Big Data preprocessing approaches to remove noisy examples are proposed: an homogeneous ensemble and an heterogeneous ensemble filter, with special emphasis in their scalability and performance traits. The obtained results show that these proposals enable the practitioner to efficiently obtain a Smart Dataset from any Big Data classification problem.