 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Parameter Mining and Freezing for Continual Object Detection
Feb 20, 2024Continual Object Detection is essential for enabling intelligent agents to interact proactively with humans in real-world settings. While parameter-isolation strategies have been extensively explored in the context of continual learning for classification, they have yet to be fully harnessed for incremental object detection scenarios. Drawing inspiration from prior research that focused on mining individual neuron responses and integrating insights from recent developments in neural pruning, we proposed efficient ways to identify which layers are the most important for a network to maintain the performance of a detector across sequential updates. The presented findings highlight the substantial advantages of layer-level parameter isolation in facilitating incremental learning within object detection models, offering promising avenues for future research and application in real-world scenarios.
Continual Object Detection: A review of definitions, strategies, and challenges
May 30, 2022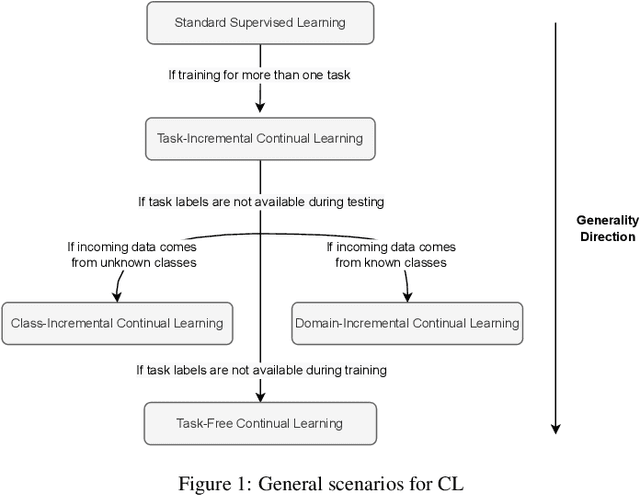


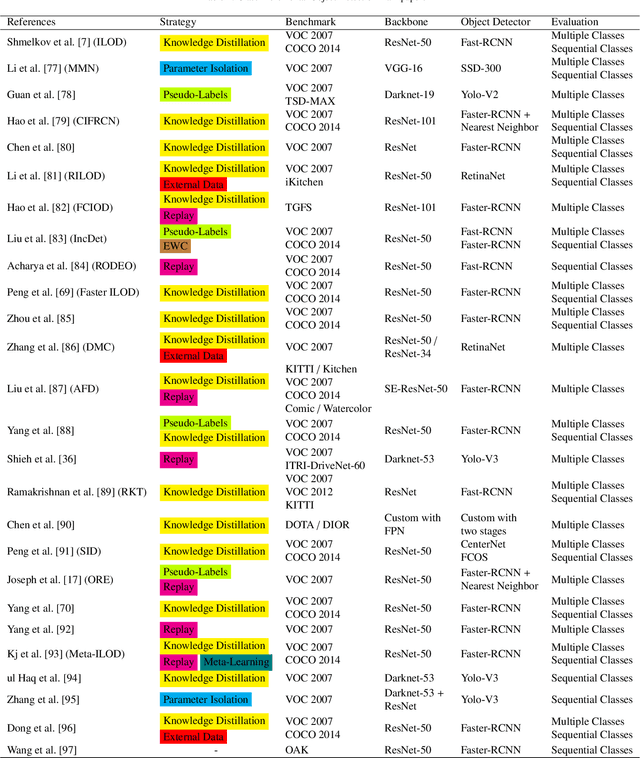
The field of Continual Learning investigates the ability to learn consecutive tasks without losing performance on those previously learned. Its focus has been mainly on incremental classification tasks. We believe that research in continual object detection deserves even more attention due to its vast range of applications in robotics and autonomous vehicles. This scenario is more complex than conventional classification given the occurrence of instances of classes that are unknown at the time, but can appear in subsequent tasks as a new class to be learned, resulting in missing annotations and conflicts with the background label. In this review, we analyze the current strategies proposed to tackle the problem of class-incremental object detection. Our main contributions are: (1) a short and systematic review of the methods that propose solutions to traditional incremental object detection scenarios; (2) A comprehensive evaluation of the existing approaches using a new metric to quantify the stability and plasticity of each technique in a standard way; (3) an overview of the current trends within continual object detection and a discussion of possible future research directions.
Analysis and evaluation of Deep Learning based Super-Resolution algorithms to improve performance in Low-Resolution Face Recognition
Jan 19, 2021


Surveillance scenarios are prone to several problems since they usually involve low-resolution footage, and there is no control of how far the subjects may be from the camera in the first place. This situation is suitable for the application of upsampling (super-resolution) algorithms since they may be able to recover the discriminant properties of the subjects involved. While general super-resolution approaches were proposed to enhance image quality for human-level perception, biometrics super-resolution methods seek the best "computer perception" version of the image since their focus is on improving automatic recognition performance. Convolutional neural networks and deep learning algorithms, in general, have been applied to computer vision tasks and are now state-of-the-art for several sub-domains, including image classification, restoration, and super-resolution. However, no work has evaluated the effects that the latest proposed super-resolution methods may have upon the accuracy and face verification performance in low-resolution "in-the-wild" data. This project aimed at evaluating and adapting different deep neural network architectures for the task of face super-resolution driven by face recognition performance in real-world low-resolution images. The experimental results in a real-world surveillance and attendance datasets showed that general super-resolution architectures might enhance face verification performance of deep neural networks trained on high-resolution faces. Also, since neural networks are function approximators and can be trained based on specific objective functions, the use of a customized loss function optimized for feature extraction showed promising results for recovering discriminant features in low-resolution face images.