 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-Modality Clustering-based Self-Labeling for Multimodal Data Classification
Aug 05, 2024



Technological advances facilitate the ability to acquire multimodal data, posing a challenge for recognition systems while also providing an opportunity to use the heterogeneous nature of the information to increase the generalization capability of models. An often overlooked issue is the cost of the labeling process, which is typically high due to the need for a significant investment in time and money associated with human experts. Existing semi-supervised learning methods often focus on operating in the feature space created by the fusion of available modalities, neglecting the potential for cross-utilizing complementary information available in each modality. To address this problem, we propose Cross-Modality Clustering-based Self-Labeling (CMCSL). Based on a small set of pre-labeled data, CMCSL groups instances belonging to each modality in the deep feature space and then propagates known labels within the resulting clusters. Next, information about the instances' class membership in each modality is exchanged based on the Euclidean distance to ensure more accurate labeling. Experimental evaluation conducted on 20 datasets derived from the MM-IMDb dataset indicates that cross-propagation of labels between modalities -- especially when the number of pre-labeled instances is small -- can allow for more reliable labeling and thus increase the classification performance in each modality.
SMOClust: Synthetic Minority Oversampling based on Stream Clustering for Evolving Data Streams
Aug 28, 2023



Many real-world data stream applications not only suffer from concept drift but also class imbalance. Yet, very few existing studies investigated this joint challenge. Data difficulty factors, which have been shown to be key challenges in class imbalanced data streams, are not taken into account by existing approaches when learning class imbalanced data streams. In this work, we propose a drift adaptable oversampling strategy to synthesise minority class examples based on stream clustering. The motivation is that stream clustering methods continuously update themselves to reflect the characteristics of the current underlying concept, including data difficulty factors. This nature can potentially be used to compress past information without caching data in the memory explicitly. Based on the compressed information, synthetic examples can be created within the region that recently generated new minority class examples. Experiments with artificial and real-world data streams show that the proposed approach can handle concept drift involving different minority class decomposition better than existing approaches, especially when the data stream is severely class imbalanced and presenting high proportions of safe and borderline minority class examples.
Knowledge Transfer for Dynamic Multi-objective Optimization with a Changing Number of Objectives
Jun 19, 2023



Different from most other dynamic multi-objective optimization problems (DMOPs), DMOPs with a changing number of objectives usually result in expansion or contraction of the Pareto front or Pareto set manifold. Knowledge transfer has been used for solving DMOPs, since it can transfer useful information from solving one problem instance to solve another related problem instance. However, we show that the state-of-the-art transfer algorithm for DMOPs with a changing number of objectives lacks sufficient diversity when the fitness landscape and Pareto front shape present nonseparability, deceptiveness or other challenging features. Therefore, we propose a knowledge transfer dynamic multi-objective evolutionary algorithm (KTDMOEA) to enhance population diversity after changes by expanding/contracting the Pareto set in response to an increase/decrease in the number of objectives. This enables a solution set with good convergence and diversity to be obtained after optimization. Comprehensive studies using 13 DMOP benchmarks with a changing number of objectives demonstrate that our proposed KTDMOEA is successful in enhancing population diversity compared to state-of-the-art algorithms, improving optimization especially in fast changing environments.
Evolutionary Optimization for Proactive and Dynamic Computing Resource Allocation in Open Radio Access Network
Jan 12, 2022



Intelligent techniques are urged to achieve automatic allocation of the computing resource in Open Radio Access Network (O-RAN), to save computing resource, increase utilization rate of them and decrease the delay. However, the existing problem formulation to solve this resource allocation problem is unsuitable as it defines the capacity utility of resource in an inappropriate way and tends to cause much delay. Moreover, the existing problem has only been attempted to be solved based on greedy search, which is not ideal as it could get stuck into local optima. Considering those, a new formulation that better describes the problem is proposed. In addition, as a well-known global search meta heuristic approach, an evolutionary algorithm (EA) is designed tailored for solving the new problem formulation, to find a resource allocation scheme to proactively and dynamically deploy the computing resource for processing upcoming traffic data. Experimental studies carried out on several real-world datasets and newly generated artificial datasets with more properties beyond the real-world datasets have demonstrated the significant superiority over a baseline greedy algorithm under different parameter settings. Moreover, experimental studies are taken to compare the proposed EA and two variants, to indicate the impact of different algorithm choices.
A Novel Generalised Meta-Heuristic Framework for Dynamic Capacitated Arc Routing Problems
Apr 14, 2021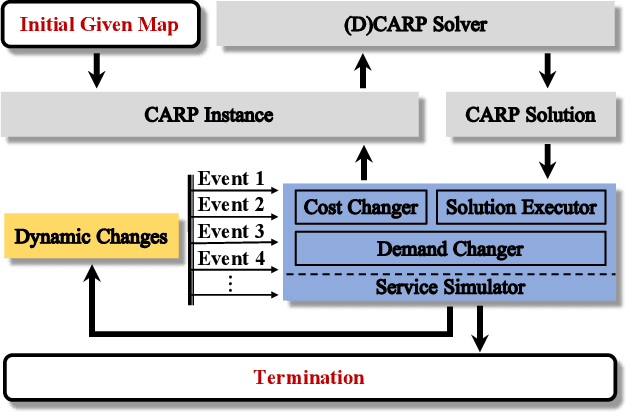
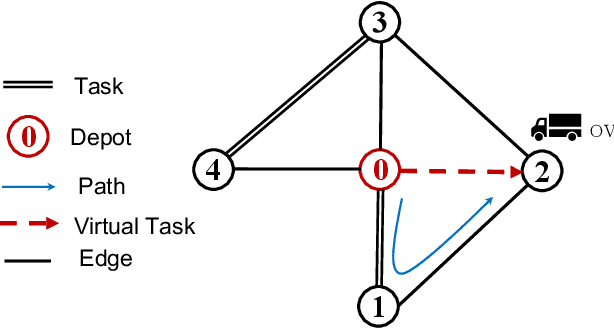
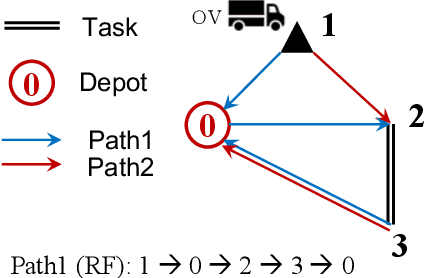
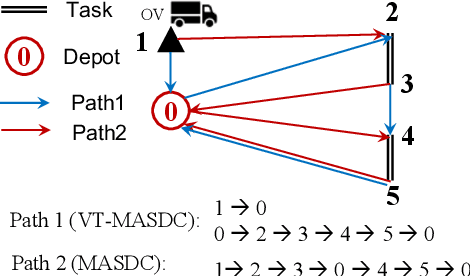
The capacitated arc routing problem (CARP) is a challenging combinatorial optimisation problem abstracted from typical real-world applications, like waste collection and mail delivery. However, few studies considered dynamic changes during the vehicles' service, which can make the original schedule infeasible or obsolete. The few existing studies are limited by dynamic scenarios that can suffer single types of dynamic events, and by algorithms that rely on special operators or representations, being unable to benefit from the wealth of contributions provided by the static CARP literature. Here, we provide the first mathematical formulation for dynamic CARP (DCARP) and design a simulation system to execute the CARP solutions and generate DCARP instances with several common dynamic events. We then propose a novel framework able to generalise all existing static CARP optimisation algorithms so that they can cope with DCARP instances. The framework has the option to enhance optimisation performance for DCARP instances based on a restart strategy that makes no use of past history, and a sequence transfer strategy that benefits from past optimisation experience. Empirical studies are conducted on a wide range of DCARP instances. The results highlight the need for tackling dynamic changes and show that the proposed framework significantly improves over existing algorithms.
Metaheuristics "In the Large"
Dec 18, 2020Following decades of sustained improvement, metaheuristics are one of the great success stories of optimization research. However, in order for research in metaheuristics to avoid fragmentation and a lack of reproducibility, there is a pressing need for stronger scientific and computational infrastructure to support the development, analysis and comparison of new approaches. We argue that, via principled choice of infrastructure support, the field can pursue a higher level of scientific enquiry. We describe our vision and report on progress, showing how the adoption of common protocols for all metaheuristics can help liberate the potential of the field, easing the exploration of the design space of metaheuristics.
Multi-Source Transfer Learning for Non-Stationary Environments
Jan 07, 2019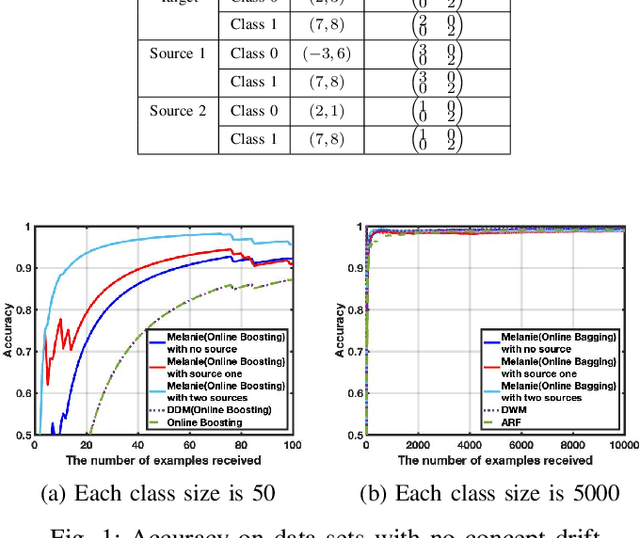
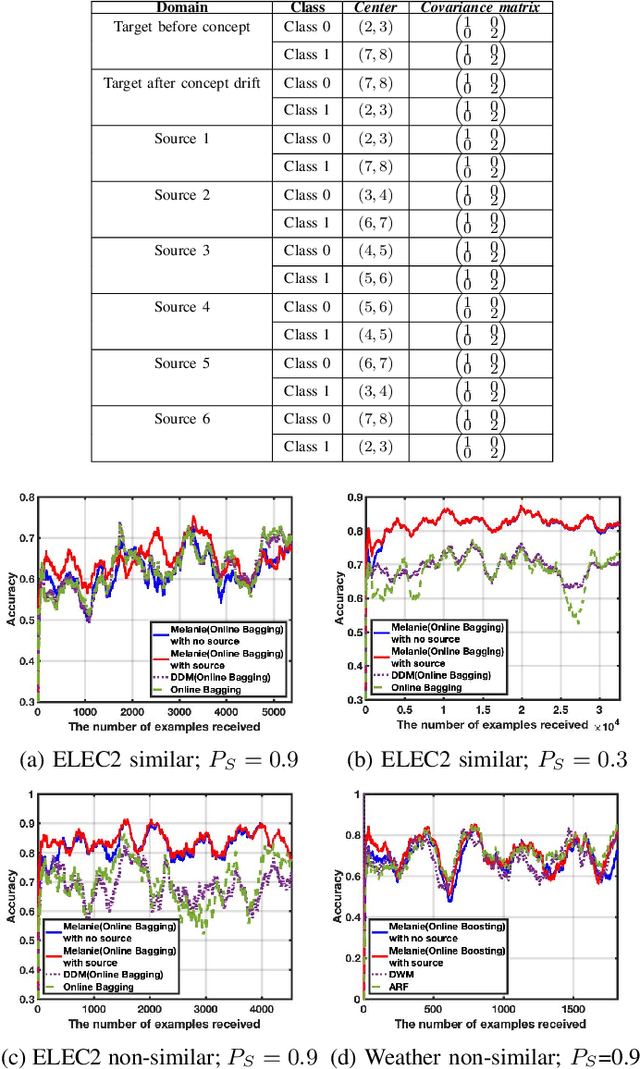
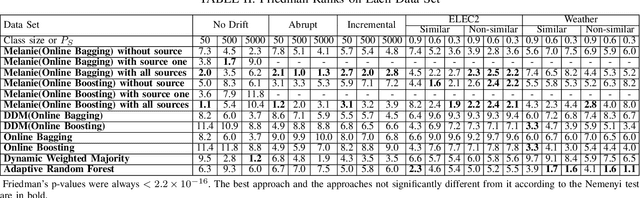

In data stream mining, predictive models typically suffer drops in predictive performance due to concept drift. As enough data representing the new concept must be collected for the new concept to be well learnt, the predictive performance of existing models usually takes some time to recover from concept drift. To speed up recovery from concept drift and improve predictive performance in data stream mining, this work proposes a novel approach called Multi-sourcE onLine TrAnsfer learning for Non-statIonary Environments (Melanie). Melanie is the first approach able to transfer knowledge between multiple data streaming sources in non-stationary environments. It creates several sub-classifiers to learn different aspects from different source and target concepts over time. The sub-classifiers that match the current target concept well are identified, and used to compose an ensemble for predicting examples from the target concept. We evaluate Melanie on several synthetic data streams containing different types of concept drift and on real world data streams. The results indicate that Melanie can deal with a variety drifts and improve predictive performance over existing data stream learning algorithms by making use of multiple sources.
Proceedings of the IJCAI 2017 Workshop on Learning in the Presence of Class Imbalance and Concept Drift
Jul 28, 2017

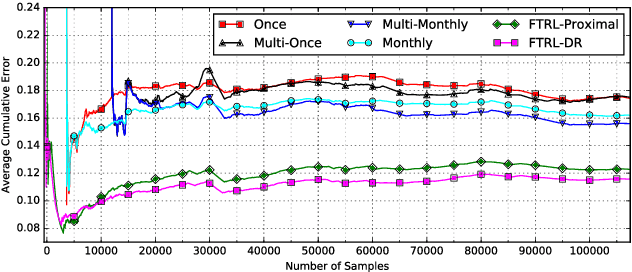
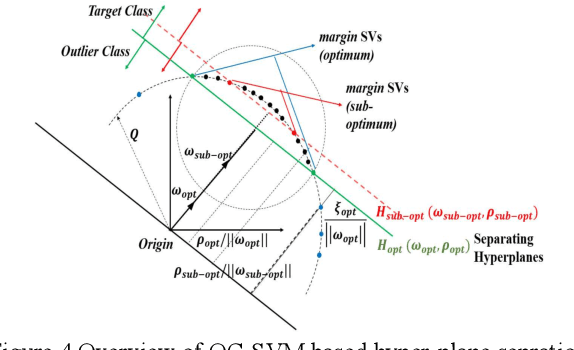
With the wide application of machine learning algorithms to the real world, class imbalance and concept drift have become crucial learning issues. Class imbalance happens when the data categories are not equally represented, i.e., at least one category is minority compared to other categories. It can cause learning bias towards the majority class and poor generalization. Concept drift is a change in the underlying distribution of the problem, and is a significant issue specially when learning from data streams. It requires learners to be adaptive to dynamic changes. Class imbalance and concept drift can significantly hinder predictive performance, and the problem becomes particularly challenging when they occur simultaneously. This challenge arises from the fact that one problem can affect the treatment of the other. For example, drift detection algorithms based on the traditional classification error may be sensitive to the imbalanced degree and become less effective; and class imbalance techniques need to be adaptive to changing imbalance rates, otherwise the class receiving the preferential treatment may not be the correct minority class at the current moment. Therefore, the mutual effect of class imbalance and concept drift should be considered during algorithm design. The aim of this workshop is to bring together researchers from the areas of class imbalance learning and concept drift in order to encourage discussions and new collaborations on solving the combined issue of class imbalance and concept drift. It provides a forum for international researchers and practitioners to share and discuss their original work on addressing new challenges and research issues in class imbalance learning, concept drift, and the combined issues of class imbalance and concept drift. The proceedings include 8 papers on these topics.
A Systematic Study of Online Class Imbalance Learning with Concept Drift
Mar 20, 2017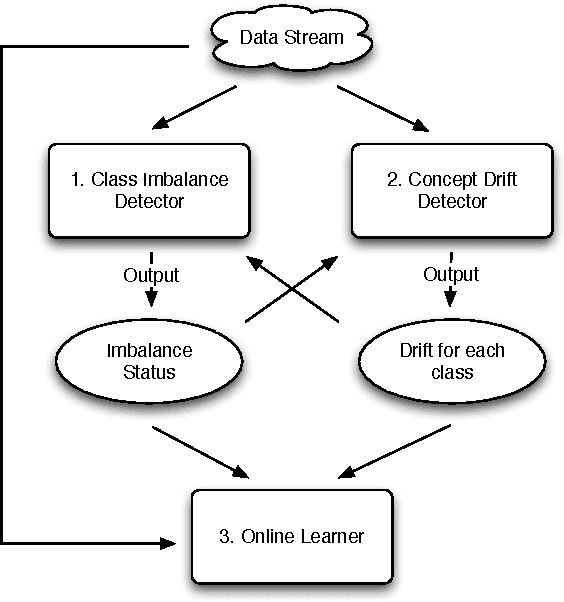
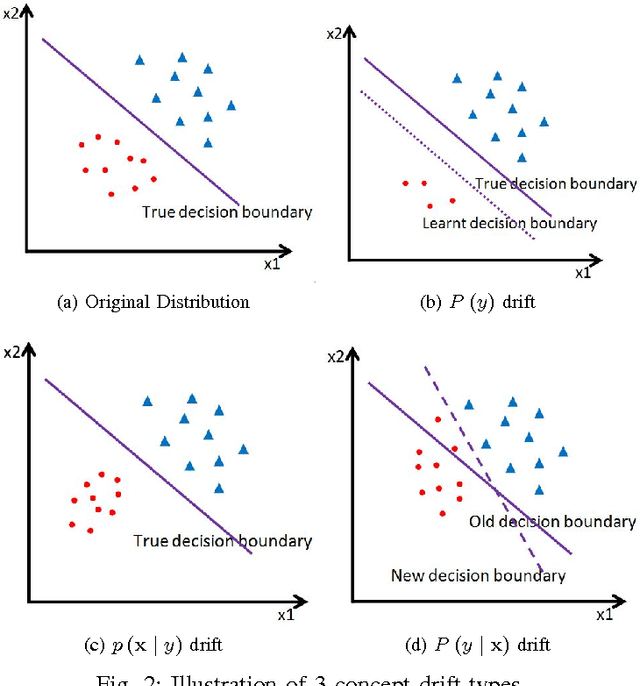
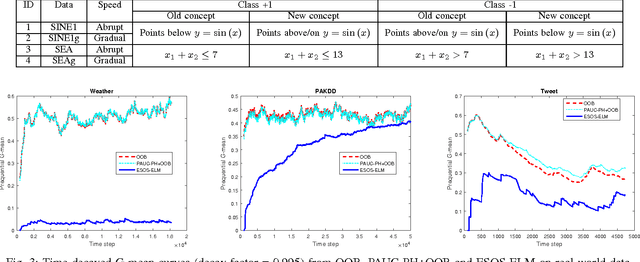

As an emerging research topic, online class imbalance learning often combines the challenges of both class imbalance and concept drift. It deals with data streams having very skewed class distributions, where concept drift may occur. It has recently received increased research attention; however, very little work addresses the combined problem where both class imbalance and concept drift coexist. As the first systematic study of handling concept drift in class-imbalanced data streams, this paper first provides a comprehensive review of current research progress in this field, including current research focuses and open challenges. Then, an in-depth experimental study is performed, with the goal of understanding how to best overcome concept drift in online learning with class imbalance. Based on the analysis, a general guideline is proposed for the development of an effective algorithm.