 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReasoning4Sciences: Bridging Reasoning Language Models to All Scientific Branches
May 31, 2026While Reasoning Language Models (RLMs) are rapidly emerging as powerful tools for scientific research, their impact is primarily concentrated in "hard science" fields. The slow -- or lack of -- adoption of RLMs in other branches of science is causing a widening gap in research productivity. In this survey, we provide the first comprehensive analysis of RLM adoption across 28 scientific disciplines following the classification used by the European Research Council (ERC), spanning the Social Sciences and Humanities, Physical Sciences and Engineering, and Life Sciences. We examine how RLMs are developed, evaluated, and applied across disciplines. Furthermore, we introduce a maturity-oriented assessment framework based on available domain-specific development and evaluation resources, revealing substantial disparities in RLM maturity that become even more pronounced when only publicly available resources are considered. Finally, we highlight current implementation paradigms that are gaining popularity across disciplines, current challenges, and future directions in enabling RLM adoption across science.
How to RETIRE Tabular Data in Favor of Discrete Digital Signal Representation
Mar 25, 2025



The successes achieved by deep neural networks in computer vision tasks have led in recent years to the emergence of a new research area dubbed Multi-Dimensional Encoding (MDE). Methods belonging to this family aim to transform tabular data into a homogeneous form of discrete digital signals (images) to apply convolutional networks to initially unsuitable problems. Despite the successive emerging works, the pool of multi-dimensional encoding methods is still low, and the scope of research on existing modality encoding techniques is quite limited. To contribute to this area of research, we propose the Radar-based Encoding from Tabular to Image REpresentation (RETIRE), which allows tabular data to be represented as radar graphs, capturing the feature characteristics of each problem instance. RETIRE was compared with a pool of state-of-the-art MDE algorithms as well as with XGBoost in terms of classification accuracy and computational complexity. In addition, an analysis was carried out regarding transferability and explainability to provide more insight into both RETIRE and existing MDE techniques. The results obtained, supported by statistical analysis, confirm the superiority of RETIRE over other established MDE methods.
Structuring the Processing Frameworks for Data Stream Evaluation and Application
Nov 11, 2024The following work addresses the problem of frameworks for data stream processing that can be used to evaluate the solutions in an environment that resembles real-world applications. The definition of structured frameworks stems from a need to reliably evaluate the data stream classification methods, considering the constraints of delayed and limited label access. The current experimental evaluation often boundlessly exploits the assumption of their complete and immediate access to monitor the recognition quality and to adapt the methods to the changing concepts. The problem is leveraged by reviewing currently described methods and techniques for data stream processing and verifying their outcomes in simulated environment. The effect of the work is a proposed taxonomy of data stream processing frameworks, showing the linkage between drift detection and classification methods considering a natural phenomenon of label delay.
Cross-Modality Clustering-based Self-Labeling for Multimodal Data Classification
Aug 05, 2024



Technological advances facilitate the ability to acquire multimodal data, posing a challenge for recognition systems while also providing an opportunity to use the heterogeneous nature of the information to increase the generalization capability of models. An often overlooked issue is the cost of the labeling process, which is typically high due to the need for a significant investment in time and money associated with human experts. Existing semi-supervised learning methods often focus on operating in the feature space created by the fusion of available modalities, neglecting the potential for cross-utilizing complementary information available in each modality. To address this problem, we propose Cross-Modality Clustering-based Self-Labeling (CMCSL). Based on a small set of pre-labeled data, CMCSL groups instances belonging to each modality in the deep feature space and then propagates known labels within the resulting clusters. Next, information about the instances' class membership in each modality is exchanged based on the Euclidean distance to ensure more accurate labeling. Experimental evaluation conducted on 20 datasets derived from the MM-IMDb dataset indicates that cross-propagation of labels between modalities -- especially when the number of pre-labeled instances is small -- can allow for more reliable labeling and thus increase the classification performance in each modality.
Employing Sentence Space Embedding for Classification of Data Stream from Fake News Domain
Jul 15, 2024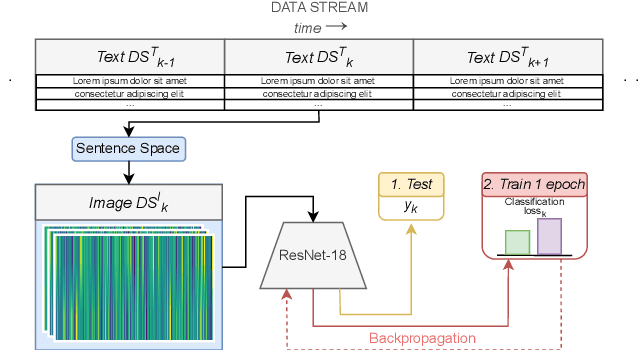
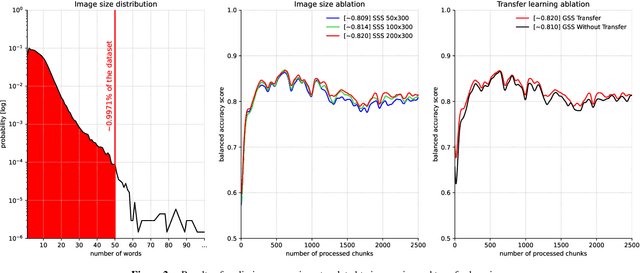
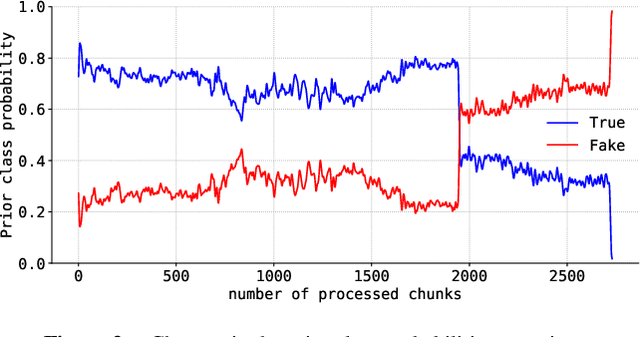
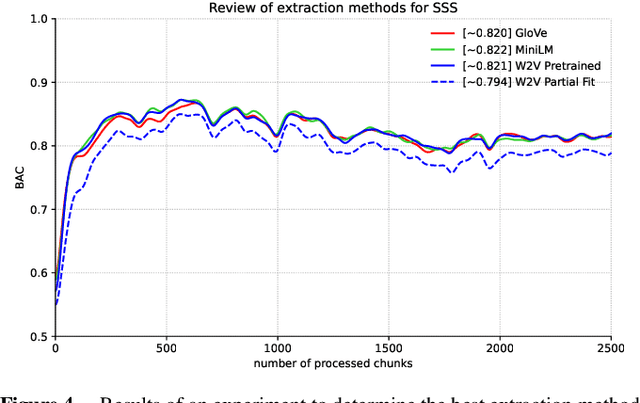
Tabular data is considered the last unconquered castle of deep learning, yet the task of data stream classification is stated to be an equally important and demanding research area. Due to the temporal constraints, it is assumed that deep learning methods are not the optimal solution for application in this field. However, excluding the entire -- and prevalent -- group of methods seems rather rash given the progress that has been made in recent years in its development. For this reason, the following paper is the first to present an approach to natural language data stream classification using the sentence space method, which allows for encoding text into the form of a discrete digital signal. This allows the use of convolutional deep networks dedicated to image classification to solve the task of recognizing fake news based on text data. Based on the real-life Fakeddit dataset, the proposed approach was compared with state-of-the-art algorithms for data stream classification based on generalization ability and time complexity.
Employing Two-Dimensional Word Embedding for Difficult Tabular Data Stream Classification
Apr 24, 2024Rapid technological advances are inherently linked to the increased amount of data, a substantial portion of which can be interpreted as data stream, capable of exhibiting the phenomenon of concept drift and having a high imbalance ratio. Consequently, developing new approaches to classifying difficult data streams is a rapidly growing research area. At the same time, the proliferation of deep learning and transfer learning, as well as the success of convolutional neural networks in computer vision tasks, have contributed to the emergence of a new research trend, namely Multi-Dimensional Encoding (MDE), focusing on transforming tabular data into a homogeneous form of a discrete digital signal. This paper proposes Streaming Super Tabular Machine Learning (SSTML), thereby exploring for the first time the potential of MDE in the difficult data stream classification task. SSTML encodes consecutive data chunks into an image representation using the STML algorithm and then performs a single ResNet-18 training epoch. Experiments conducted on synthetic and real data streams have demonstrated the ability of SSTML to achieve classification quality statistically significantly superior to state-of-the-art algorithms while maintaining comparable processing time.
Active Weighted Aging Ensemble for Drifted Data Stream Classification
Dec 19, 2021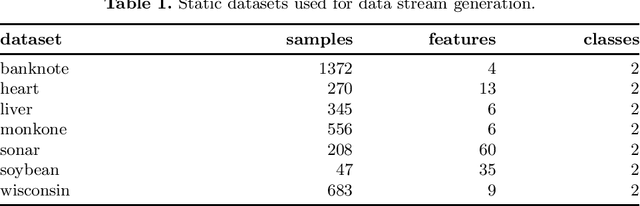
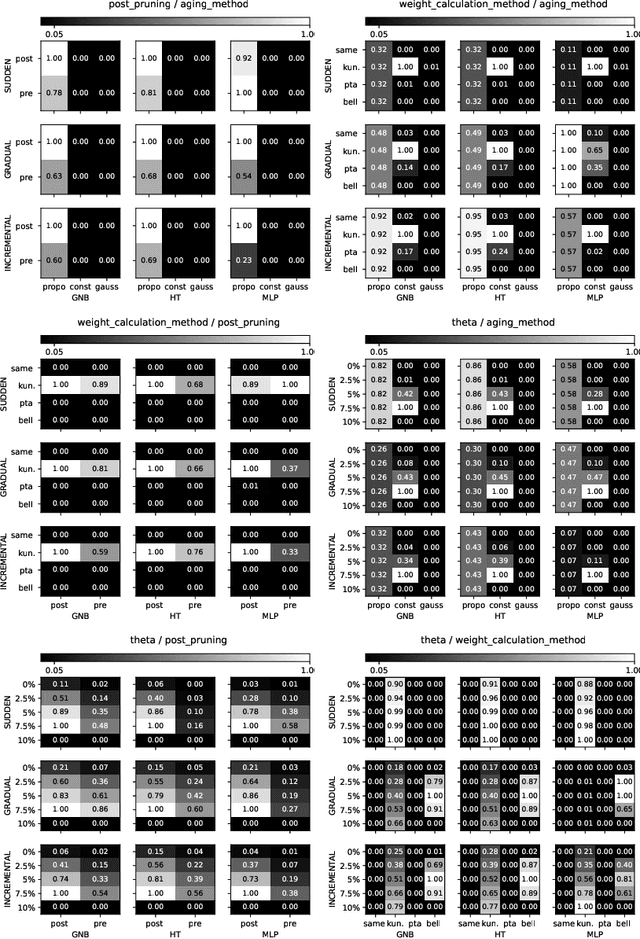
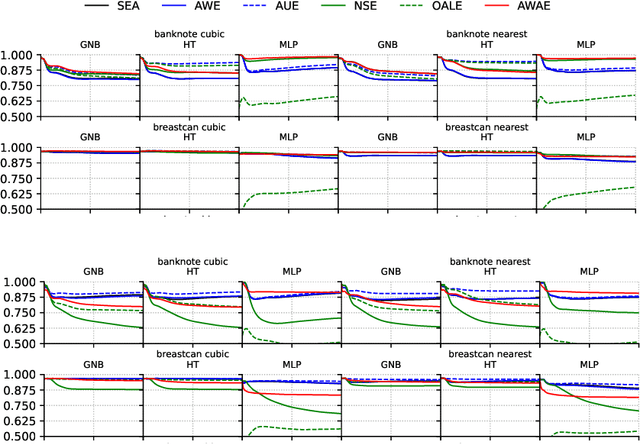
One of the significant problems of streaming data classification is the occurrence of concept drift, consisting of the change of probabilistic characteristics of the classification task. This phenomenon destabilizes the performance of the classification model and seriously degrades its quality. An appropriate strategy counteracting this phenomenon is required to adapt the classifier to the changing probabilistic characteristics. One of the significant problems in implementing such a solution is the access to data labels. It is usually costly, so to minimize the expenses related to this process, learning strategies based on semi-supervised learning are proposed, e.g., employing active learning methods indicating which of the incoming objects are valuable to be labeled for improving the classifier's performance. This paper proposes a novel chunk-based method for non-stationary data streams based on classifier ensemble learning and an active learning strategy considering a limited budget that can be successfully applied to any data stream classification algorithm. The proposed method has been evaluated through computer experiments using both real and generated data streams. The results confirm the high quality of the proposed algorithm over state-of-the-art methods.
stream-learn -- open-source Python library for difficult data stream batch analysis
Jan 29, 2020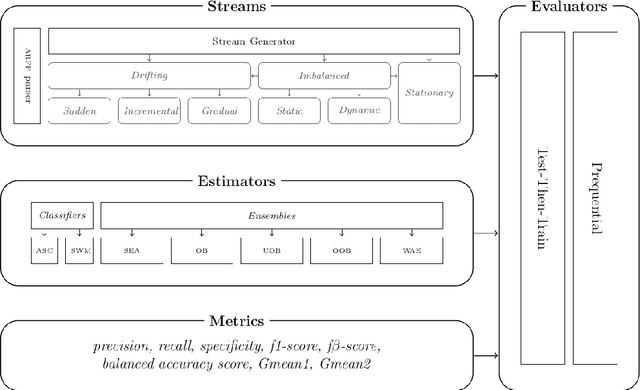
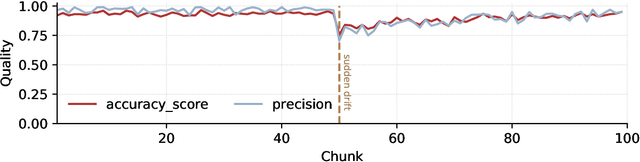

stream-learn is a Python package compatible with scikit-learn and developed for the drifting and imbalanced data stream analysis. Its main component is a stream generator, which allows to produce a synthetic data stream that may incorporate each of the three main concept drift types (i.e. sudden, gradual and incremental drift) in their recurring or non-recurring versions. The package allows conducting experiments following established evaluation methodologies (i.e. Test-Then-Train and Prequential). In addition, estimators adapted for data stream classification have been implemented, including both simple classifiers and state-of-art chunk-based and online classifier ensembles. To improve computational efficiency, package utilises its own implementations of prediction metrics for imbalanced binary classification tasks.