 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvolutionary Token-Level Prompt Optimization for Diffusion Models
Apr 10, 2026Text-to-image diffusion models exhibit strong generative performance but remain highly sensitive to prompt formulation, often requiring extensive manual trial and error to obtain satisfactory results. This motivates the development of automated, model-agnostic prompt optimization methods that can systematically explore the conditioning space beyond conventional text rewriting. This work investigates the use of a Genetic Algorithm (GA) for prompt optimization by directly evolving the token vectors employed by CLIP-based diffusion models. The GA optimizes a fitness function that combines aesthetic quality, measured by the LAION Aesthetic Predictor V2, with prompt-image alignment, assessed via CLIPScore. Experiments on 36 prompts from the Parti Prompts (P2) dataset show that the proposed approach outperforms the baseline methods, including Promptist and random search, achieving up to a 23.93% improvement in fitness. Overall, the method is adaptable to image generation models with tokenized text encoders and provides a modular framework for future extensions, the limitations and prospects of which are discussed.
Evolutionary Optimization Trumps Adam Optimization on Embedding Space Exploration
Nov 05, 2025Deep generative models, especially diffusion architectures, have transformed image generation; however, they are challenging to control and optimize for specific goals without expensive retraining. Embedding Space Exploration, especially with Evolutionary Algorithms (EAs), has been shown to be a promising method for optimizing image generation, particularly within Diffusion Models. Therefore, in this work, we study the performance of an evolutionary optimization method, namely Separable Covariance Matrix Adaptation Evolution Strategy (sep-CMA-ES), against the widely adopted Adaptive Moment Estimation (Adam), applied to Stable Diffusion XL Turbo's prompt embedding vector. The evaluation of images combines the LAION Aesthetic Predictor V2 with CLIPScore into a weighted fitness function, allowing flexible trade-offs between visual appeal and adherence to prompts. Experiments on a subset of the Parti Prompts (P2) dataset showcase that sep-CMA-ES consistently yields superior improvements in aesthetic and alignment metrics in comparison to Adam. Results indicate that the evolutionary method provides efficient, gradient-free optimization for diffusion models, enhancing controllability without the need for fine-tuning. This study emphasizes the potential of evolutionary methods for embedding space exploration of deep generative models and outlines future research directions.
GreenFactory: Ensembling Zero-Cost Proxies to Estimate Performance of Neural Networks
May 14, 2025Determining the performance of a Deep Neural Network during Neural Architecture Search processes is essential for identifying optimal architectures and hyperparameters. Traditionally, this process requires training and evaluation of each network, which is time-consuming and resource-intensive. Zero-cost proxies estimate performance without training, serving as an alternative to traditional training. However, recent proxies often lack generalization across diverse scenarios and provide only relative rankings rather than predicted accuracies. To address these limitations, we propose GreenFactory, an ensemble of zero-cost proxies that leverages a random forest regressor to combine multiple predictors' strengths and directly predict model test accuracy. We evaluate GreenFactory on NATS-Bench, achieving robust results across multiple datasets. Specifically, GreenFactory achieves high Kendall correlations on NATS-Bench-SSS, indicating substantial agreement between its predicted scores and actual performance: 0.907 for CIFAR-10, 0.945 for CIFAR-100, and 0.920 for ImageNet-16-120. Similarly, on NATS-Bench-TSS, we achieve correlations of 0.921 for CIFAR-10, 0.929 for CIFAR-100, and 0.908 for ImageNet-16-120, showcasing its reliability in both search spaces.
Evolutionary algorithms meet self-supervised learning: a comprehensive survey
Apr 09, 2025The number of studies that combine Evolutionary Machine Learning and self-supervised learning has been growing steadily in recent years. Evolutionary Machine Learning has been shown to help automate the design of machine learning algorithms and to lead to more reliable solutions. Self-supervised learning, on the other hand, has produced good results in learning useful features when labelled data is limited. This suggests that the combination of these two areas can help both in shaping evolutionary processes and in automating the design of deep neural networks, while also reducing the need for labelled data. Still, there are no detailed reviews that explain how Evolutionary Machine Learning and self-supervised learning can be used together. To help with this, we provide an overview of studies that bring these areas together. Based on this growing interest and the range of existing works, we suggest a new sub-area of research, which we call Evolutionary Self-Supervised Learning and introduce a taxonomy for it. Finally, we point out some of the main challenges and suggest directions for future research to help Evolutionary Self-Supervised Learning grow and mature as a field.
On the Dynamics of Mating Preferences in Genetic Programming
Apr 08, 2025Several mating restriction techniques have been implemented in Evolutionary Algorithms to promote diversity. From similarity-based selection to niche preservation, the general goal is to avoid premature convergence by not having fitness pressure as the single evolutionary force. In a way, such methods can resemble the mechanisms involved in Sexual Selection, although generally assuming a simplified approach. Recently, a selection method called mating Preferences as Ideal Mating Partners (PIMP) has been applied to GP, providing promising results both in performance and diversity maintenance. The method mimics Mate Choice through the unbounded evolution of personal preferences rather than having a single set of rules to shape parent selection. As such, PIMP allows ideal mate representations to evolve freely, thus potentially taking advantage of Sexual Selection as a dynamic secondary force to fitness pressure. However, it is still unclear how mating preferences affect the overall population and how dependent they are on set-up choices. In this work, we tracked the evolution of individual preferences through different mutation types, searching for patterns and evidence of self-reinforcement. Results suggest that mating preferences do not stand on their own, relying on subtree mutation to avoid convergence to single-node trees. Nevertheless, they consistently promote smaller and more balanced solutions depth-wise than a standard tournament selection, reducing the impact of bloat. Furthermore, when coupled with subtree mutation it also results in more solution diversity with statistically significant results.
GreenMachine: Automatic Design of Zero-Cost Proxies for Energy-Efficient NAS
Nov 22, 2024



Artificial Intelligence (AI) has driven innovations and created new opportunities across various sectors. However, leveraging domain-specific knowledge often requires automated tools to design and configure models effectively. In the case of Deep Neural Networks (DNNs), researchers and practitioners usually resort to Neural Architecture Search (NAS) approaches, which are resource- and time-intensive, requiring the training and evaluation of numerous candidate architectures. This raises sustainability concerns, particularly due to the high energy demands involved, creating a paradox: the pursuit of the most effective model can undermine sustainability goals. To mitigate this issue, zero-cost proxies have emerged as a promising alternative. These proxies estimate a model's performance without the need for full training, offering a more efficient approach. This paper addresses the challenges of model evaluation by automatically designing zero-cost proxies to assess DNNs efficiently. Our method begins with a randomly generated set of zero-cost proxies, which are evolved and tested using the NATS-Bench benchmark. We assess the proxies' effectiveness using both randomly sampled and stratified subsets of the search space, ensuring they can differentiate between low- and high-performing networks and enhance generalizability. Results show our method outperforms existing approaches on the stratified sampling strategy, achieving strong correlations with ground truth performance, including a Kendall correlation of 0.89 on CIFAR-10 and 0.77 on CIFAR-100 with NATS-Bench-SSS and a Kendall correlation of 0.78 on CIFAR-10 and 0.71 on CIFAR-100 with NATS-Bench-TSS.
Towards evolution of Deep Neural Networks through contrastive Self-Supervised learning
Jun 20, 2024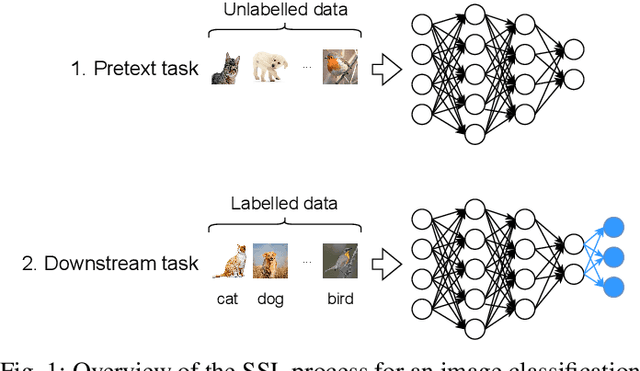
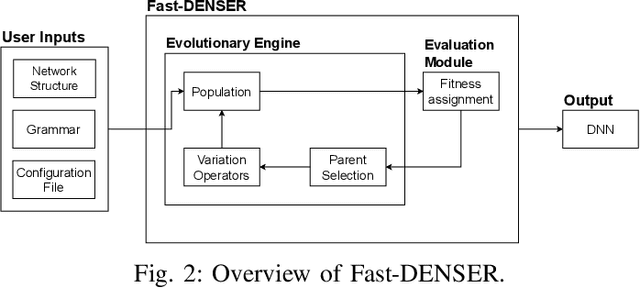
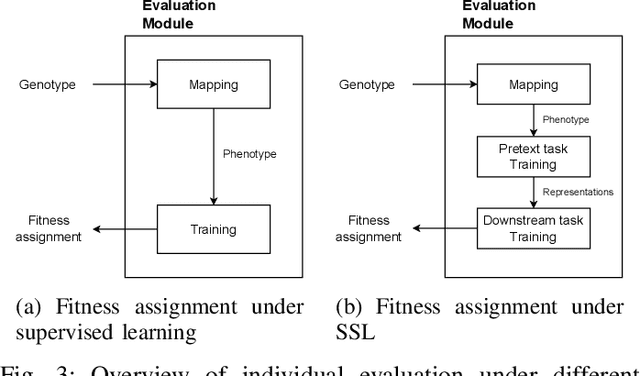
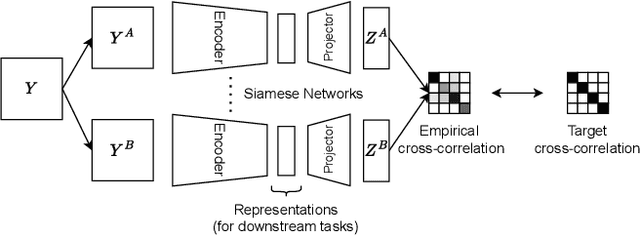
Deep Neural Networks (DNNs) have been successfully applied to a wide range of problems. However, two main limitations are commonly pointed out. The first one is that they require long time to design. The other is that they heavily rely on labelled data, which can sometimes be costly and hard to obtain. In order to address the first problem, neuroevolution has been proved to be a plausible option to automate the design of DNNs. As for the second problem, self-supervised learning has been used to leverage unlabelled data to learn representations. Our goal is to study how neuroevolution can help self-supervised learning to bridge the gap to supervised learning in terms of performance. In this work, we propose a framework that is able to evolve deep neural networks using self-supervised learning. Our results on the CIFAR-10 dataset show that it is possible to evolve adequate neural networks while reducing the reliance on labelled data. Moreover, an analysis to the structure of the evolved networks suggests that the amount of labelled data fed to them has less effect on the structure of networks that learned via self-supervised learning, when compared to individuals that relied on supervised learning.
Evaluation Metrics for Automated Typographic Poster Generation
Feb 10, 2024Computational Design approaches facilitate the generation of typographic design, but evaluating these designs remains a challenging task. In this paper, we propose a set of heuristic metrics for typographic design evaluation, focusing on their legibility, which assesses the text visibility, aesthetics, which evaluates the visual quality of the design, and semantic features, which estimate how effectively the design conveys the content semantics. We experiment with a constrained evolutionary approach for generating typographic posters, incorporating the proposed evaluation metrics with varied setups, and treating the legibility metrics as constraints. We also integrate emotion recognition to identify text semantics automatically and analyse the performance of the approach and the visual characteristics outputs.
Towards Physical Plausibility in Neuroevolution Systems
Jan 31, 2024The increasing usage of Artificial Intelligence (AI) models, especially Deep Neural Networks (DNNs), is increasing the power consumption during training and inference, posing environmental concerns and driving the need for more energy-efficient algorithms and hardware solutions. This work addresses the growing energy consumption problem in Machine Learning (ML), particularly during the inference phase. Even a slight reduction in power usage can lead to significant energy savings, benefiting users, companies, and the environment. Our approach focuses on maximizing the accuracy of Artificial Neural Network (ANN) models using a neuroevolutionary framework whilst minimizing their power consumption. To do so, power consumption is considered in the fitness function. We introduce a new mutation strategy that stochastically reintroduces modules of layers, with power-efficient modules having a higher chance of being chosen. We introduce a novel technique that allows training two separate models in a single training step whilst promoting one of them to be more power efficient than the other while maintaining similar accuracy. The results demonstrate a reduction in power consumption of ANN models by up to 29.2% without a significant decrease in predictive performance.
All You Need Is Sex for Diversity
Mar 30, 2023Maintaining genetic diversity as a means to avoid premature convergence is critical in Genetic Programming. Several approaches have been proposed to achieve this, with some focusing on the mating phase from coupling dissimilar solutions to some form of self-adaptive selection mechanism. In nature, genetic diversity can be the consequence of many different factors, but when considering reproduction Sexual Selection can have an impact on promoting variety within a species. Specifically, Mate Choice often results in different selective pressures between sexes, which in turn may trigger evolutionary differences among them. Although some mechanisms of Sexual Selection have been applied to Genetic Programming in the past, the literature is scarce when it comes to mate choice. Recently, a way of modelling mating preferences by ideal mate representations was proposed, achieving good results when compared to a standard approach. These mating preferences evolve freely in a self-adaptive fashion, creating an evolutionary driving force of its own alongside fitness pressure. The inner mechanisms of this approach operate from personal choice, as each individual has its own representation of a perfect mate which affects the mate to be selected. In this paper, we compare this method against a random mate choice to assess whether there are advantages in evolving personal preferences. We conducted experiments using three symbolic regression problems and different mutation rates. The results show that self-adaptive mating preferences are able to create a more diverse set of solutions when compared to the traditional approach and a random mate approach (with statistically significant differences) and have a higher success rate in three of the six instances tested.