 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNERO-Net: A Neuroevolutionary Approach for the Design of Adversarially Robust CNNs
Mar 26, 2026Neuroevolution automates the complex task of neural network design but often ignores the inherent adversarial fragility of evolved models which is a barrier to adoption in safety-critical scenarios. While robust training methods have received significant attention, the design of architectures exhibiting intrinsic robustness remains largely unexplored. In this paper, we propose NERO-Net, a neuroevolutionary approach to design convolutional neural networks better equipped to resist adversarial attacks. Our search strategy isolates architectural influence on robustness by avoiding adversarial training during the evolutionary loop. As such, our fitness function promotes candidates that, even trained with standard (non-robust) methods, achieve high post-attack accuracy without sacrificing the accuracy on clean samples. We assess NERO-Net on CIFAR-10 with a specific focus on $L_\infty$-robustness. In particular, the fittest individual emerged from evolutionary search with 33% accuracy against FGSM, used as an efficient estimator for robustness during the search phase, while maintaining 87% clean accuracy. Further standard training of this individual boosted these metrics to 47% adversarial and 93% clean accuracy, suggesting inherent architectural robustness. Adversarial training brings the overall accuracy of the model up to 40% against AutoAttack.
GreenFactory: Ensembling Zero-Cost Proxies to Estimate Performance of Neural Networks
May 14, 2025Determining the performance of a Deep Neural Network during Neural Architecture Search processes is essential for identifying optimal architectures and hyperparameters. Traditionally, this process requires training and evaluation of each network, which is time-consuming and resource-intensive. Zero-cost proxies estimate performance without training, serving as an alternative to traditional training. However, recent proxies often lack generalization across diverse scenarios and provide only relative rankings rather than predicted accuracies. To address these limitations, we propose GreenFactory, an ensemble of zero-cost proxies that leverages a random forest regressor to combine multiple predictors' strengths and directly predict model test accuracy. We evaluate GreenFactory on NATS-Bench, achieving robust results across multiple datasets. Specifically, GreenFactory achieves high Kendall correlations on NATS-Bench-SSS, indicating substantial agreement between its predicted scores and actual performance: 0.907 for CIFAR-10, 0.945 for CIFAR-100, and 0.920 for ImageNet-16-120. Similarly, on NATS-Bench-TSS, we achieve correlations of 0.921 for CIFAR-10, 0.929 for CIFAR-100, and 0.908 for ImageNet-16-120, showcasing its reliability in both search spaces.
On the Dynamics of Mating Preferences in Genetic Programming
Apr 08, 2025Several mating restriction techniques have been implemented in Evolutionary Algorithms to promote diversity. From similarity-based selection to niche preservation, the general goal is to avoid premature convergence by not having fitness pressure as the single evolutionary force. In a way, such methods can resemble the mechanisms involved in Sexual Selection, although generally assuming a simplified approach. Recently, a selection method called mating Preferences as Ideal Mating Partners (PIMP) has been applied to GP, providing promising results both in performance and diversity maintenance. The method mimics Mate Choice through the unbounded evolution of personal preferences rather than having a single set of rules to shape parent selection. As such, PIMP allows ideal mate representations to evolve freely, thus potentially taking advantage of Sexual Selection as a dynamic secondary force to fitness pressure. However, it is still unclear how mating preferences affect the overall population and how dependent they are on set-up choices. In this work, we tracked the evolution of individual preferences through different mutation types, searching for patterns and evidence of self-reinforcement. Results suggest that mating preferences do not stand on their own, relying on subtree mutation to avoid convergence to single-node trees. Nevertheless, they consistently promote smaller and more balanced solutions depth-wise than a standard tournament selection, reducing the impact of bloat. Furthermore, when coupled with subtree mutation it also results in more solution diversity with statistically significant results.
Decision Tree Based Wrappers for Hearing Loss
Feb 12, 2025Audiology entities are using Machine Learning (ML) models to guide their screening towards people at risk. Feature Engineering (FE) focuses on optimizing data for ML models, with evolutionary methods being effective in feature selection and construction tasks. This work aims to benchmark an evolutionary FE wrapper, using models based on decision trees as proxies. The FEDORA framework is applied to a Hearing Loss (HL) dataset, being able to reduce data dimensionality and statistically maintain baseline performance. Compared to traditional methods, FEDORA demonstrates superior performance, with a maximum balanced accuracy of 76.2%, using 57 features. The framework also generated an individual that achieved 72.8% balanced accuracy using a single feature.
GreenMachine: Automatic Design of Zero-Cost Proxies for Energy-Efficient NAS
Nov 22, 2024



Artificial Intelligence (AI) has driven innovations and created new opportunities across various sectors. However, leveraging domain-specific knowledge often requires automated tools to design and configure models effectively. In the case of Deep Neural Networks (DNNs), researchers and practitioners usually resort to Neural Architecture Search (NAS) approaches, which are resource- and time-intensive, requiring the training and evaluation of numerous candidate architectures. This raises sustainability concerns, particularly due to the high energy demands involved, creating a paradox: the pursuit of the most effective model can undermine sustainability goals. To mitigate this issue, zero-cost proxies have emerged as a promising alternative. These proxies estimate a model's performance without the need for full training, offering a more efficient approach. This paper addresses the challenges of model evaluation by automatically designing zero-cost proxies to assess DNNs efficiently. Our method begins with a randomly generated set of zero-cost proxies, which are evolved and tested using the NATS-Bench benchmark. We assess the proxies' effectiveness using both randomly sampled and stratified subsets of the search space, ensuring they can differentiate between low- and high-performing networks and enhance generalizability. Results show our method outperforms existing approaches on the stratified sampling strategy, achieving strong correlations with ground truth performance, including a Kendall correlation of 0.89 on CIFAR-10 and 0.77 on CIFAR-100 with NATS-Bench-SSS and a Kendall correlation of 0.78 on CIFAR-10 and 0.71 on CIFAR-100 with NATS-Bench-TSS.
Exploring Layerwise Adversarial Robustness Through the Lens of t-SNE
Jun 20, 2024



Adversarial examples, designed to trick Artificial Neural Networks (ANNs) into producing wrong outputs, highlight vulnerabilities in these models. Exploring these weaknesses is crucial for developing defenses, and so, we propose a method to assess the adversarial robustness of image-classifying ANNs. The t-distributed Stochastic Neighbor Embedding (t-SNE) technique is used for visual inspection, and a metric, which compares the clean and perturbed embeddings, helps pinpoint weak spots in the layers. Analyzing two ANNs on CIFAR-10, one designed by humans and another via NeuroEvolution, we found that differences between clean and perturbed representations emerge early on, in the feature extraction layers, affecting subsequent classification. The findings with our metric are supported by the visual analysis of the t-SNE maps.
Towards Physical Plausibility in Neuroevolution Systems
Jan 31, 2024The increasing usage of Artificial Intelligence (AI) models, especially Deep Neural Networks (DNNs), is increasing the power consumption during training and inference, posing environmental concerns and driving the need for more energy-efficient algorithms and hardware solutions. This work addresses the growing energy consumption problem in Machine Learning (ML), particularly during the inference phase. Even a slight reduction in power usage can lead to significant energy savings, benefiting users, companies, and the environment. Our approach focuses on maximizing the accuracy of Artificial Neural Network (ANN) models using a neuroevolutionary framework whilst minimizing their power consumption. To do so, power consumption is considered in the fitness function. We introduce a new mutation strategy that stochastically reintroduces modules of layers, with power-efficient modules having a higher chance of being chosen. We introduce a novel technique that allows training two separate models in a single training step whilst promoting one of them to be more power efficient than the other while maintaining similar accuracy. The results demonstrate a reduction in power consumption of ANN models by up to 29.2% without a significant decrease in predictive performance.
SPENSER: Towards a NeuroEvolutionary Approach for Convolutional Spiking Neural Networks
May 18, 2023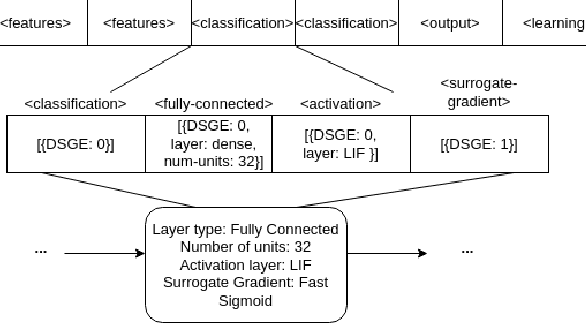
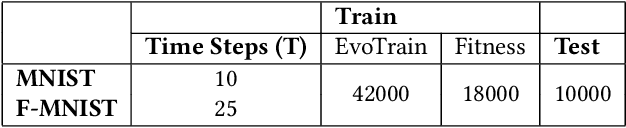
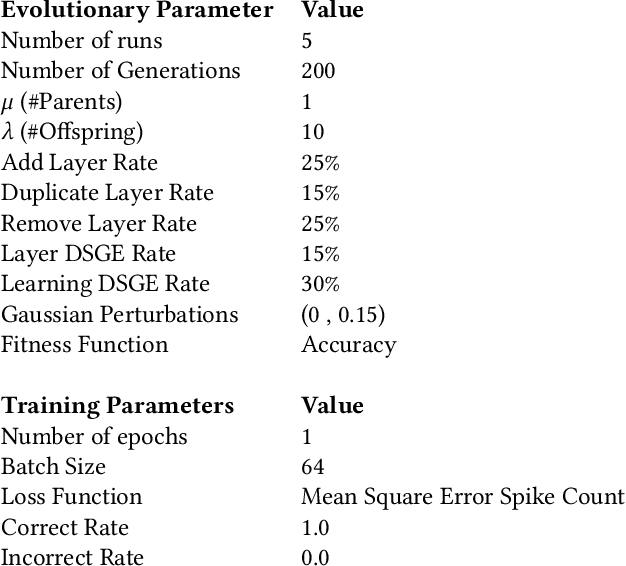
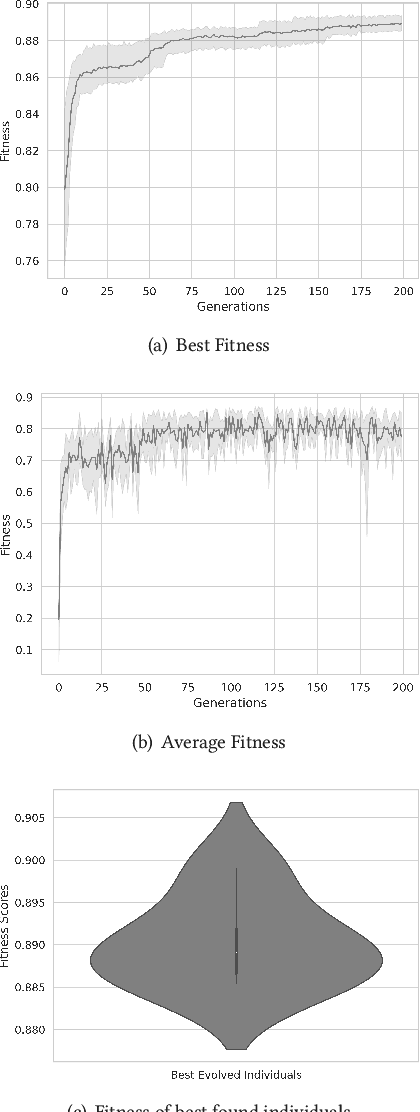
Spiking Neural Networks (SNNs) have attracted recent interest due to their energy efficiency and biological plausibility. However, the performance of SNNs still lags behind traditional Artificial Neural Networks (ANNs), as there is no consensus on the best learning algorithm for SNNs. Best-performing SNNs are based on ANN to SNN conversion or learning with spike-based backpropagation through surrogate gradients. The focus of recent research has been on developing and testing different learning strategies, with hand-tailored architectures and parameter tuning. Neuroevolution (NE), has proven successful as a way to automatically design ANNs and tune parameters, but its applications to SNNs are still at an early stage. DENSER is a NE framework for the automatic design and parametrization of ANNs, based on the principles of Genetic Algorithms (GA) and Structured Grammatical Evolution (SGE). In this paper, we propose SPENSER, a NE framework for SNN generation based on DENSER, for image classification on the MNIST and Fashion-MNIST datasets. SPENSER generates competitive performing networks with a test accuracy of 99.42% and 91.65% respectively.
Reducing the Price of Stable Cable Stayed Bridges with CMA-ES
Apr 02, 2023
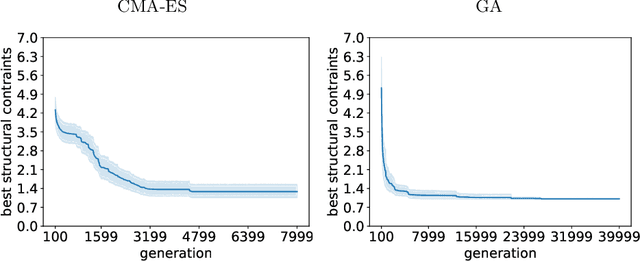
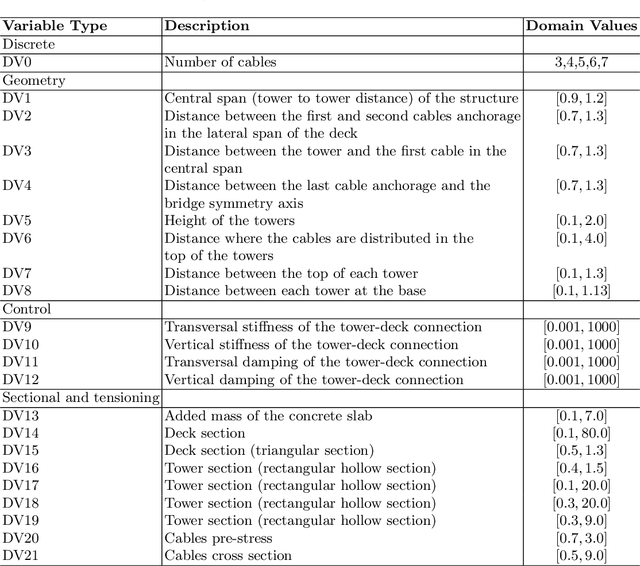
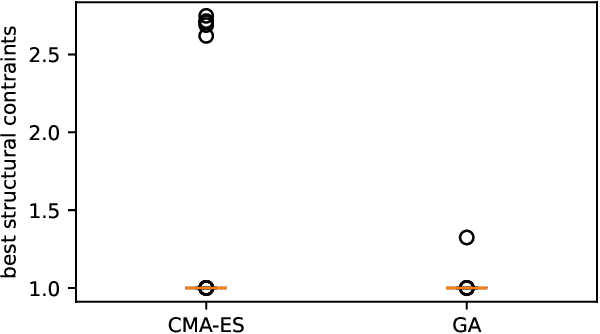
The design of cable-stayed bridges requires the determination of several design variables' values. Civil engineers usually perform this task by hand as an iteration of steps that stops when the engineer is happy with both the cost and maintaining the structural constraints of the solution. The problem's difficulty arises from the fact that changing a variable may affect other variables, meaning that they are not independent, suggesting that we are facing a deceptive landscape. In this work, we compare two approaches to a baseline solution: a Genetic Algorithm and a CMA-ES algorithm. There are two objectives when designing the bridges: minimizing the cost and maintaining the structural constraints in acceptable values to be considered safe. These are conflicting objectives, meaning that decreasing the cost often results in a bridge that is not structurally safe. The results suggest that CMA-ES is a better option for finding good solutions in the search space, beating the baseline with the same amount of evaluations, while the Genetic Algorithm could not. In concrete, the CMA-ES approach is able to design bridges that are cheaper and structurally safe.
Automatic Design of Telecom Networks with Genetic Algorithms
Apr 02, 2023With the increasing demand for high-quality internet services, deploying GPON/Fiber-to-the-Home networks is one of the biggest challenges that internet providers have to deal with due to the significant investments involved. Automated network design usage becomes more critical to aid with planning the network by minimising the costs of planning and deployment. The main objective is to tackle this problem of optimisation of networks that requires taking into account multiple factors such as the equipment placement and their configuration, the optimisation of the cable routes, the optimisation of the clients' allocation and other constraints involved in the minimisation problem. An AI-based solution is proposed to automate network design, which is a task typically done manually by teams of engineers. It is a difficult task requiring significant time to complete manually. To alleviate this tiresome task, we proposed a Genetic Algorithm using a two-level representation to design the networks automatically. To validate the approach, we compare the quality of the generated solutions with the handmade design ones that are deployed in the real world. The results show that our method can save costs and time in finding suitable and better solutions than existing ones, indicating its potential as a support design tool of solutions for GPON/Fiber-to-the-Home networks. In concrete, in the two scenarios where we validate our proposal, our approach can cut costs by 31% and by 52.2%, respectively, when compared with existing handmade ones, showcasing and validating the potential of the proposed approach.