 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNERO-Net: A Neuroevolutionary Approach for the Design of Adversarially Robust CNNs
Mar 26, 2026Neuroevolution automates the complex task of neural network design but often ignores the inherent adversarial fragility of evolved models which is a barrier to adoption in safety-critical scenarios. While robust training methods have received significant attention, the design of architectures exhibiting intrinsic robustness remains largely unexplored. In this paper, we propose NERO-Net, a neuroevolutionary approach to design convolutional neural networks better equipped to resist adversarial attacks. Our search strategy isolates architectural influence on robustness by avoiding adversarial training during the evolutionary loop. As such, our fitness function promotes candidates that, even trained with standard (non-robust) methods, achieve high post-attack accuracy without sacrificing the accuracy on clean samples. We assess NERO-Net on CIFAR-10 with a specific focus on $L_\infty$-robustness. In particular, the fittest individual emerged from evolutionary search with 33% accuracy against FGSM, used as an efficient estimator for robustness during the search phase, while maintaining 87% clean accuracy. Further standard training of this individual boosted these metrics to 47% adversarial and 93% clean accuracy, suggesting inherent architectural robustness. Adversarial training brings the overall accuracy of the model up to 40% against AutoAttack.
Exploring Layerwise Adversarial Robustness Through the Lens of t-SNE
Jun 20, 2024



Adversarial examples, designed to trick Artificial Neural Networks (ANNs) into producing wrong outputs, highlight vulnerabilities in these models. Exploring these weaknesses is crucial for developing defenses, and so, we propose a method to assess the adversarial robustness of image-classifying ANNs. The t-distributed Stochastic Neighbor Embedding (t-SNE) technique is used for visual inspection, and a metric, which compares the clean and perturbed embeddings, helps pinpoint weak spots in the layers. Analyzing two ANNs on CIFAR-10, one designed by humans and another via NeuroEvolution, we found that differences between clean and perturbed representations emerge early on, in the feature extraction layers, affecting subsequent classification. The findings with our metric are supported by the visual analysis of the t-SNE maps.
Adversarial Robustness Assessment of NeuroEvolution Approaches
Jul 12, 2022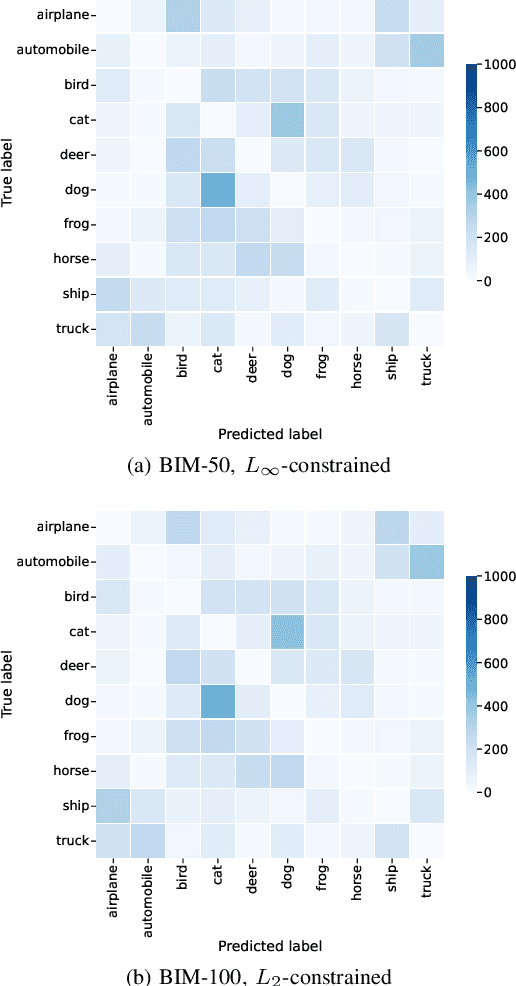
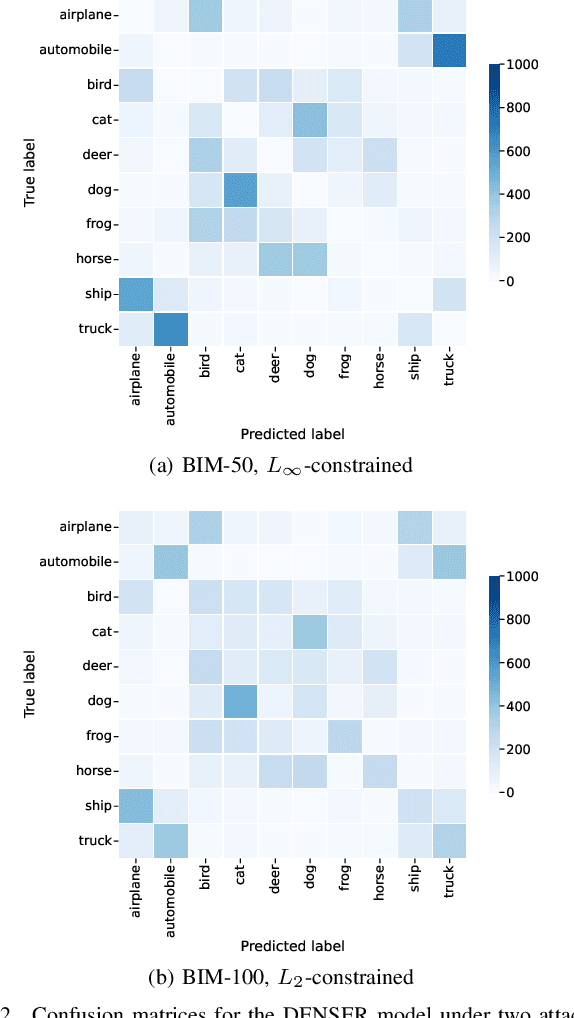
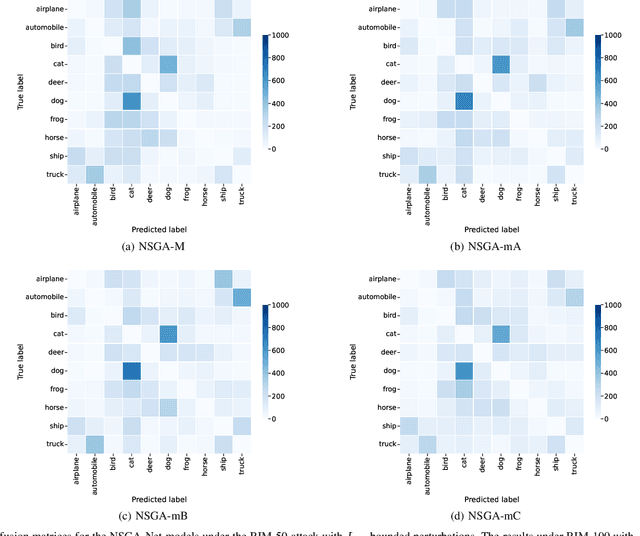
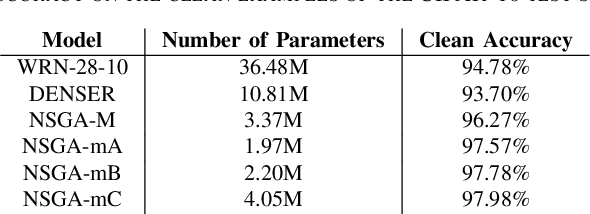
NeuroEvolution automates the generation of Artificial Neural Networks through the application of techniques from Evolutionary Computation. The main goal of these approaches is to build models that maximize predictive performance, sometimes with an additional objective of minimizing computational complexity. Although the evolved models achieve competitive results performance-wise, their robustness to adversarial examples, which becomes a concern in security-critical scenarios, has received limited attention. In this paper, we evaluate the adversarial robustness of models found by two prominent NeuroEvolution approaches on the CIFAR-10 image classification task: DENSER and NSGA-Net. Since the models are publicly available, we consider white-box untargeted attacks, where the perturbations are bounded by either the L2 or the Linfinity-norm. Similarly to manually-designed networks, our results show that when the evolved models are attacked with iterative methods, their accuracy usually drops to, or close to, zero under both distance metrics. The DENSER model is an exception to this trend, showing some resistance under the L2 threat model, where its accuracy only drops from 93.70% to 18.10% even with iterative attacks. Additionally, we analyzed the impact of pre-processing applied to the data before the first layer of the network. Our observations suggest that some of these techniques can exacerbate the perturbations added to the original inputs, potentially harming robustness. Thus, this choice should not be neglected when automatically designing networks for applications where adversarial attacks are prone to occur.
The Impact of Data Preparation on the Fairness of Software Systems
Oct 05, 2019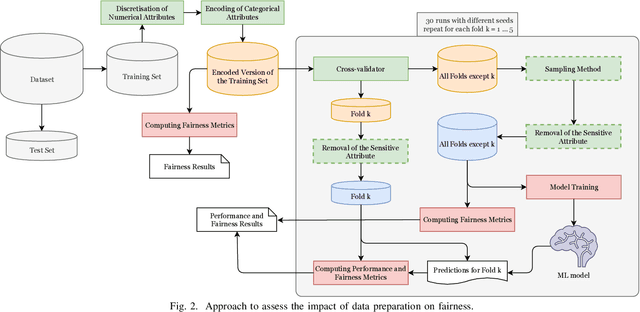
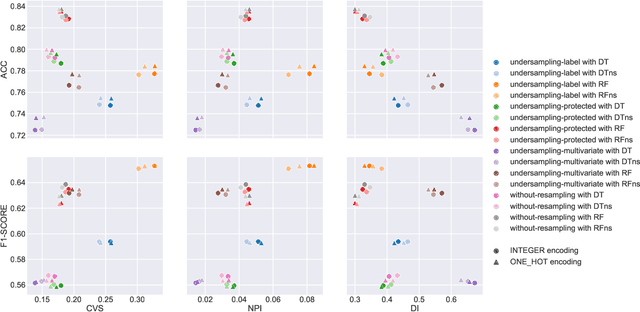
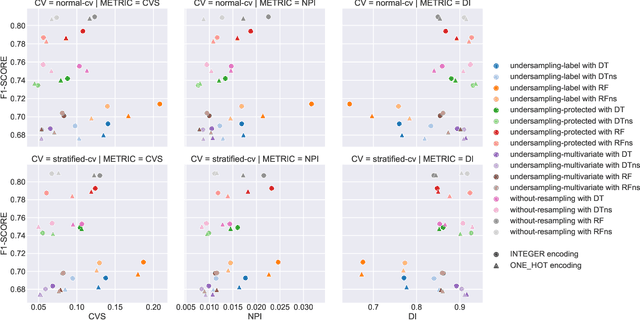
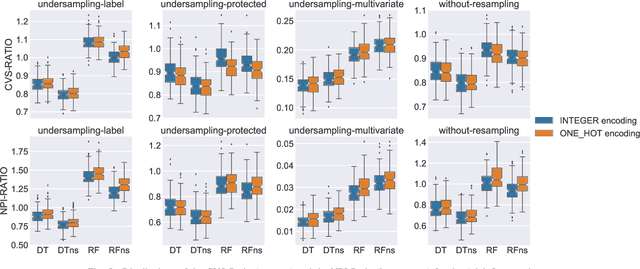
Machine learning models are widely adopted in scenarios that directly affect people. The development of software systems based on these models raises societal and legal concerns, as their decisions may lead to the unfair treatment of individuals based on attributes like race or gender. Data preparation is key in any machine learning pipeline, but its effect on fairness is yet to be studied in detail. In this paper, we evaluate how the fairness and effectiveness of the learned models are affected by the removal of the sensitive attribute, the encoding of the categorical attributes, and instance selection methods (including cross-validators and random undersampling). We used the Adult Income and the German Credit Data datasets, which are widely studied and known to have fairness concerns. We applied each data preparation technique individually to analyse the difference in predictive performance and fairness, using statistical parity difference, disparate impact, and the normalised prejudice index. The results show that fairness is affected by transformations made to the training data, particularly in imbalanced datasets. Removing the sensitive attribute is insufficient to eliminate all the unfairness in the predictions, as expected, but it is key to achieve fairer models. Additionally, the standard random undersampling with respect to the true labels is sometimes more prejudicial than performing no random undersampling.