 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePLOT: Pseudo-Labeling via Video Object Tracking for Scalable Monocular 3D Object Detection
Jul 03, 2025Monocular 3D object detection (M3OD) has long faced challenges due to data scarcity caused by high annotation costs and inherent 2D-to-3D ambiguity. Although various weakly supervised methods and pseudo-labeling methods have been proposed to address these issues, they are mostly limited by domain-specific learning or rely solely on shape information from a single observation. In this paper, we propose a novel pseudo-labeling framework that uses only video data and is more robust to occlusion, without requiring a multi-view setup, additional sensors, camera poses, or domain-specific training. Specifically, we explore a technique for aggregating the pseudo-LiDARs of both static and dynamic objects across temporally adjacent frames using object point tracking, enabling 3D attribute extraction in scenarios where 3D data acquisition is infeasible. Extensive experiments demonstrate that our method ensures reliable accuracy and strong scalability, making it a practical and effective solution for M3OD.
ORC: Network Group-based Knowledge Distillation using Online Role Change
Jun 01, 2022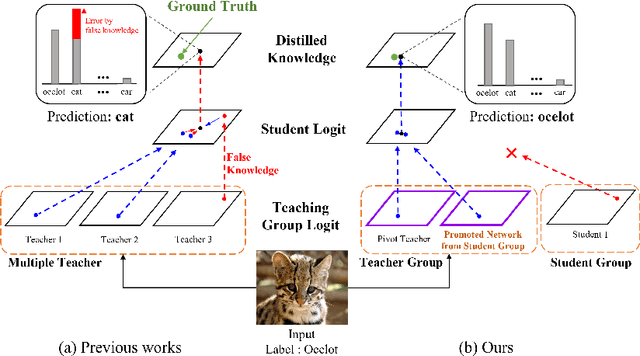
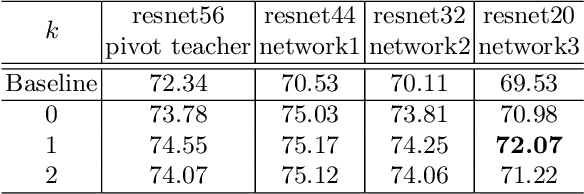
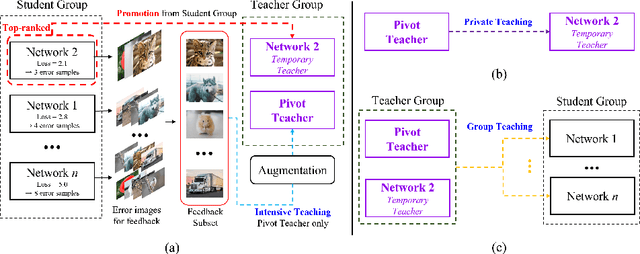
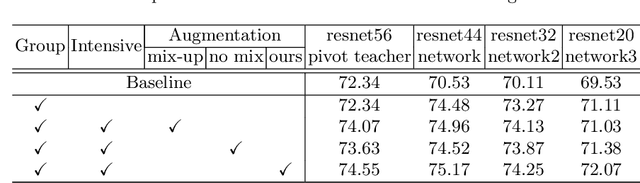
In knowledge distillation, since a single, omnipotent teacher network cannot solve all problems, multiple teacher-based knowledge distillations have been studied recently. However, sometimes their improvements are not as good as expected because some immature teachers may transfer the false knowledge to the student. In this paper, to overcome this limitation and take the efficacy of the multiple networks, we divide the multiple networks into teacher and student groups, respectively. That is, the student group is a set of immature networks that require learning the teacher's knowledge, while the teacher group consists of the selected networks that have performed well. Furthermore, according to our online role change strategy, the top-ranked networks in the student group are able to promote to the teacher group at every iteration and vice versa. After training the teacher group using the error images of the student group to refine the teacher group's knowledge, we transfer the collective knowledge from the teacher group to the student group successfully. We verify the superiority of the proposed method on CIFAR-10 and CIFAR-100, which achieves high performance. We further show the generality of our method with various backbone architectures such as resent, wrn, vgg, mobilenet, and shufflenet.
itKD: Interchange Transfer-based Knowledge Distillation for 3D Object Detection
May 31, 2022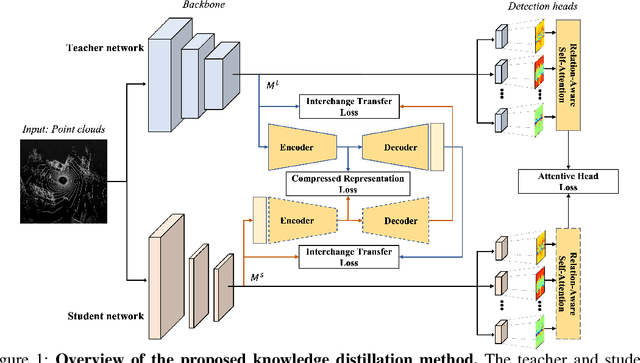
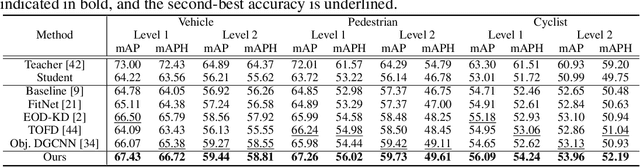
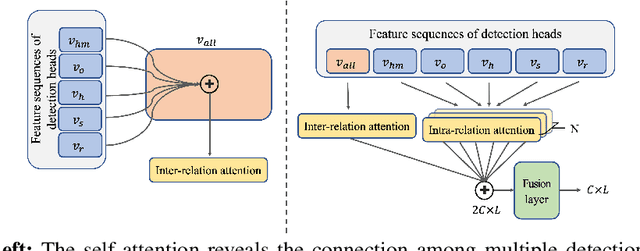
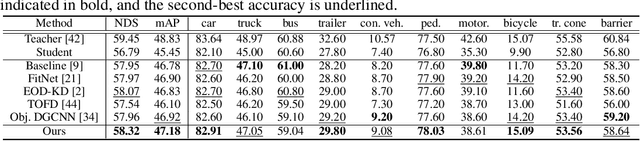
Recently, point-cloud based 3D object detectors have achieved remarkable progress. However, most studies are limited to the development of deep learning architectures for improving only their accuracy. In this paper, we propose an autoencoder-style framework comprising channel-wise compression and decompression via interchange transfer for knowledge distillation. To learn the map-view feature of a teacher network, the features from a teacher and student network are independently passed through the shared autoencoder; here, we use a compressed representation loss that binds the channel-wised compression knowledge from both the networks as a kind of regularization. The decompressed features are transferred in opposite directions to reduce the gap in the interchange reconstructions. Lastly, we present an attentive head loss for matching the pivotal detection information drawn by the multi-head self-attention mechanism. Through extensive experiments, we verify that our method can learn the lightweight model that is well-aligned with the 3D point cloud detection task and we demonstrate its superiority using the well-known public datasets Waymo and nuScenes.