 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeitKD: Interchange Transfer-based Knowledge Distillation for 3D Object Detection
Paper and Code
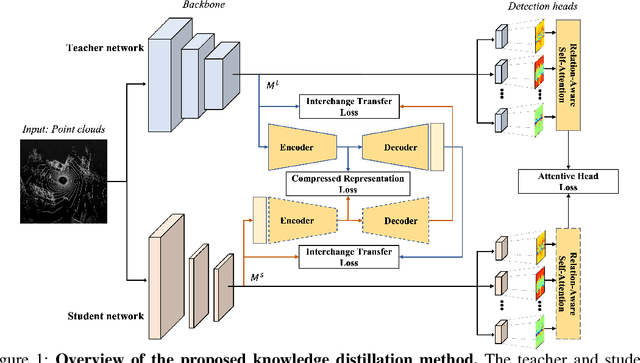
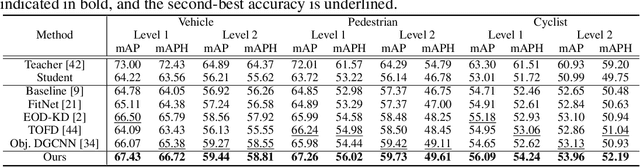
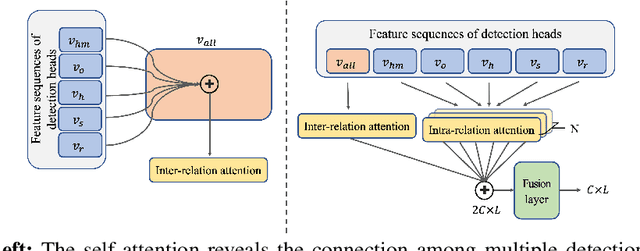
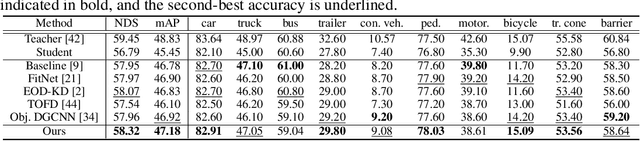
Recently, point-cloud based 3D object detectors have achieved remarkable progress. However, most studies are limited to the development of deep learning architectures for improving only their accuracy. In this paper, we propose an autoencoder-style framework comprising channel-wise compression and decompression via interchange transfer for knowledge distillation. To learn the map-view feature of a teacher network, the features from a teacher and student network are independently passed through the shared autoencoder; here, we use a compressed representation loss that binds the channel-wised compression knowledge from both the networks as a kind of regularization. The decompressed features are transferred in opposite directions to reduce the gap in the interchange reconstructions. Lastly, we present an attentive head loss for matching the pivotal detection information drawn by the multi-head self-attention mechanism. Through extensive experiments, we verify that our method can learn the lightweight model that is well-aligned with the 3D point cloud detection task and we demonstrate its superiority using the well-known public datasets Waymo and nuScenes.