 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeORC: Network Group-based Knowledge Distillation using Online Role Change
Jun 01, 2022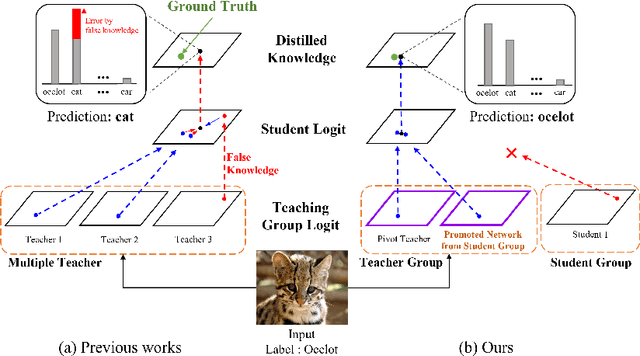
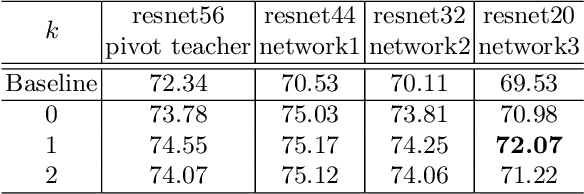
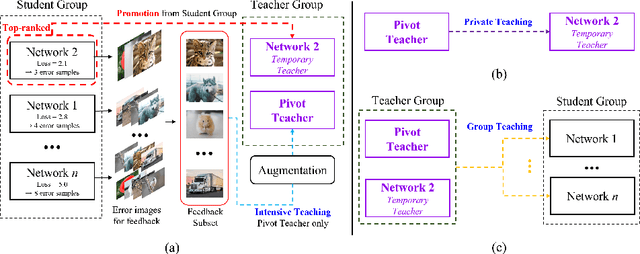
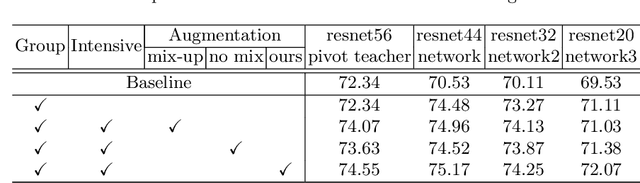
In knowledge distillation, since a single, omnipotent teacher network cannot solve all problems, multiple teacher-based knowledge distillations have been studied recently. However, sometimes their improvements are not as good as expected because some immature teachers may transfer the false knowledge to the student. In this paper, to overcome this limitation and take the efficacy of the multiple networks, we divide the multiple networks into teacher and student groups, respectively. That is, the student group is a set of immature networks that require learning the teacher's knowledge, while the teacher group consists of the selected networks that have performed well. Furthermore, according to our online role change strategy, the top-ranked networks in the student group are able to promote to the teacher group at every iteration and vice versa. After training the teacher group using the error images of the student group to refine the teacher group's knowledge, we transfer the collective knowledge from the teacher group to the student group successfully. We verify the superiority of the proposed method on CIFAR-10 and CIFAR-100, which achieves high performance. We further show the generality of our method with various backbone architectures such as resent, wrn, vgg, mobilenet, and shufflenet.