 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHuman-Centered Development of Guide Dog Robots: Quiet and Stable Locomotion Control
May 17, 2025
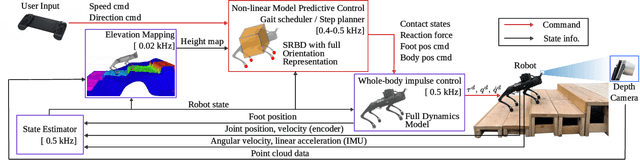
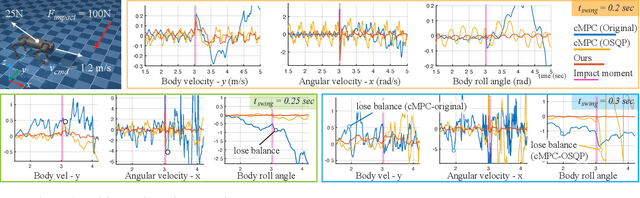
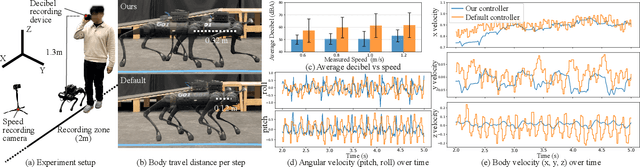
A quadruped robot is a promising system that can offer assistance comparable to that of dog guides due to its similar form factor. However, various challenges remain in making these robots a reliable option for blind and low-vision (BLV) individuals. Among these challenges, noise and jerky motion during walking are critical drawbacks of existing quadruped robots. While these issues have largely been overlooked in guide dog robot research, our interviews with guide dog handlers and trainers revealed that acoustic and physical disturbances can be particularly disruptive for BLV individuals, who rely heavily on environmental sounds for navigation. To address these issues, we developed a novel walking controller for slow stepping and smooth foot swing/contact while maintaining human walking speed, as well as robust and stable balance control. The controller integrates with a perception system to facilitate locomotion over non-flat terrains, such as stairs. Our controller was extensively tested on the Unitree Go1 robot and, when compared with other control methods, demonstrated significant noise reduction -- half of the default locomotion controller. In this study, we adopt a mixed-methods approach to evaluate its usability with BLV individuals. In our indoor walking experiments, participants compared our controller to the robot's default controller. Results demonstrated superior acceptance of our controller, highlighting its potential to improve the user experience of guide dog robots. Video demonstration (best viewed with audio) available at: https://youtu.be/8-pz_8Hqe6s.
Lessons Learned from Developing a Human-Centered Guide Dog Robot for Mobility Assistance
Sep 29, 2024


While guide dogs offer essential mobility assistance, their high cost, limited availability, and care requirements make them inaccessible to most blind or low vision (BLV) individuals. Recent advances in quadruped robots provide a scalable solution for mobility assistance, but many current designs fail to meet real-world needs due to a lack of understanding of handler and guide dog interactions. In this paper, we share lessons learned from developing a human-centered guide dog robot, addressing challenges such as optimal hardware design, robust navigation, and informative scene description for user adoption. By conducting semi-structured interviews and human experiments with BLV individuals, guide-dog handlers, and trainers, we identified key design principles to improve safety, trust, and usability in robotic mobility aids. Our findings lay the building blocks for future development of guide dog robots, ultimately enhancing independence and quality of life for BLV individuals.
Synthetic data augmentation for robotic mobility aids to support blind and low vision people
Sep 17, 2024Robotic mobility aids for blind and low-vision (BLV) individuals rely heavily on deep learning-based vision models specialized for various navigational tasks. However, the performance of these models is often constrained by the availability and diversity of real-world datasets, which are challenging to collect in sufficient quantities for different tasks. In this study, we investigate the effectiveness of synthetic data, generated using Unreal Engine 4, for training robust vision models for this safety-critical application. Our findings demonstrate that synthetic data can enhance model performance across multiple tasks, showcasing both its potential and its limitations when compared to real-world data. We offer valuable insights into optimizing synthetic data generation for developing robotic mobility aids. Additionally, we publicly release our generated synthetic dataset to support ongoing research in assistive technologies for BLV individuals, available at https://hchlhwang.github.io/SToP.
Towards Robotic Companions: Understanding Handler-Guide Dog Interactions for Informed Guide Dog Robot Design
Feb 09, 2024



Dog guides are favored by blind and low-vision (BLV) individuals for their ability to enhance independence and confidence by reducing safety concerns and increasing navigation efficiency compared to traditional mobility aids. However, only a relatively small proportion of BLV individuals work with dog guides due to their limited availability and associated maintenance responsibilities. There is considerable recent interest in addressing this challenge by developing legged guide dog robots. This study was designed to determine critical aspects of the handler-guide dog interaction and better understand handler needs to inform guide dog robot development. We conducted semi-structured interviews and observation sessions with 23 dog guide handlers and 5 trainers. Thematic analysis revealed critical limitations in guide dog work, desired personalization in handler-guide dog interaction, and important perspectives on future guide dog robots. Grounded on these findings, we discuss pivotal design insights for guide dog robots aimed for adoption within the BLV community.
Is it safe to cross? Interpretable Risk Assessment with GPT-4V for Safety-Aware Street Crossing
Feb 09, 2024



Safely navigating street intersections is a complex challenge for blind and low-vision individuals, as it requires a nuanced understanding of the surrounding context - a task heavily reliant on visual cues. Traditional methods for assisting in this decision-making process often fall short, lacking the ability to provide a comprehensive scene analysis and safety level. This paper introduces an innovative approach that leverages large multimodal models (LMMs) to interpret complex street crossing scenes, offering a potential advancement over conventional traffic signal recognition techniques. By generating a safety score and scene description in natural language, our method supports safe decision-making for the blind and low-vision individuals. We collected crosswalk intersection data that contains multiview egocentric images captured by a quadruped robot and annotated the images with corresponding safety scores based on our predefined safety score categorization. Grounded on the visual knowledge, extracted from images, and text prompt, we evaluate a large multimodal model for safety score prediction and scene description. Our findings highlight the reasoning and safety score prediction capabilities of a LMM, activated by various prompts, as a pathway to developing a trustworthy system, crucial for applications requiring reliable decision-making support.
System Configuration and Navigation of a Guide Dog Robot: Toward Animal Guide Dog-Level Guiding Work
Oct 24, 2022A robot guide dog has compelling advantages over animal guide dogs for its cost-effectiveness, potential for mass production, and low maintenance burden. However, despite the long history of guide dog robot research, previous studies were conducted with little or no consideration of how the guide dog handler and the guide dog work as a team for navigation. To develop a robotic guiding system that is genuinely beneficial to blind or visually impaired individuals, we performed qualitative research, including interviews with guide dog handlers and trainers and first-hand blindfold walking experiences with various guide dogs. Grounded on the facts learned from vivid experience and interviews, we build a collaborative indoor navigation scheme for a guide dog robot that includes preferred features such as speed and directional control. For collaborative navigation, we propose a semantic-aware local path planner that enables safe and efficient guiding work by utilizing semantic information about the environment and considering the handler's position and directional cues to determine the collision-free path. We evaluate our integrated robotic system by testing guide blindfold walking in indoor settings and demonstrate guide dog-like navigation behavior by avoiding obstacles at typical gait speed ($0.7 \mathrm{m/s}$).
ElderSim: A Synthetic Data Generation Platform for Human Action Recognition in Eldercare Applications
Oct 28, 2020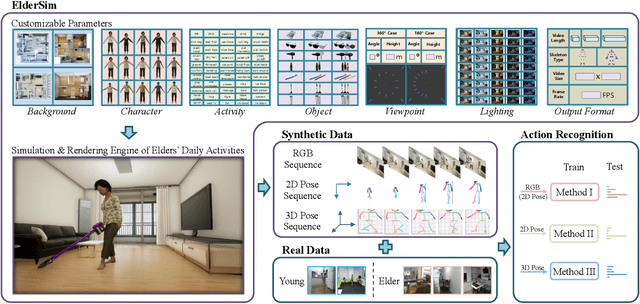
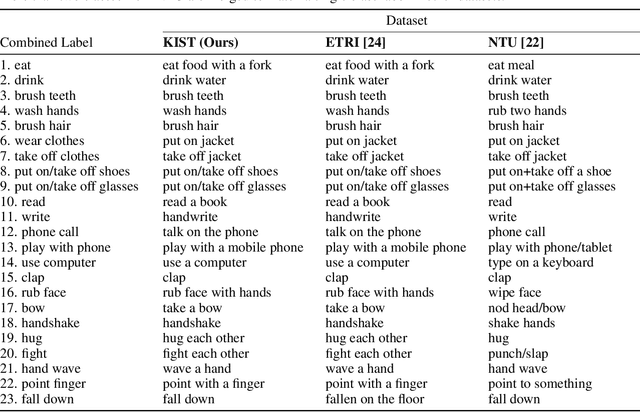
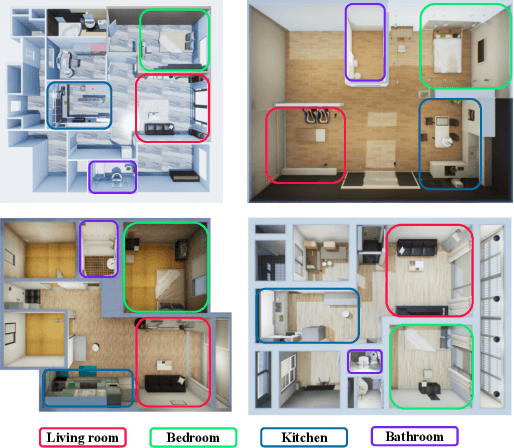

To train deep learning models for vision-based action recognition of elders' daily activities, we need large-scale activity datasets acquired under various daily living environments and conditions. However, most public datasets used in human action recognition either differ from or have limited coverage of elders' activities in many aspects, making it challenging to recognize elders' daily activities well by only utilizing existing datasets. Recently, such limitations of available datasets have actively been compensated by generating synthetic data from realistic simulation environments and using those data to train deep learning models. In this paper, based on these ideas we develop ElderSim, an action simulation platform that can generate synthetic data on elders' daily activities. For 55 kinds of frequent daily activities of the elders, ElderSim generates realistic motions of synthetic characters with various adjustable data-generating options, and provides different output modalities including RGB videos, two- and three-dimensional skeleton trajectories. We then generate KIST SynADL, a large-scale synthetic dataset of elders' activities of daily living, from ElderSim and use the data in addition to real datasets to train three state-of the-art human action recognition models. From the experiments following several newly proposed scenarios that assume different real and synthetic dataset configurations for training, we observe a noticeable performance improvement by augmenting our synthetic data. We also offer guidance with insights for the effective utilization of synthetic data to help recognize elders' daily activities.
Computationally-Robust and Efficient Prioritized Whole-Body Controller with Contact Constraints
Jul 03, 2018
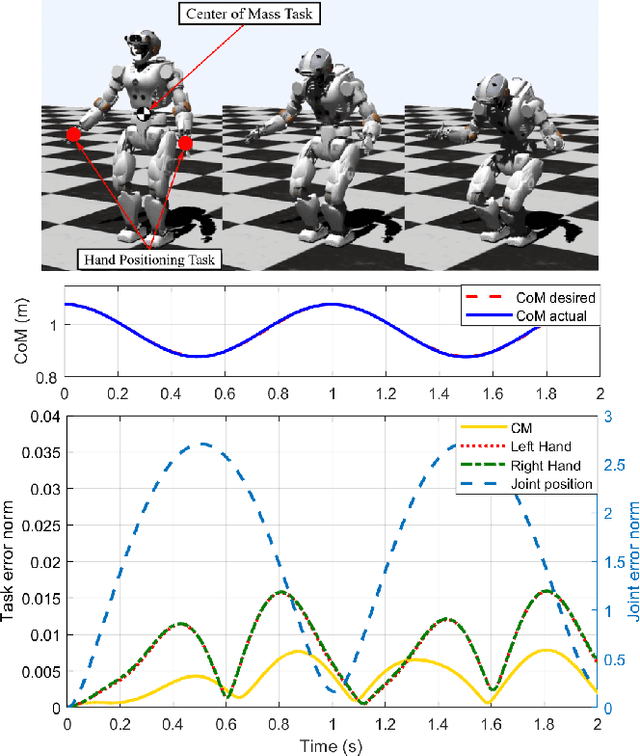

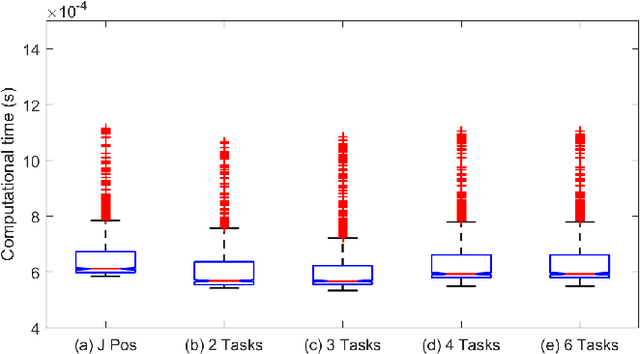
In this paper, we devise methods for the multi- objective control of humanoid robots, a.k.a. prioritized whole- body controllers, that achieve efficiency and robustness in the algorithmic computations. We use a form of whole-body controllers that is very general via incorporating centroidal momentum dynamics, operational task priorities, contact re- action forces, and internal force constraints. First, we achieve efficiency by solving a quadratic program that only involves the floating base dynamics and the reaction forces. Second, we achieve computational robustness by relaxing task accelerations such that they comply with friction cone constraints. Finally, we incorporate methods for smooth contact transitions to enhance the control of dynamic locomotion behaviors. The proposed methods are demonstrated both in simulation and in real experiments using a passive-ankle bipedal robot.