 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGRAM: Fast Fine-tuning of Pre-trained Language Models for Content-based Collaborative Filtering
Paper and Code

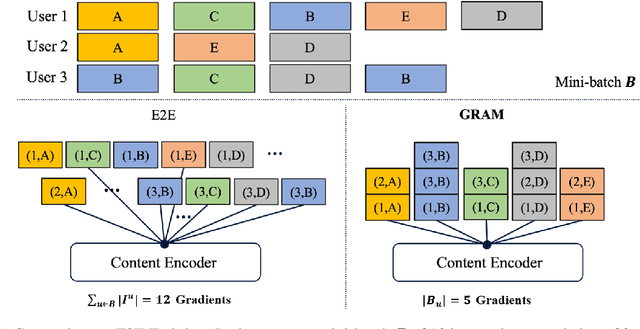
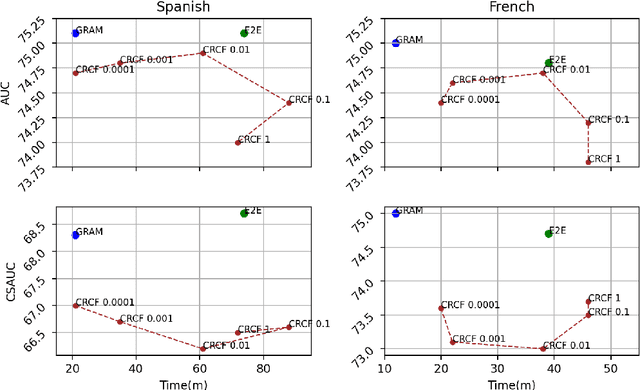
Content-based collaborative filtering (CCF) provides personalized item recommendations based on both users' interaction history and items' content information. Recently, pre-trained language models (PLM) have been used to extract high-quality item encodings for CCF. However, it is resource-intensive to finetune PLM in an end-to-end (E2E) manner in CCF due to its multi-modal nature: optimization involves redundant content encoding for interactions from users. For this, we propose GRAM (GRadient Accumulation for Multi-modality): (1) Single-step GRAM which aggregates gradients for each item while maintaining theoretical equivalence with E2E, and (2) Multi-step GRAM which further accumulates gradients across multiple training steps, with less than 40\% GPU memory footprint of E2E. We empirically confirm that GRAM achieves a remarkable boost in training efficiency based on five datasets from two task domains of Knowledge Tracing and News Recommendation, where single-step and multi-step GRAM achieve 4x and 45x training speedup on average, respectively.