 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContext-Aware Input Orchestration for Video Inpainting
Nov 25, 2024

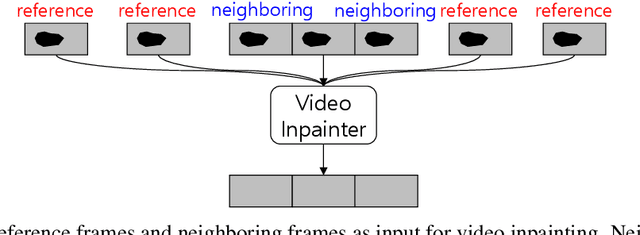

Traditional neural network-driven inpainting methods struggle to deliver high-quality results within the constraints of mobile device processing power and memory. Our research introduces an innovative approach to optimize memory usage by altering the composition of input data. Typically, video inpainting relies on a predetermined set of input frames, such as neighboring and reference frames, often limited to five-frame sets. Our focus is to examine how varying the proportion of these input frames impacts the quality of the inpainted video. By dynamically adjusting the input frame composition based on optical flow and changes of the mask, we have observed an improvement in various contents including rapid visual context changes.
MINSU (Mobile Inventory And Scanning Unit):Computer Vision and AI
Apr 14, 2022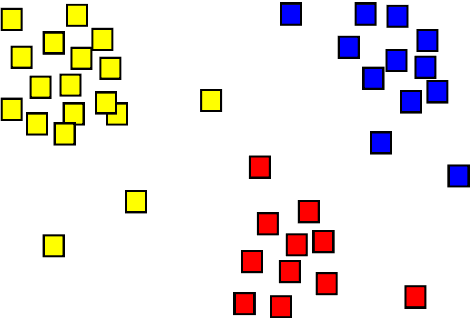
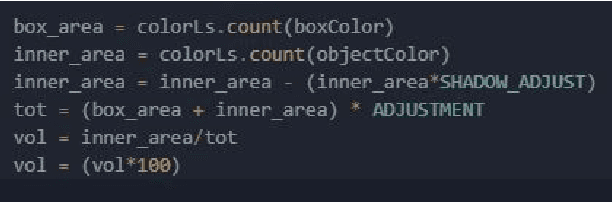


The MINSU(Mobile Inventory and Scanning Unit) algorithm uses the computational vision analysis method to record the residual quantity/fullness of the cabinet. To do so, it goes through a five-step method: object detection, foreground subtraction, K-means clustering, percentage estimation, and counting. The input image goes through the object detection method to analyze the specific position of the cabinets in terms of coordinates. After doing so, it goes through the foreground subtraction method to make the image more focus-able to the cabinet itself by removing the background (some manual work may have to be done such as selecting the parts that were not grab cut by the algorithm). In the K-means clustering method, the multi-colored image turns into a 3 colored monotonous image for quicker and more accurate analysis. At last, the image goes through percentage estimation and counting. In these two methods, the proportion that the material inside the cabinet is found in percentage which then is used to approximate the number of materials inside. Had this project been successful, the residual quantity management could solve the problem addressed earlier in the introduction.
Residual Quantity in Percentage of Factory Machines Using ComputerVision and Mathematical Methods
Nov 09, 2021
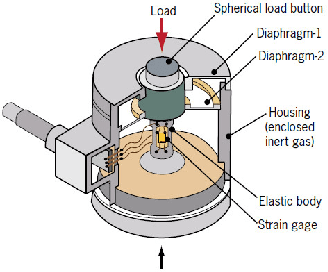

Computer vision has been thriving since AI development was gaining thrust. Using deep learning techniques has been the most popular way which computer scientists thought the solution of. However, deep learning techniques tend to show lower performance than manual processing. Using deep learning is not always the answer to a problem related to computer vision.