Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContext-Aware Input Orchestration for Video Inpainting
Nov 25, 2024

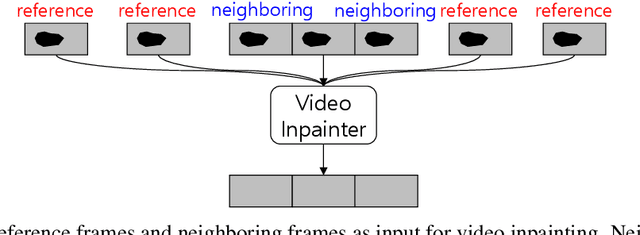

Traditional neural network-driven inpainting methods struggle to deliver high-quality results within the constraints of mobile device processing power and memory. Our research introduces an innovative approach to optimize memory usage by altering the composition of input data. Typically, video inpainting relies on a predetermined set of input frames, such as neighboring and reference frames, often limited to five-frame sets. Our focus is to examine how varying the proportion of these input frames impacts the quality of the inpainted video. By dynamically adjusting the input frame composition based on optical flow and changes of the mask, we have observed an improvement in various contents including rapid visual context changes.
Via