 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePseudo-Labeling Curriculum for Unsupervised Domain Adaptation
Paper and Code
Aug 01, 2019
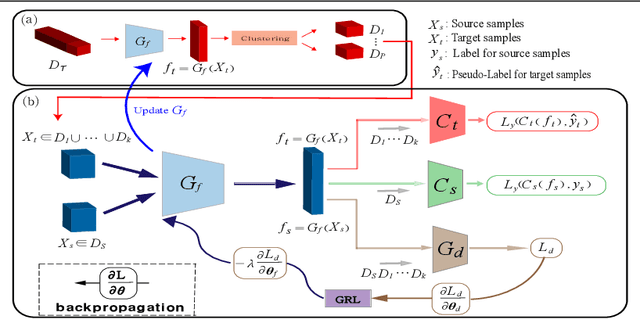

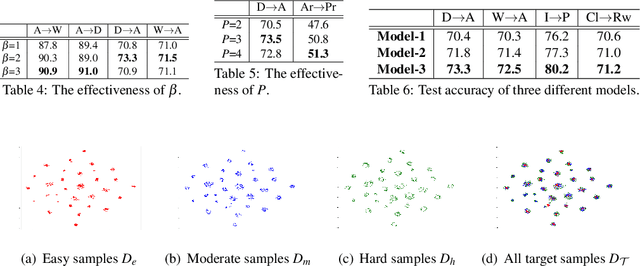
To learn target discriminative representations, using pseudo-labels is a simple yet effective approach for unsupervised domain adaptation. However, the existence of false pseudo-labels, which may have a detrimental influence on learning target representations, remains a major challenge. To overcome this issue, we propose a pseudo-labeling curriculum based on a density-based clustering algorithm. Since samples with high density values are more likely to have correct pseudo-labels, we leverage these subsets to train our target network at the early stage, and utilize data subsets with low density values at the later stage. We can progressively improve the capability of our network to generate pseudo-labels, and thus these target samples with pseudo-labels are effective for training our model. Moreover, we present a clustering constraint to enhance the discriminative power of the learned target features. Our approach achieves state-of-the-art performance on three benchmarks: Office-31, imageCLEF-DA, and Office-Home.