 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Skills, Brittle Grounding: Diagnosing Restricted Generalization in Vision-Language Action Policies via Multi-Object Picking
Feb 27, 2026Vision-language action (VLA) policies often report strong manipulation benchmark performance with relatively few demonstrations, but it remains unclear whether this reflects robust language-to-object grounding or reliance on object--location correlations that do not transfer beyond the training distribution. We present a controlled multi-object picking study that progressively increases object placement variability up to full workspace randomization and evaluates held-out object--location pairings that break familiar associations without increasing spatial difficulty. Across these stress tests and data scaling, we find that for representative VLA policies, including SmolVLA and $π_{0.5}$, execution of the manipulation primitive remains substantially more reliable than instruction-conditioned task success in harder regimes, suggesting that manipulation skill acquisition is decoupled from instruction following. We recommend augmenting manipulation benchmarks with task ladders and decomposed metrics that separately measure primitive execution and instruction-conditioned success to better diagnose instruction-grounded generalization.
Disentangled Object-Centric Image Representation for Robotic Manipulation
Mar 14, 2025Learning robotic manipulation skills from vision is a promising approach for developing robotics applications that can generalize broadly to real-world scenarios. As such, many approaches to enable this vision have been explored with fruitful results. Particularly, object-centric representation methods have been shown to provide better inductive biases for skill learning, leading to improved performance and generalization. Nonetheless, we show that object-centric methods can struggle to learn simple manipulation skills in multi-object environments. Thus, we propose DOCIR, an object-centric framework that introduces a disentangled representation for objects of interest, obstacles, and robot embodiment. We show that this approach leads to state-of-the-art performance for learning pick and place skills from visual inputs in multi-object environments and generalizes at test time to changing objects of interest and distractors in the scene. Furthermore, we show its efficacy both in simulation and zero-shot transfer to the real world.
SLIM: Skill Learning with Multiple Critics
Feb 01, 2024Self-supervised skill learning aims to acquire useful behaviors that leverage the underlying dynamics of the environment. Latent variable models, based on mutual information maximization, have been particularly successful in this task but still struggle in the context of robotic manipulation. As it requires impacting a possibly large set of degrees of freedom composing the environment, mutual information maximization fails alone in producing useful manipulation behaviors. To address this limitation, we introduce SLIM, a multi-critic learning approach for skill discovery with a particular focus on robotic manipulation. Our main insight is that utilizing multiple critics in an actor-critic framework to gracefully combine multiple reward functions leads to a significant improvement in latent-variable skill discovery for robotic manipulation while overcoming possible interference occurring among rewards which hinders convergence to useful skills. Furthermore, in the context of tabletop manipulation, we demonstrate the applicability of our novel skill discovery approach to acquire safe and efficient motor primitives in a hierarchical reinforcement learning fashion and leverage them through planning, surpassing the state-of-the-art approaches for skill discovery by a large margin.
Successor Feature Neural Episodic Control
Nov 04, 2021

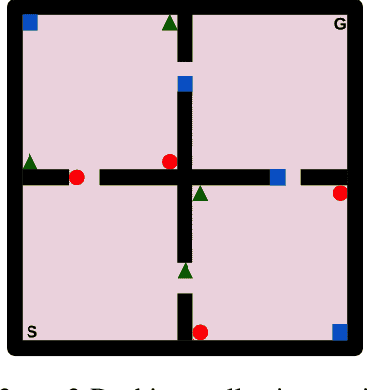
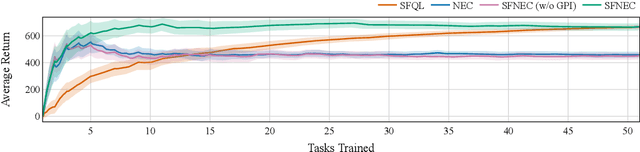
A longstanding goal in reinforcement learning is to build intelligent agents that show fast learning and a flexible transfer of skills akin to humans and animals. This paper investigates the integration of two frameworks for tackling those goals: episodic control and successor features. Episodic control is a cognitively inspired approach relying on episodic memory, an instance-based memory model of an agent's experiences. Meanwhile, successor features and generalized policy improvement (SF&GPI) is a meta and transfer learning framework allowing to learn policies for tasks that can be efficiently reused for later tasks which have a different reward function. Individually, these two techniques have shown impressive results in vastly improving sample efficiency and the elegant reuse of previously learned policies. Thus, we outline a combination of both approaches in a single reinforcement learning framework and empirically illustrate its benefits.