 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Semi-Supervised Learning via Representative and Diverse Sample Selection
Sep 18, 2024Semi-Supervised Learning (SSL) has become a preferred paradigm in many deep learning tasks, which reduces the need for human labor. Previous studies primarily focus on effectively utilising the labelled and unlabeled data to improve performance. However, we observe that how to select samples for labelling also significantly impacts performance, particularly under extremely low-budget settings. The sample selection task in SSL has been under-explored for a long time. To fill in this gap, we propose a Representative and Diverse Sample Selection approach (RDSS). By adopting a modified Frank-Wolfe algorithm to minimise a novel criterion $\alpha$-Maximum Mean Discrepancy ($\alpha$-MMD), RDSS samples a representative and diverse subset for annotation from the unlabeled data. We demonstrate that minimizing $\alpha$-MMD enhances the generalization ability of low-budget learning. Experimental results show that RDSS consistently improves the performance of several popular SSL frameworks and outperforms the state-of-the-art sample selection approaches used in Active Learning (AL) and Semi-Supervised Active Learning (SSAL), even with constrained annotation budgets.
A Course Shared Task on Evaluating LLM Output for Clinical Questions
Jul 31, 2024


This paper presents a shared task that we organized at the Foundations of Language Technology (FoLT) course in 2023/2024 at the Technical University of Darmstadt, which focuses on evaluating the output of Large Language Models (LLMs) in generating harmful answers to health-related clinical questions. We describe the task design considerations and report the feedback we received from the students. We expect the task and the findings reported in this paper to be relevant for instructors teaching natural language processing (NLP) and designing course assignments.
Spatial-Semantic Collaborative Cropping for User Generated Content
Jan 16, 2024A large amount of User Generated Content (UGC) is uploaded to the Internet daily and displayed to people world-widely through the client side (e.g., mobile and PC). This requires the cropping algorithms to produce the aesthetic thumbnail within a specific aspect ratio on different devices. However, existing image cropping works mainly focus on landmark or landscape images, which fail to model the relations among the multi-objects with the complex background in UGC. Besides, previous methods merely consider the aesthetics of the cropped images while ignoring the content integrity, which is crucial for UGC cropping. In this paper, we propose a Spatial-Semantic Collaborative cropping network (S2CNet) for arbitrary user generated content accompanied by a new cropping benchmark. Specifically, we first mine the visual genes of the potential objects. Then, the suggested adaptive attention graph recasts this task as a procedure of information association over visual nodes. The underlying spatial and semantic relations are ultimately centralized to the crop candidate through differentiable message passing, which helps our network efficiently to preserve both the aesthetics and the content integrity. Extensive experiments on the proposed UGCrop5K and other public datasets demonstrate the superiority of our approach over state-of-the-art counterparts. Our project is available at https://github.com/suyukun666/S2CNet.
Semantic-Constraint Matching Transformer for Weakly Supervised Object Localization
Sep 04, 2023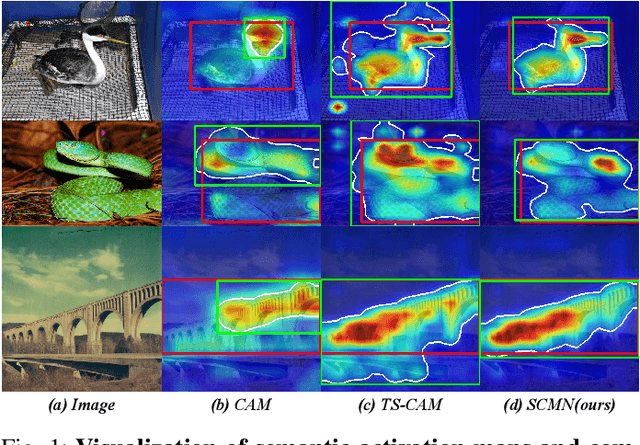

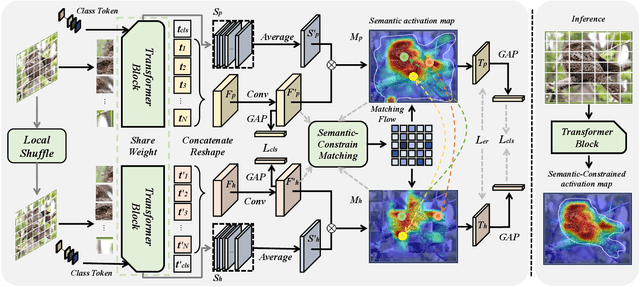
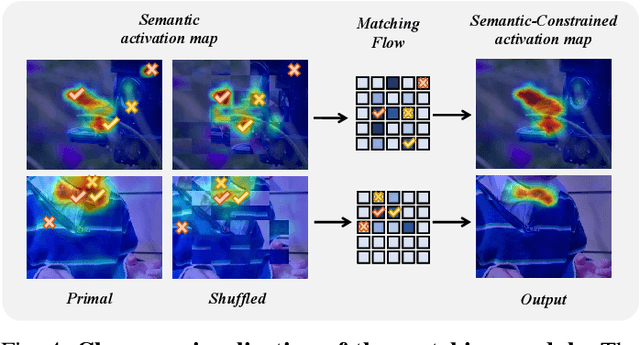
Weakly supervised object localization (WSOL) strives to learn to localize objects with only image-level supervision. Due to the local receptive fields generated by convolution operations, previous CNN-based methods suffer from partial activation issues, concentrating on the object's discriminative part instead of the entire entity scope. Benefiting from the capability of the self-attention mechanism to acquire long-range feature dependencies, Vision Transformer has been recently applied to alleviate the local activation drawbacks. However, since the transformer lacks the inductive localization bias that are inherent in CNNs, it may cause a divergent activation problem resulting in an uncertain distinction between foreground and background. In this work, we proposed a novel Semantic-Constraint Matching Network (SCMN) via a transformer to converge on the divergent activation. Specifically, we first propose a local patch shuffle strategy to construct the image pairs, disrupting local patches while guaranteeing global consistency. The paired images that contain the common object in spatial are then fed into the Siamese network encoder. We further design a semantic-constraint matching module, which aims to mine the co-object part by matching the coarse class activation maps (CAMs) extracted from the pair images, thus implicitly guiding and calibrating the transformer network to alleviate the divergent activation. Extensive experimental results conducted on two challenging benchmarks, including CUB-200-2011 and ILSVRC datasets show that our method can achieve the new state-of-the-art performance and outperform the previous method by a large margin.