 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoNav: A Benchmark for Human-Centered Collaborative Navigation
Jun 04, 2024Human-robot collaboration, in which the robot intelligently assists the human with the upcoming task, is an appealing objective. To achieve this goal, the agent needs to be equipped with a fundamental collaborative navigation ability, where the agent should reason human intention by observing human activities and then navigate to the human's intended destination in advance of the human. However, this vital ability has not been well studied in previous literature. To fill this gap, we propose a collaborative navigation (CoNav) benchmark. Our CoNav tackles the critical challenge of constructing a 3D navigation environment with realistic and diverse human activities. To achieve this, we design a novel LLM-based humanoid animation generation framework, which is conditioned on both text descriptions and environmental context. The generated humanoid trajectory obeys the environmental context and can be easily integrated into popular simulators. We empirically find that the existing navigation methods struggle in CoNav task since they neglect the perception of human intention. To solve this problem, we propose an intention-aware agent for reasoning both long-term and short-term human intention. The agent predicts navigation action based on the predicted intention and panoramic observation. The emergent agent behavior including observing humans, avoiding human collision, and navigation reveals the efficiency of the proposed datasets and agents.
Semantic-Constraint Matching Transformer for Weakly Supervised Object Localization
Sep 04, 2023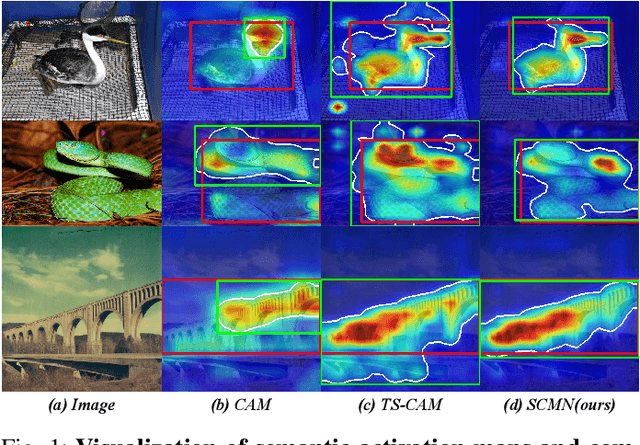

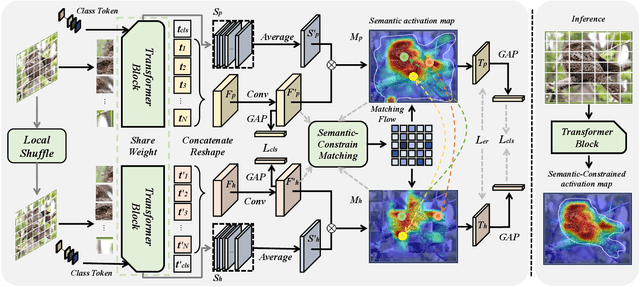
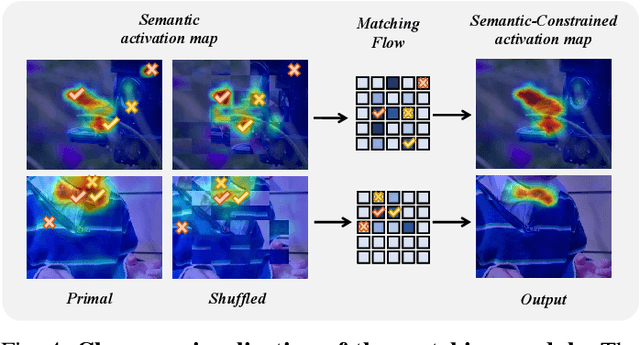
Weakly supervised object localization (WSOL) strives to learn to localize objects with only image-level supervision. Due to the local receptive fields generated by convolution operations, previous CNN-based methods suffer from partial activation issues, concentrating on the object's discriminative part instead of the entire entity scope. Benefiting from the capability of the self-attention mechanism to acquire long-range feature dependencies, Vision Transformer has been recently applied to alleviate the local activation drawbacks. However, since the transformer lacks the inductive localization bias that are inherent in CNNs, it may cause a divergent activation problem resulting in an uncertain distinction between foreground and background. In this work, we proposed a novel Semantic-Constraint Matching Network (SCMN) via a transformer to converge on the divergent activation. Specifically, we first propose a local patch shuffle strategy to construct the image pairs, disrupting local patches while guaranteeing global consistency. The paired images that contain the common object in spatial are then fed into the Siamese network encoder. We further design a semantic-constraint matching module, which aims to mine the co-object part by matching the coarse class activation maps (CAMs) extracted from the pair images, thus implicitly guiding and calibrating the transformer network to alleviate the divergent activation. Extensive experimental results conducted on two challenging benchmarks, including CUB-200-2011 and ILSVRC datasets show that our method can achieve the new state-of-the-art performance and outperform the previous method by a large margin.
Imbalance-Agnostic Source-Free Domain Adaptation via Avatar Prototype Alignment
May 22, 2023



Source-free Unsupervised Domain Adaptation (SF-UDA) aims to adapt a well-trained source model to an unlabeled target domain without access to the source data. One key challenge is the lack of source data during domain adaptation. To handle this, we propose to mine the hidden knowledge of the source model and exploit it to generate source avatar prototypes. To this end, we propose a Contrastive Prototype Generation and Adaptation (CPGA) method. CPGA consists of two stages: Prototype generation and Prototype adaptation. Extensive experiments on three UDA benchmark datasets demonstrate the superiority of CPGA. However, existing SF.UDA studies implicitly assume balanced class distributions for both the source and target domains, which hinders their real applications. To address this issue, we study a more practical SF-UDA task, termed imbalance-agnostic SF-UDA, where the class distributions of both the unseen source domain and unlabeled target domain are unknown and could be arbitrarily skewed. This task is much more challenging than vanilla SF-UDA due to the co-occurrence of covariate shifts and unidentified class distribution shifts between the source and target domains. To address this task, we extend CPGA and propose a new Target-aware Contrastive Prototype Generation and Adaptation (T-CPGA) method. Specifically, for better prototype adaptation in the imbalance-agnostic scenario, T-CPGA applies a new pseudo label generation strategy to identify unknown target class distribution and generate accurate pseudo labels, by utilizing the collective intelligence of the source model and an additional contrastive language-image pre-trained model. Meanwhile, we further devise a target label-distribution-aware classifier to adapt the model to the unknown target class distribution. We empirically show that T-CPGA significantly outperforms CPGA and other SF-UDA methods in imbalance-agnostic SF-UDA.
Prototype-Guided Continual Adaptation for Class-Incremental Unsupervised Domain Adaptation
Jul 29, 2022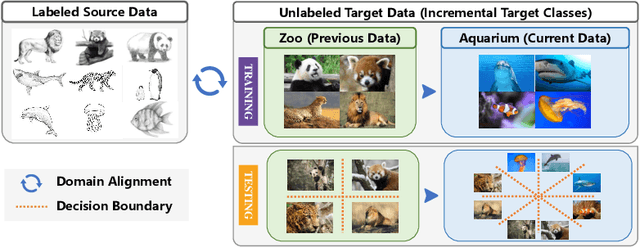

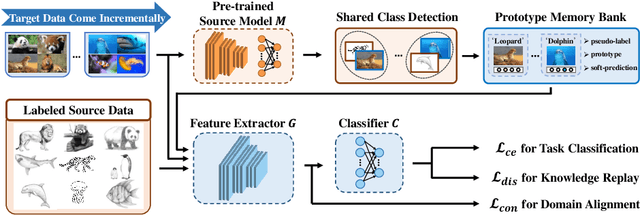

This paper studies a new, practical but challenging problem, called Class-Incremental Unsupervised Domain Adaptation (CI-UDA), where the labeled source domain contains all classes, but the classes in the unlabeled target domain increase sequentially. This problem is challenging due to two difficulties. First, source and target label sets are inconsistent at each time step, which makes it difficult to conduct accurate domain alignment. Second, previous target classes are unavailable in the current step, resulting in the forgetting of previous knowledge. To address this problem, we propose a novel Prototype-guided Continual Adaptation (ProCA) method, consisting of two solution strategies. 1) Label prototype identification: we identify target label prototypes by detecting shared classes with cumulative prediction probabilities of target samples. 2) Prototype-based alignment and replay: based on the identified label prototypes, we align both domains and enforce the model to retain previous knowledge. With these two strategies, ProCA is able to adapt the source model to a class-incremental unlabeled target domain effectively. Extensive experiments demonstrate the effectiveness and superiority of ProCA in resolving CI-UDA. The source code is available at https://github.com/Hongbin98/ProCA.git
Improved Knowledge Distillation via Adversarial Collaboration
Nov 29, 2021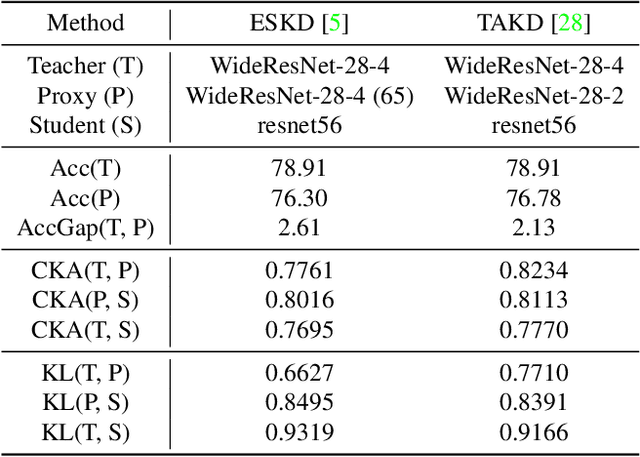
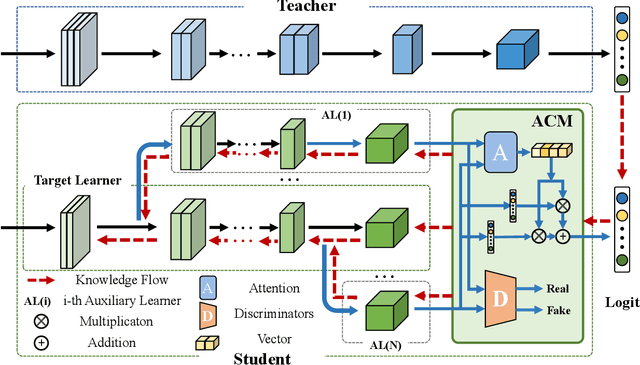
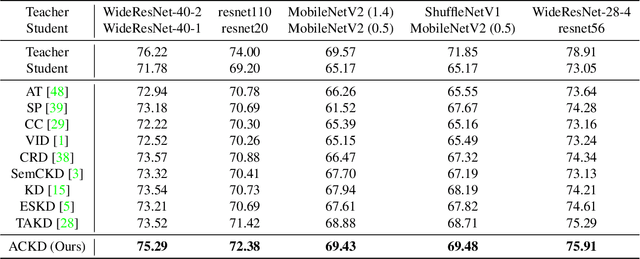
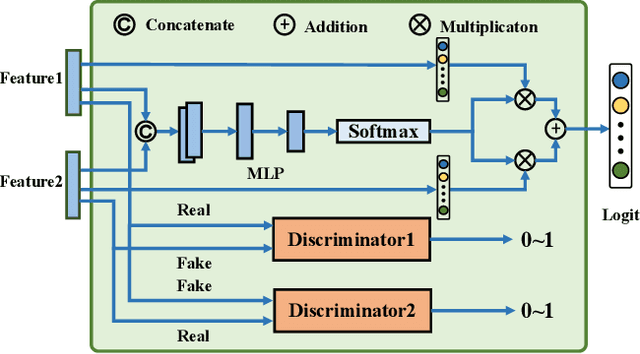
Knowledge distillation has become an important approach to obtain a compact yet effective model. To achieve this goal, a small student model is trained to exploit the knowledge of a large well-trained teacher model. However, due to the capacity gap between the teacher and the student, the student's performance is hard to reach the level of the teacher. Regarding this issue, existing methods propose to reduce the difficulty of the teacher's knowledge via a proxy way. We argue that these proxy-based methods overlook the knowledge loss of the teacher, which may cause the student to encounter capacity bottlenecks. In this paper, we alleviate the capacity gap problem from a new perspective with the purpose of averting knowledge loss. Instead of sacrificing part of the teacher's knowledge, we propose to build a more powerful student via adversarial collaborative learning. To this end, we further propose an Adversarial Collaborative Knowledge Distillation (ACKD) method that effectively improves the performance of knowledge distillation. Specifically, we construct the student model with multiple auxiliary learners. Meanwhile, we devise an adversarial collaborative module (ACM) that introduces attention mechanism and adversarial learning to enhance the capacity of the student. Extensive experiments on four classification tasks show the superiority of the proposed ACKD.
Semi-Online Knowledge Distillation
Nov 23, 2021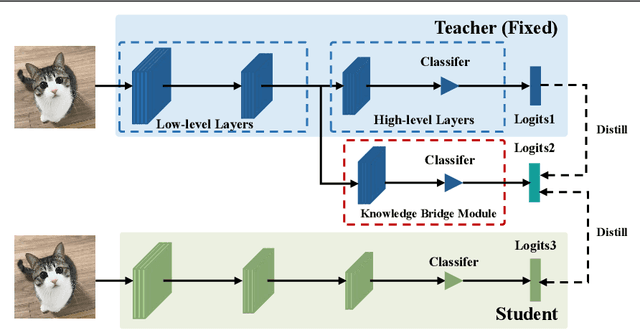
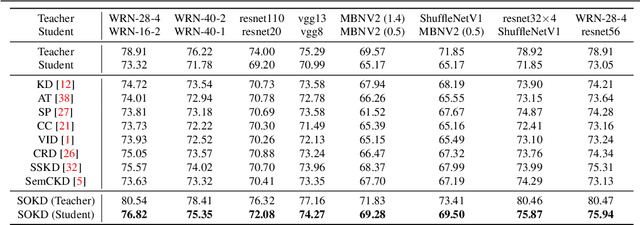


Knowledge distillation is an effective and stable method for model compression via knowledge transfer. Conventional knowledge distillation (KD) is to transfer knowledge from a large and well pre-trained teacher network to a small student network, which is a one-way process. Recently, deep mutual learning (DML) has been proposed to help student networks learn collaboratively and simultaneously. However, to the best of our knowledge, KD and DML have never been jointly explored in a unified framework to solve the knowledge distillation problem. In this paper, we investigate that the teacher model supports more trustworthy supervision signals in KD, while the student captures more similar behaviors from the teacher in DML. Based on these observations, we first propose to combine KD with DML in a unified framework. Furthermore, we propose a Semi-Online Knowledge Distillation (SOKD) method that effectively improves the performance of the student and the teacher. In this method, we introduce the peer-teaching training fashion in DML in order to alleviate the student's imitation difficulty, and also leverage the supervision signals provided by the well-trained teacher in KD. Besides, we also show our framework can be easily extended to feature-based distillation methods. Extensive experiments on CIFAR-100 and ImageNet datasets demonstrate the proposed method achieves state-of-the-art performance.
Source-free Domain Adaptation via Avatar Prototype Generation and Adaptation
Jun 18, 2021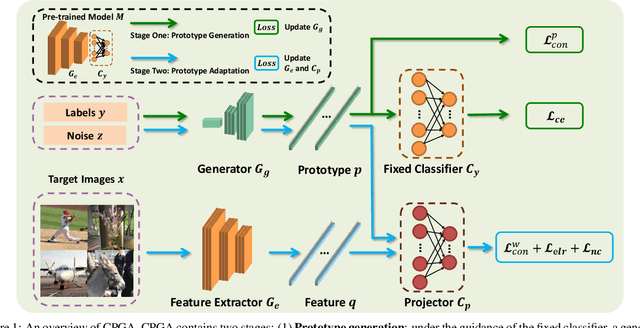
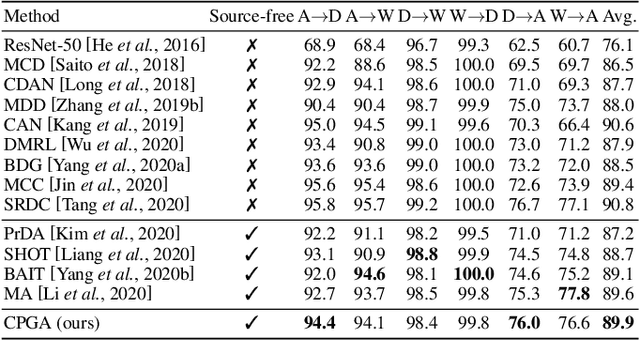
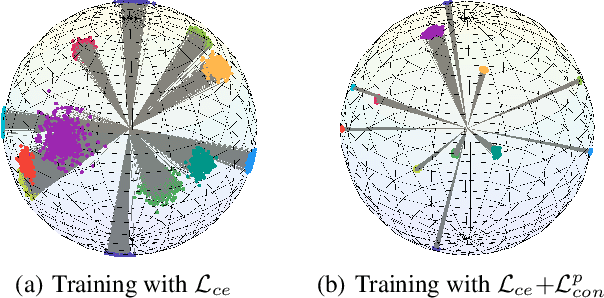
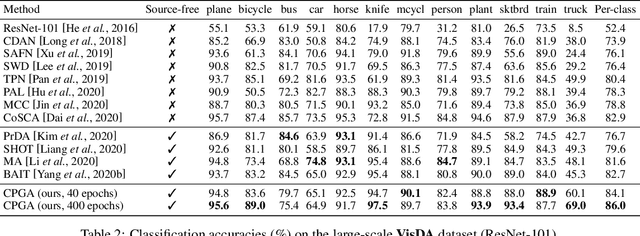
We study a practical domain adaptation task, called source-free unsupervised domain adaptation (UDA) problem, in which we cannot access source domain data due to data privacy issues but only a pre-trained source model and unlabeled target data are available. This task, however, is very difficult due to one key challenge: the lack of source data and target domain labels makes model adaptation very challenging. To address this, we propose to mine the hidden knowledge in the source model and exploit it to generate source avatar prototypes (i.e., representative features for each source class) as well as target pseudo labels for domain alignment. To this end, we propose a Contrastive Prototype Generation and Adaptation (CPGA) method. Specifically, CPGA consists of two stages: (1) prototype generation: by exploring the classification boundary information of the source model, we train a prototype generator to generate avatar prototypes via contrastive learning. (2) prototype adaptation: based on the generated source prototypes and target pseudo labels, we develop a new robust contrastive prototype adaptation strategy to align each pseudo-labeled target data to the corresponding source prototypes. Extensive experiments on three UDA benchmark datasets demonstrate the effectiveness and superiority of the proposed method.
Retinal Image Segmentation with a Structure-Texture Demixing Network
Jul 15, 2020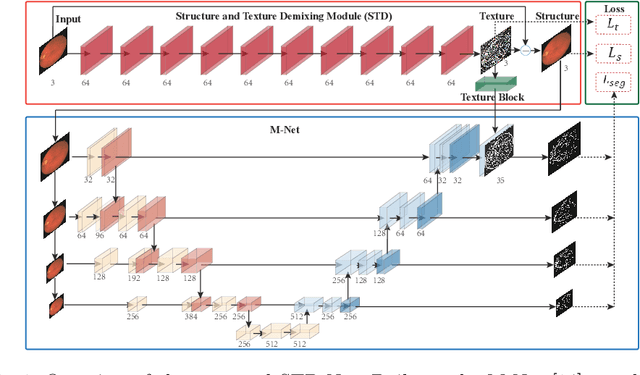
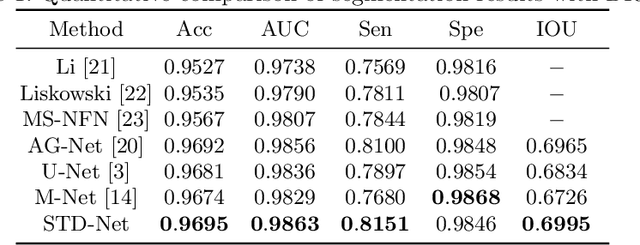
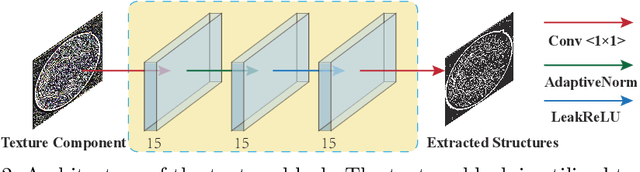
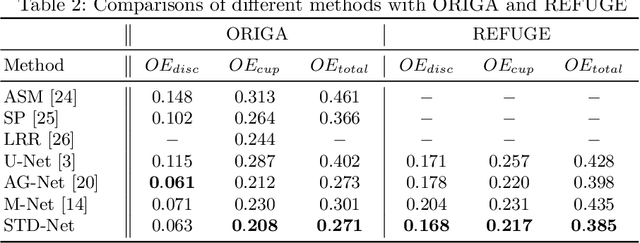
Retinal image segmentation plays an important role in automatic disease diagnosis. This task is very challenging because the complex structure and texture information are mixed in a retinal image, and distinguishing the information is difficult. Existing methods handle texture and structure jointly, which may lead biased models toward recognizing textures and thus results in inferior segmentation performance. To address it, we propose a segmentation strategy that seeks to separate structure and texture components and significantly improve the performance. To this end, we design a structure-texture demixing network (STD-Net) that can process structures and textures differently and better. Extensive experiments on two retinal image segmentation tasks (i.e., blood vessel segmentation, optic disc and cup segmentation) demonstrate the effectiveness of the proposed method.