 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemi-Online Knowledge Distillation
Paper and Code
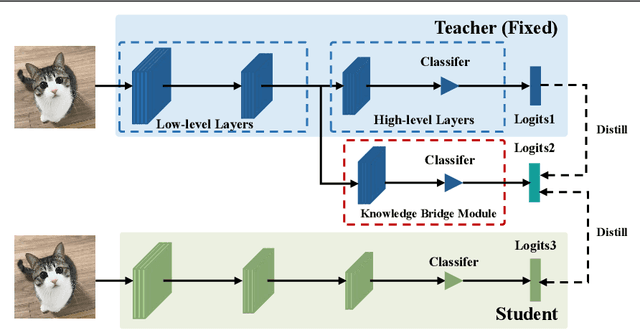
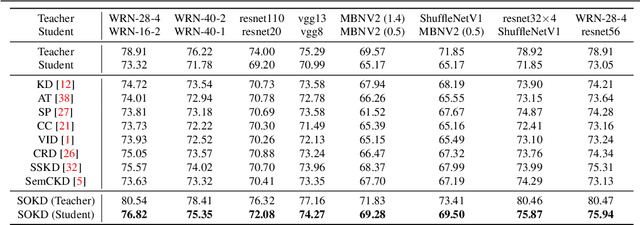


Knowledge distillation is an effective and stable method for model compression via knowledge transfer. Conventional knowledge distillation (KD) is to transfer knowledge from a large and well pre-trained teacher network to a small student network, which is a one-way process. Recently, deep mutual learning (DML) has been proposed to help student networks learn collaboratively and simultaneously. However, to the best of our knowledge, KD and DML have never been jointly explored in a unified framework to solve the knowledge distillation problem. In this paper, we investigate that the teacher model supports more trustworthy supervision signals in KD, while the student captures more similar behaviors from the teacher in DML. Based on these observations, we first propose to combine KD with DML in a unified framework. Furthermore, we propose a Semi-Online Knowledge Distillation (SOKD) method that effectively improves the performance of the student and the teacher. In this method, we introduce the peer-teaching training fashion in DML in order to alleviate the student's imitation difficulty, and also leverage the supervision signals provided by the well-trained teacher in KD. Besides, we also show our framework can be easily extended to feature-based distillation methods. Extensive experiments on CIFAR-100 and ImageNet datasets demonstrate the proposed method achieves state-of-the-art performance.