 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeObjEmbed: Towards Universal Multimodal Object Embeddings
Feb 03, 2026Aligning objects with corresponding textual descriptions is a fundamental challenge and a realistic requirement in vision-language understanding. While recent multimodal embedding models excel at global image-text alignment, they often struggle with fine-grained alignment between image regions and specific phrases. In this work, we present ObjEmbed, a novel MLLM embedding model that decomposes the input image into multiple regional embeddings, each corresponding to an individual object, along with global embeddings. It supports a wide range of visual understanding tasks like visual grounding, local image retrieval, and global image retrieval. ObjEmbed enjoys three key properties: (1) Object-Oriented Representation: It captures both semantic and spatial aspects of objects by generating two complementary embeddings for each region: an object embedding for semantic matching and an IoU embedding that predicts localization quality. The final object matching score combines semantic similarity with the predicted IoU, enabling more accurate retrieval. (2) Versatility: It seamlessly handles both region-level and image-level tasks. (3) Efficient Encoding: All objects in an image, along with the full image, are encoded in a single forward pass for high efficiency. Superior performance on 18 diverse benchmarks demonstrates its strong semantic discrimination.
WeDetect: Fast Open-Vocabulary Object Detection as Retrieval
Dec 13, 2025Open-vocabulary object detection aims to detect arbitrary classes via text prompts. Methods without cross-modal fusion layers (non-fusion) offer faster inference by treating recognition as a retrieval problem, \ie, matching regions to text queries in a shared embedding space. In this work, we fully explore this retrieval philosophy and demonstrate its unique advantages in efficiency and versatility through a model family named WeDetect: (1) State-of-the-art performance. WeDetect is a real-time detector with a dual-tower architecture. We show that, with well-curated data and full training, the non-fusion WeDetect surpasses other fusion models and establishes a strong open-vocabulary foundation. (2) Fast backtrack of historical data. WeDetect-Uni is a universal proposal generator based on WeDetect. We freeze the entire detector and only finetune an objectness prompt to retrieve generic object proposals across categories. Importantly, the proposal embeddings are class-specific and enable a new application, object retrieval, supporting retrieval objects in historical data. (3) Integration with LMMs for referring expression comprehension (REC). We further propose WeDetect-Ref, an LMM-based object classifier to handle complex referring expressions, which retrieves target objects from the proposal list extracted by WeDetect-Uni. It discards next-token prediction and classifies objects in a single forward pass. Together, the WeDetect family unifies detection, proposal generation, object retrieval, and REC under a coherent retrieval framework, achieving state-of-the-art performance across 15 benchmarks with high inference efficiency.
Spatial-Semantic Collaborative Cropping for User Generated Content
Jan 16, 2024A large amount of User Generated Content (UGC) is uploaded to the Internet daily and displayed to people world-widely through the client side (e.g., mobile and PC). This requires the cropping algorithms to produce the aesthetic thumbnail within a specific aspect ratio on different devices. However, existing image cropping works mainly focus on landmark or landscape images, which fail to model the relations among the multi-objects with the complex background in UGC. Besides, previous methods merely consider the aesthetics of the cropped images while ignoring the content integrity, which is crucial for UGC cropping. In this paper, we propose a Spatial-Semantic Collaborative cropping network (S2CNet) for arbitrary user generated content accompanied by a new cropping benchmark. Specifically, we first mine the visual genes of the potential objects. Then, the suggested adaptive attention graph recasts this task as a procedure of information association over visual nodes. The underlying spatial and semantic relations are ultimately centralized to the crop candidate through differentiable message passing, which helps our network efficiently to preserve both the aesthetics and the content integrity. Extensive experiments on the proposed UGCrop5K and other public datasets demonstrate the superiority of our approach over state-of-the-art counterparts. Our project is available at https://github.com/suyukun666/S2CNet.
DI-Net : Decomposed Implicit Garment Transfer Network for Digital Clothed 3D Human
Nov 28, 2023

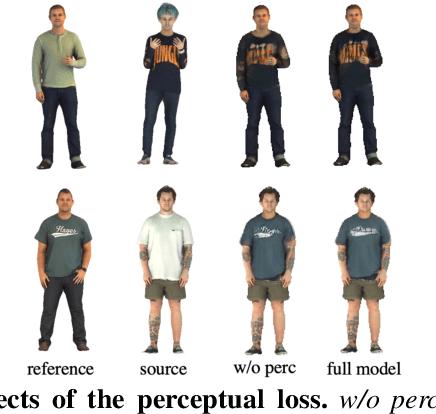

3D virtual try-on enjoys many potential applications and hence has attracted wide attention. However, it remains a challenging task that has not been adequately solved. Existing 2D virtual try-on methods cannot be directly extended to 3D since they lack the ability to perceive the depth of each pixel. Besides, 3D virtual try-on approaches are mostly built on the fixed topological structure and with heavy computation. To deal with these problems, we propose a Decomposed Implicit garment transfer network (DI-Net), which can effortlessly reconstruct a 3D human mesh with the newly try-on result and preserve the texture from an arbitrary perspective. Specifically, DI-Net consists of two modules: 1) A complementary warping module that warps the reference image to have the same pose as the source image through dense correspondence learning and sparse flow learning; 2) A geometry-aware decomposed transfer module that decomposes the garment transfer into image layout based transfer and texture based transfer, achieving surface and texture reconstruction by constructing pixel-aligned implicit functions. Experimental results show the effectiveness and superiority of our method in the 3D virtual try-on task, which can yield more high-quality results over other existing methods.
COMNet: Co-Occurrent Matching for Weakly Supervised Semantic Segmentation
Sep 29, 2023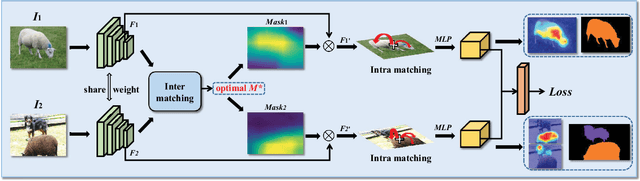
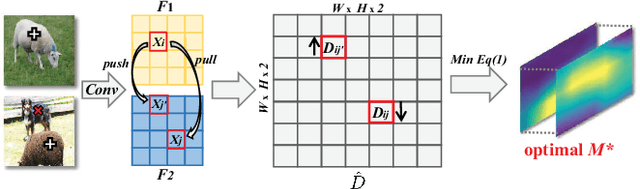
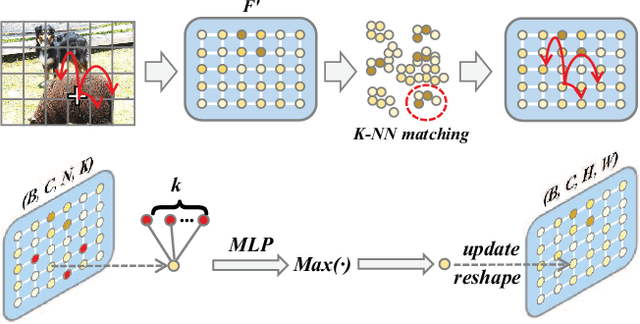
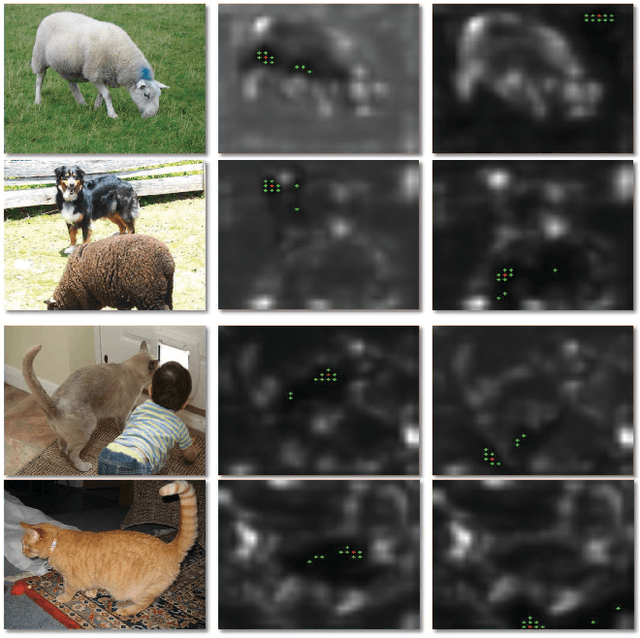
Image-level weakly supervised semantic segmentation is a challenging task that has been deeply studied in recent years. Most of the common solutions exploit class activation map (CAM) to locate object regions. However, such response maps generated by the classification network usually focus on discriminative object parts. In this paper, we propose a novel Co-Occurrent Matching Network (COMNet), which can promote the quality of the CAMs and enforce the network to pay attention to the entire parts of objects. Specifically, we perform inter-matching on paired images that contain common classes to enhance the corresponded areas, and construct intra-matching on a single image to propagate the semantic features across the object regions. The experiments on the Pascal VOC 2012 and MS-COCO datasets show that our network can effectively boost the performance of the baseline model and achieve new state-of-the-art performance.
Semantic-Constraint Matching Transformer for Weakly Supervised Object Localization
Sep 04, 2023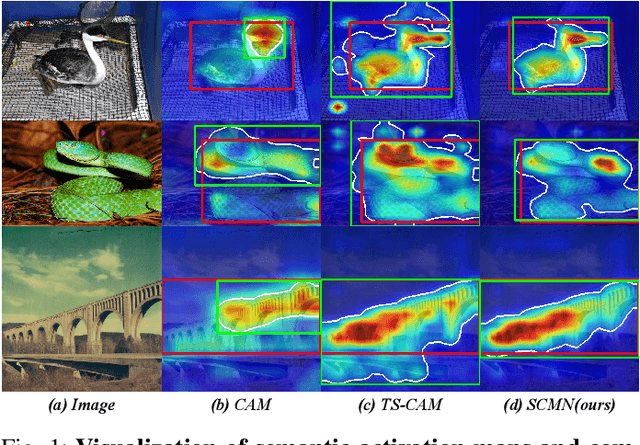

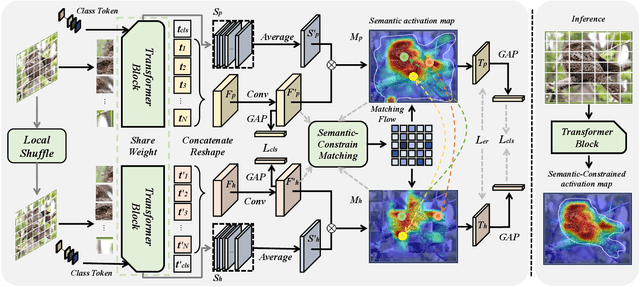
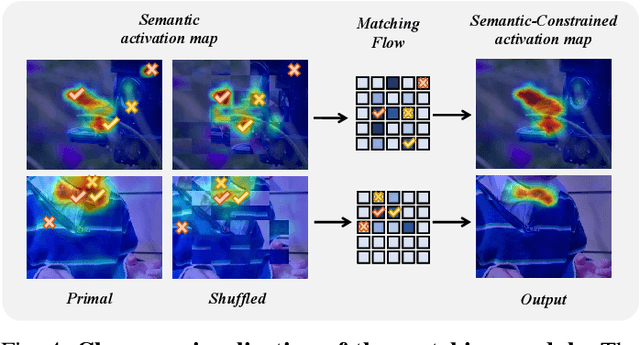
Weakly supervised object localization (WSOL) strives to learn to localize objects with only image-level supervision. Due to the local receptive fields generated by convolution operations, previous CNN-based methods suffer from partial activation issues, concentrating on the object's discriminative part instead of the entire entity scope. Benefiting from the capability of the self-attention mechanism to acquire long-range feature dependencies, Vision Transformer has been recently applied to alleviate the local activation drawbacks. However, since the transformer lacks the inductive localization bias that are inherent in CNNs, it may cause a divergent activation problem resulting in an uncertain distinction between foreground and background. In this work, we proposed a novel Semantic-Constraint Matching Network (SCMN) via a transformer to converge on the divergent activation. Specifically, we first propose a local patch shuffle strategy to construct the image pairs, disrupting local patches while guaranteeing global consistency. The paired images that contain the common object in spatial are then fed into the Siamese network encoder. We further design a semantic-constraint matching module, which aims to mine the co-object part by matching the coarse class activation maps (CAMs) extracted from the pair images, thus implicitly guiding and calibrating the transformer network to alleviate the divergent activation. Extensive experimental results conducted on two challenging benchmarks, including CUB-200-2011 and ILSVRC datasets show that our method can achieve the new state-of-the-art performance and outperform the previous method by a large margin.
Occlusion-Aware Detection and Re-ID Calibrated Network for Multi-Object Tracking
Aug 30, 2023Multi-Object Tracking (MOT) is a crucial computer vision task that aims to predict the bounding boxes and identities of objects simultaneously. While state-of-the-art methods have made remarkable progress by jointly optimizing the multi-task problems of detection and Re-ID feature learning, yet, few approaches explore to tackle the occlusion issue, which is a long-standing challenge in the MOT field. Generally, occluded objects may hinder the detector from estimating the bounding boxes, resulting in fragmented trajectories. And the learned occluded Re-ID embeddings are less distinct since they contain interferer. To this end, we propose an occlusion-aware detection and Re-ID calibrated network for multi-object tracking, termed as ORCTrack. Specifically, we propose an Occlusion-Aware Attention (OAA) module in the detector that highlights the object features while suppressing the occluded background regions. OAA can serve as a modulator that enhances the detector for some potentially occluded objects. Furthermore, we design a Re-ID embedding matching block based on the optimal transport problem, which focuses on enhancing and calibrating the Re-ID representations through different adjacent frames complementarily. To validate the effectiveness of the proposed method, extensive experiments are conducted on two challenging VisDrone2021-MOT and KITTI benchmarks. Experimental evaluations demonstrate the superiority of our approach, which can achieve new state-of-the-art performance and enjoy high run-time efficiency.
AIoT-Based Drum Transcription Robot using Convolutional Neural Networks
Aug 29, 2023With the development of information technology, robot technology has made great progress in various fields. These new technologies enable robots to be used in industry, agriculture, education and other aspects. In this paper, we propose a drum robot that can automatically complete music transcription in real-time, which is based on AIoT and fog computing technology. Specifically, this drum robot system consists of a cloud node for data storage, edge nodes for real-time computing, and data-oriented execution application nodes. In order to analyze drumming music and realize drum transcription, we further propose a light-weight convolutional neural network model to classify drums, which can be more effectively deployed in terminal devices for fast edge calculations. The experimental results show that the proposed system can achieve more competitive performance and enjoy a variety of smart applications and services.
Improving Video Violence Recognition with Human Interaction Learning on 3D Skeleton Point Clouds
Aug 26, 2023



Deep learning has proved to be very effective in video action recognition. Video violence recognition attempts to learn the human multi-dynamic behaviours in more complex scenarios. In this work, we develop a method for video violence recognition from a new perspective of skeleton points. Unlike the previous works, we first formulate 3D skeleton point clouds from human skeleton sequences extracted from videos and then perform interaction learning on these 3D skeleton point clouds. Specifically, we propose two types of Skeleton Points Interaction Learning (SPIL) strategies: (i) Local-SPIL: by constructing a specific weight distribution strategy between local regional points, Local-SPIL aims to selectively focus on the most relevant parts of them based on their features and spatial-temporal position information. In order to capture diverse types of relation information, a multi-head mechanism is designed to aggregate different features from independent heads to jointly handle different types of relationships between points. (ii) Global-SPIL: to better learn and refine the features of the unordered and unstructured skeleton points, Global-SPIL employs the self-attention layer that operates directly on the sampled points, which can help to make the output more permutation-invariant and well-suited for our task. Extensive experimental results validate the effectiveness of our approach and show that our model outperforms the existing networks and achieves new state-of-the-art performance on video violence datasets.
Dual Progressive Transformations for Weakly Supervised Semantic Segmentation
Sep 30, 2022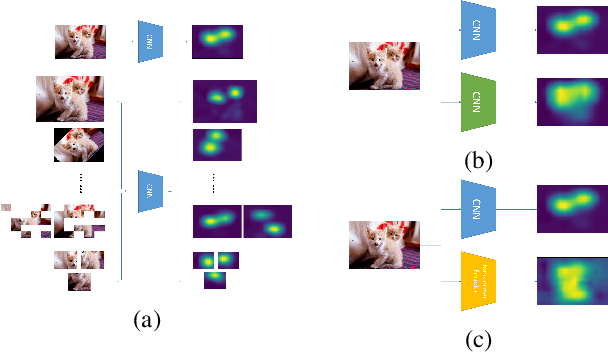
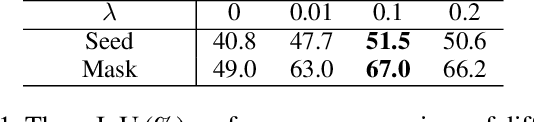

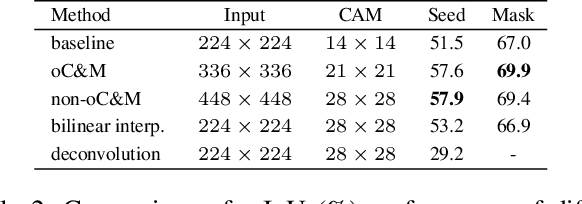
Weakly supervised semantic segmentation (WSSS), which aims to mine the object regions by merely using class-level labels, is a challenging task in computer vision. The current state-of-the-art CNN-based methods usually adopt Class-Activation-Maps (CAMs) to highlight the potential areas of the object, however, they may suffer from the part-activated issues. To this end, we try an early attempt to explore the global feature attention mechanism of vision transformer in WSSS task. However, since the transformer lacks the inductive bias as in CNN models, it can not boost the performance directly and may yield the over-activated problems. To tackle these drawbacks, we propose a Convolutional Neural Networks Refined Transformer (CRT) to mine a globally complete and locally accurate class activation maps in this paper. To validate the effectiveness of our proposed method, extensive experiments are conducted on PASCAL VOC 2012 and CUB-200-2011 datasets. Experimental evaluations show that our proposed CRT achieves the new state-of-the-art performance on both the weakly supervised semantic segmentation task the weakly supervised object localization task, which outperform others by a large margin.